1.热点分析
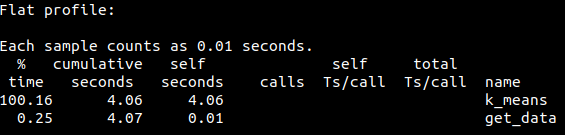
1.1热点函数
1.2热点循环
格式说明: 热点循环-各层执行总次数
执行百分比:热点循环占本函数执行比例
函数: k_means
km.L1.1.1.1 (1-40-400000-4000000-2992000000)
执行百分比:92.5%
km.L1.1.2 (1-40-400000-4000000-299200000)
执行百分比:6.4%
1.3 热点代码
/* k_means */
// km.L1
do
{
for (h = 0; h < n; h++)
{
// km.L1.1.1
for (i = 0; i < k; i++)
{
// km.L1.1.1.1
for (j = m; j-- > 0;)
{
distance += pow(data[h][j] - c[i][j], 2);
}
}
// km.L1.1.2
for (j = m; j-- > 0;)
{
c1[labels[h]][j] += data[h][j];
}
...
}
} while (fabs(error - old_error) > t);
2.功能分析
2.1数据标签

说明:s,v,m,t(全局数据)km-(局部数据)
2.2数据流分析
函数 k_means
km.L1.1.1.1(9-12行)
P1: (km.m1[i][],km.m2[i][]),km.s1 -> km.s1 幂运算
km.L1.1.2(14-17行)
P2: km.m1[i][],km.m3[i][] -> km.m3[i][];加法树
3.加速分析
