1.LDA分析思路
本Benchmark 的分析围绕加速目的,每个热点函数按照下面几个部分展开:
#耗时分析(潜在加速片段)
##耗时区域(高密度循环体 和 函数调用高频循环体)
##耗时原因(量化指标)
#功能分析
##热点区域
(input, process, output)
##跨区域关系
(数据流动:生产-消费路径)
#加速分析
##有无加速机会
##加速模式
2.热点区域分析
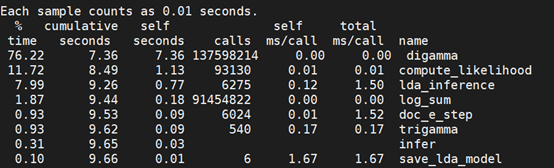
且各函数中循环执行次数(执行次数为上层循环/函数执行一次 对应循环的执行次数)见下表:

lda_inference 是父函数,调用了compute_likelihood和digamma两个子函数,先从父函数分析(digamma在lda_inference函数中分析)
#函数1 lda_inference & 函数2 digamma
/* 1.lda_inference */
//循环1 调用了digamma函数
//model->num_topics=3
for (k = 0; k < model->num_topics; k++)
{
var_gamma[k] = model->alpha + (doc->total/((double) model->num_topics));
digamma_gam[k] = digamma(var_gamma[k]);
for (n = 0; n < doc->length; n++)
phi[n][k] = 1.0/model->num_topics;
}
var_iter = 0;
//循环2 外层调用了compute_likelihood函数,内层调用了digamma函数
//while循环次数 [9,20] model->num_topics [190,600]
while ((converged > VAR_CONVERGED) &&((var_iter < VAR_MAX_ITER) || (VAR_MAX_ITER == -1)))
{
var_iter++;
for (n = 0; n < doc->length; n++)
{
phisum = 0;
for (k = 0; k < model->num_topics; k++)
{
oldphi[k] = phi[n][k];
phi[n][k] =digamma_gam[k] + model->log_prob_w[k][doc->words[n]];
if (k > 0)
phisum = log_sum(phisum, phi[n][k]);
else
phisum = phi[n][k]; // note, phi is in log space
}
for (k = 0; k < model->num_topics; k++)
{
phi[n][k] = exp(phi[n][k] - phisum);
var_gamma[k] =var_gamma[k] + doc->counts[n]*(phi[n][k] - oldphi[k]);
digamma_gam[k] = digamma(var_gamma[k]);
}
}
likelihood = compute_likelihood(doc, model, phi, var_gamma);
...
}
return(likelihood);
}
/* 2.digamma */
double digamma(double x)
{
double p;
x=x+6;
p=1/(x*x);
p=(((0.004166666666667*p-70.003968253986254)*p+0.008333333333333)*p-0.083333333333333)*p;
p=p+log(x)-0.5/x-1/(x-1)-1/(x-2)-1/(x-3)-1/(x-4)-1/(x-5)-1/(x-6);
return p;
}
##耗时分析
热点代码片段可以分为两类:
Loop:高密度循环体(没有函数调用或者占比很小)
Loop=f:热点函数高频调用循环体
F-2-1-1(23-32行)
此循环为高密度循环体,是lda_inference函数自身执行时间主要来源。循环内计算执行次数较高,且计算复杂(VTune工具得到相同结果)
F-2-1-2=digamma(34-41行)
此循环为热点函数高频调用循环体,最耗时函数digamma(52-60行)99%调用比例在此循环中。
需讨论:为什么调用函数中,digamma最耗时?
现象1:exp()函数被调用次数,与digamma(133568104)相当;log_sum函数被调用次数约为digamma的2/3。
但是exp()和log_sum()函数的占用时间较digamma(76.22%)极低,log_sum 执行时间只占到了1.4%。
现象2:在同一个循环内,digamma执行时间占比远远高于lda_inference高密度循环体F-2-1-1(23-32行)
现象3:调用次数仅534次的trigamma函数时间占用比例却达到1.29%。
解释:
对比了上述函数/循环体中的指令,有如下:
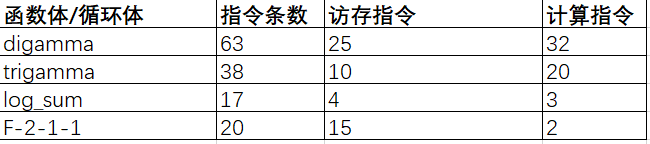
digamma函数较于log_sum函数和F-2-1-1循环体,在计算和访存指令数量上较高,一定程度上解释了:调用次数相当,但执行时间差别大的原因。
##功能分析
(1)F-2-1-1(23-32行)
input: (i1)phi[n][k]、(i2)digamma_gam[k]、(i3)model->log_prob_w[k][doc->words[n]]、(i4)phisum
process1: 矩阵运算,i1(k=0) /o2 -> o1
process2: 矩阵运算,i2、i3 -> o2
process3: (if) 调用log_sum, o2、i4 (k=0) /o3 -> o3
process4: (else) 矩阵运算, o2 -> o3
output: (o1)oldphi[k]、(o2)phi[n][k]、(o3)phisum
(2)F-2-1-2=digamma (34-41行)
input: (i1)phi[n][k]、(i2)phisum、(i3)var_gamma[k]、(i4)doc->counts[n]、 (i5)oldphi[k]
process1: 指数运算, i1(k=0)/o1 、i2 -> o1
process2: 矩阵运算, i3、i4、i5、o1 -> o2
process3: 调用digamma, o2 -> o3
output: (o1)phi[n][k]、(o2)var_gamma[k]、(o3)digamma_gam[k]
(3)跨循环关系
仅讨论热点循环间有传递的集合数据。
phi[n][k]
生产:process2 (F-2-1-1) -> 消费:process1 (F-2-1-2,1次) -> 生产:process1 (F-2-1-2) -> 消费:process1 (F-2-1-1,1次)
oldphi[k]
生产:process1 (F-2-1-1) -> 消费:process2 (F-2-1-2)
phisum
生产:process3 (F-2-1-1) / process4 (F-2-1-1) -> 消费:process1 (F-2-1-2)
digamma_gam[k]
生产:(F-1) -> 消费:process2 (F-2-1-1,3次) -> 生产:process3 (F-2-1-2) -> 消费:process2 (F-2-1-1)
(4)跨函数关系
phi[n][k]: F1(lda_inference) -> F3(compute_likelihood)
生产:process1 (F1-2-1-2) -> 消费:process1 (F3-2-1)
##加速分析
(1)加速机会
可以加速,但加速空间有限:
F-2-1-1与F-2-1-2不可以同时并行加速,耦合过强(主要来自phi[n][k])
F-2-1-1的process2为主计算,数据之间没有依赖,单独可以加速。
F-2-1-2的process3为加速重点,数据依赖于前面的计算,但可以加速。
(2)加速模式
F-2-1-1
对主计算process2可以采用全并行,其input数据对循环内其他计算没有依赖;若针对所有计算需进行流水线加速,process1和process3、4对process2有依赖。
F-2-1-2
需对整个循环内计算采用流水线加速,因为计算之间相互依赖;以达到加速主计算process3的目的。
#函数3 compute likelihood
/* 3.compute likelihood */
//循环1 调用了digamma函数,但是执行次数少
//model->num_topics = 3
for (k = 0; k < model->num_topics; k++)
{
dig[k] = digamma(var_gamma[k]);
var_gamma_sum += var_gamma[k];
}
digsum = digamma(var_gamma_sum);
likelihood =lgamma(model->alpha * model -> num_topics)- model -> num_topics * lgamma(model->alpha)- (lgamma(var_gamma_sum));
//循环2 耗时分析
//model->num_topics = 3
for (k = 0; k < model->num_topics; k++)
{
likelihood +=(model->alpha - 1)*(dig[k] - digsum) + lgamma(var_gamma[k])- (var_gamma[k] - 1)*(dig[k] - digsum);
for (n = 0; n < doc->length; n++)
{
if (phi[n][k] > 0)
{
likelihood += doc->counts[n]*(phi[n][k]*((dig[k] - digsum) - log(phi[n][k])+ model->log_prob_w[k][doc->words[n]]));
}
}
}
##耗时分析
F-2-1(21-27行)为本函数的高密度循环体,较其他循环,执行次数高;(工具VTune验证了分析结果)
##功能分析
(1)F-2-1(21-27行)
input: (i1)likelihood、(i2)doc->counts[n]、(i3)phi[n][k]、(i4)dig[k]、 (i5)digsum、(i6)phi[n][k]、(i7)model->log_prob_w[k][doc->words[n]]
process1: 矩阵运算, i1 、i2、 i3 、i4、 i5 、i6、 i7 -> o1
output: (o1)likelihood
(2)跨循环关系
likelihood(关系到加速)
生产:process1 (F2-2-1) -> 消费:process1 (F2-2,1次) -> 生产:process1 (F2-2) -> 消费:process1 (F2-2-1)
(3)跨函数关系
phi[n][k]: F1(lda_inference) -> F3(compute_likelihood)
生产:process1 (F1-2-1-2) -> 消费:process1 (F2-2-1)
##加速分析
(1)加速机会
可以加速
此循环仅1条计算,此条计算加工的数据相互之间没有依赖,迭代间不存在依赖。
likelihood的存在使得计算具有树状依赖;内层循环结束后有一次计算依赖(影响数据存储,但不影响加速)。但input数据中有许多结构体指针数据,会影响取数据。
(2)加速模式
树状依赖应该采用树状加速
