深度学习训练和推理的过程中,会涉及到大量的向量(vector),矩阵(matrix)和张量(tensor)操作,通常需要大量的浮点计算,包括高精度(在训练的时候)和低精度(在推理和部署的时候)。
GPU,作为一种通用可编程的加速器,最初设计是用来进行图形处理和渲染功能,但是从2007年开始,英伟达(NVIDIA)公司提出了第一个可编程通用计算平台(GPU),同时提出了CUDA框架,从此开启了GPU用于通用计算的新纪元。GPU加速已经是各类工具实现的基本底层构架之一。
异构计算:
异构计算是基于一个更加朴素的概念,”异构现象“,也就是不同计算平台之间,由于硬件结构(包括计算核心和内存),指令集和底层软件实现等方面的不同而有着不同的特性。异构计算就是使用结合了两个或者多个不同的计算平台,并进行协同运算。比如,比较常见的,在深度学习和机器学习中已经比较成熟的架构:CPU和GPU的异构计算。
GPU的概念:(Graphical Processing Unit)
GPU,就如名字所包含的内容,原本开发的目的是为了进行计算机图形渲染,而减少对于CPU的负载。由于图像的原始特性,也就是像素间的独立性,所以GPU在设计的时候就遵从了“单指令流多数据流(SIMD)”架构,使得同一个指令(比如图像的某种变换),可以同时在多一个像素点上进行计算,从而得到比较大的吞吐量,才能使得计算机可以实时渲染比较复杂的2D/3D场景。后来NVIDA推出了CUDA通用计算平台,使得GPU可以进行大规模计算。
GPU的架构:
GPU与CPU的不同特性:
1.计算核心
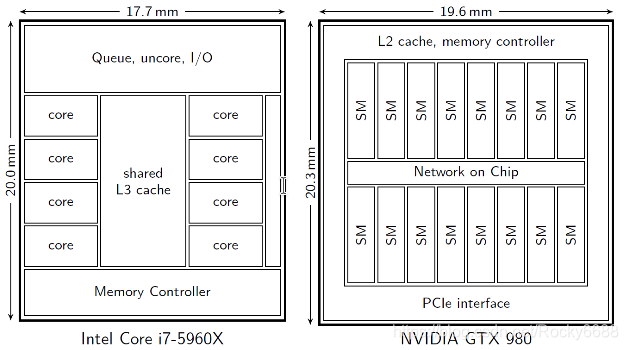
图中的CPU,i7-5960,Intel的第五代Broadwell架构,其中包括了8个CPU核心(支持16线程),也就是理论上可以有16个不同的运算同时进行。除了8个核心计算单元,大部分的芯片面积是被3级缓存,内存和控制电路占据了。同样的,来自Nvidia的GTX980GPU,在差不多的芯片面积上,大部分是计算单元,16个SM,也就是流处理单元,每个流处理单元中包含着128个CUDA计算核心,所以总共来说,有2048个GPU运算单元,相应地这颗GPU理论上可以在一个时钟周期内可以进行2048次单精度运算。GPU将更多的晶体管用在了计算,而不是数据缓存和流程控制。
2.计算核心频率
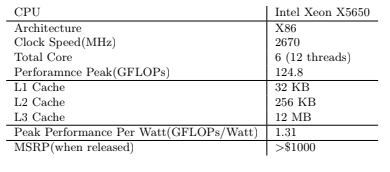
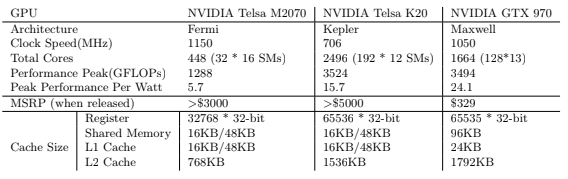
时钟频率,代表每一秒中内能进行同步脉冲次数,也是从一个侧面反映一个计算元件的工作速度。下图中对比了个别早期产品,比如Intel的x5650和几款Nvidia的GPU。可以看出核心频率而言,CPU要远高于GPU。对于CPU而言,在不考虑能源消耗和制程工艺限制的情况下,追求更高的主频。但,在GPU的设计中,采用了多核心设计,即使是提高一些频率,其实对于总体性能影像不会特别大。当然,其中还有能耗方面的考虑,避免发热过高,也进行了权衡。还有一个可能的原因是,在一个流处理器中的每个核心(CUDA核心)的运行共享非常有限的缓存和寄存器,由于共享内存也是有性能极限的,所以即使每个GPU核心频率提高,如果被缓存等拖累也是无法展现出高性能的。
3.内存架构
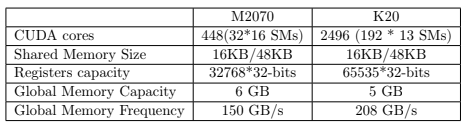
GPU的多层内存架构包括全局内存(也就是通常意义上大部分比较关注的内存,在若干到16GB之间,截至到当前最新),2级缓存,和芯片上的存储(包括寄存器,和1级缓存共用的共享内存,只读/纹理缓存和常量缓存)。通常来说,最高速的共享内存/缓存和寄存器都是非常有限的,比如在Tesla的K20中,只有48K的缓存可以作为共享内存或者1级缓存使用,所以在很多用GPU加速算法实现的过程中,有效地利用这些高速缓存是使得性能提升的非常重要的方面。
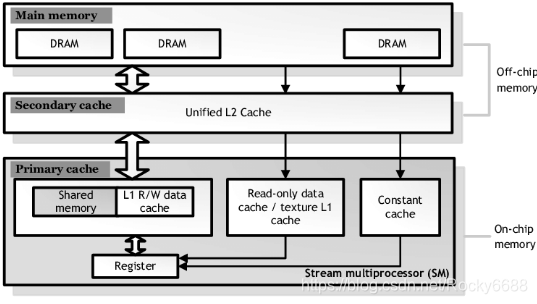
CUDA核心定义:
一个GPU芯片里,会很几千个CUDA核心,被分布在多个流处理单元(SM)中,比如上面提到早期的GTX980中的16个SM中各包含了128个CUDA核心。如下图所示,作为GPU架构中的最小单元,其实它的设计和CPU有着非常类似的结构,其中包括了一个浮点运算单元和整型运算单元,和控制单元。同一个流处理器中,所有的CUDA核心将同步执行同一个指令,但是作用于不同的数据点上。
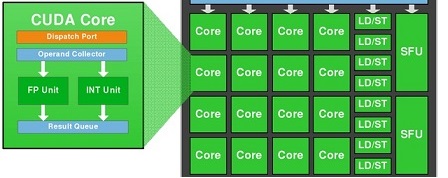
一般来说,更加多的CUDA核心意味着有更多的并行执行单元,所以也就可以片面地认为是有更加高的性能。但是,其实这个也是取决于很多方面,最重要的是算法在并行实现的时候有没有高效地调度和内存的使用优化。在现在我们使用的大部分GPU加速的深度学习框架里,包括Tensorflow,PyTorch等都是依赖于底层的GPU的矩阵加速代码的实现。为此Nvidia公司也是制定和实现了统一的接口,比如cuDNN,方便上层框架更好的利用GPU的性能。
使用GPU的好处:
对于并行计算来说,可以非常粗略地分为:
- 并行指令: 也就是多个指令可以同时分配到不同的计算核心上同时进行,而他们的操作是不同的,并且他们之间相互独立,不需要额外的同步和信息共享。
- 并行数据流: 如果数据本身存在的天然的独立性,比如图像中的每一个像素,那么在对这个图像做处理的过程中,同一个指令可以同时作用于每一个像素。在这种情况下,这个对于完整图像的操作可以并行化。理论上,如果内存不是问题,并且计算单元的数量大于整个图像中总像素点的话,这个操作可以在一个时钟周期内完成。
GPU整体的架构而言,某种意义上是同时支持以上两种并行模式。在同一个流处理器中,采用了“单一指令并行数据流的模式”,而在多个流处理器中,同一时间可以派发不同的指令。从这一点出发,GPU芯片算是一个非常灵活的架构。一个芯片中,流处理器的个数和其中包含的CUDA核心的数量也是一种面向应用设计时候找到的一个平衡点。
基于深度学习中大部分的操作的天然并行性(大量的矩阵操作),GPU在当下还是一种非常适合的计算平台。一个非常典型的例子就是常见的矩阵相乘(如下图),要计算Z = X×Y,通过并行计算,X和Y中的行向量和列向量的逐元素相乘就可以同时进行,只要得到结果后再进行累加,而且累加的过程中也是可以进行并行化,使得效率有非常大的提高。Nvidia也是制定和开发了一套底层类库,CUBlas方便开发者。我们熟悉的几大框架(e.g. Tensorflow, PyTorch等)也是遵循和使用了这些并行类库,所以才使得训练和部署性能有了非常多的提高。
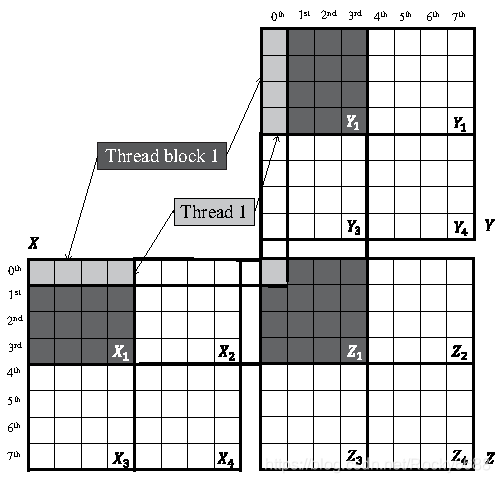
GPU的主要性能指标:
GPU的性能主要由以下三个参数构成:
- 计算能力。通常我们关心的是32位浮点计算能力。16位浮点训练也开始流行,如果只做预测的话也可以用8位整数。
- 内存大小。当模型越大,或者训练时的批量越大时,所需要的GPU内存就越多。
- 内存带宽。只有当内存带宽足够时才能充分发挥计算能力。
对于深度学习性能而言,最重要的特征是内存带宽(memory bandwidth)。 简而言之:GPU针对内存带宽进行了优化,但同时牺牲了内存访问时间(延迟)。CPU的设计恰恰相反:如果涉及少量内存(例如几个数字相乘(3 * 6 * 9)),CPU可以快速计算,但是对于大量内存(如矩阵乘法(A * B * C)则很慢。由于内存带宽的限制,当涉及大量内存的问题时,GPU快速计算的优势往往会受到限制。
硬件整机配置
所以如果你想购买一个快速的GPU,首先要关注的是GPU的带宽(bandwidth)。
对于大部分用户来说,只要考虑计算能力就可以了。GPU内存尽量不小于4GB。但如果GPU要同时显示图形界面,那么推荐的内存大小至少为6GB。内存带宽通常相对固定,选择空间较小。
下图描绘了GTX 900和1000系列里各个型号的32位浮点计算能力和价格的对比。
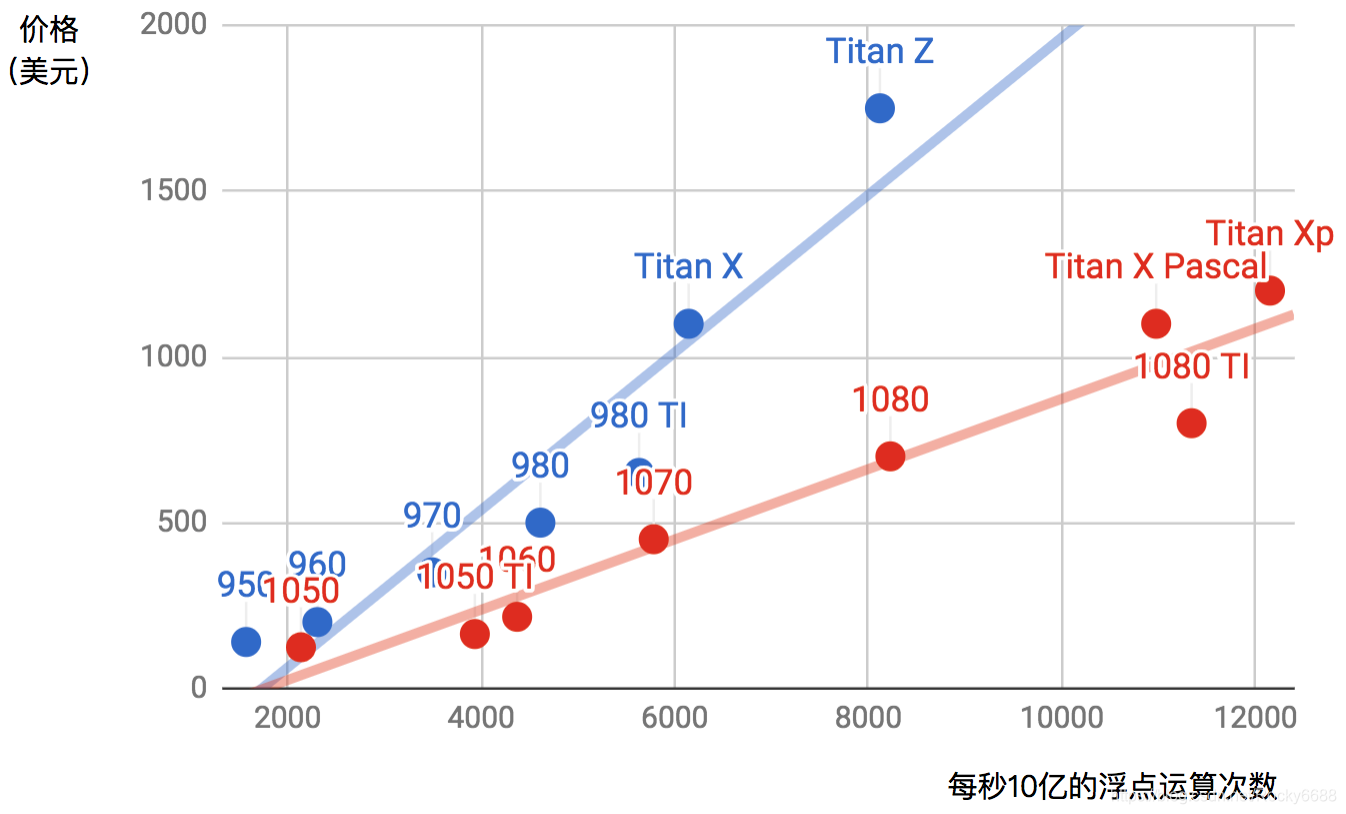
我们可以从图中读出两点信息:
- 在同一个系列里面,价格和性能大体上成正比。但后发布的型号性价比更高,例如980 TI和1080 TI。
- GTX 1000系列比900系列在性价比上高出2倍左右。
如果大家继续比较GTX较早的系列,也可以发现类似的规律。据此,我们推荐大家在能力范围内尽可能买较新的GPU。
性价比高但较贵:RTX 2070,GTX 1080 Ti
性价比高又便宜:RTX 2060,GTX 1060(6GB)(适合入门)
没有足够的钱:GTX 1060(6GB)
几乎没有钱,入门级:GTX 1050 Ti(4GB)
目前独立GPU主要有AMD和Nvidia两家厂商。其中Nvidia在深度学习布局较早,对深度学习框架支持更好。因此,目前大家主要会选择Nvidia的GPU。
Nvidia有面向个人用户(例如GTX系列)和企业用户(例如Tesla系列)的两类GPU。这两类GPU的计算能力相当。然而,面向企业用户的GPU通常使用被动散热并增加了内存校验,从而更适合数据中心,并通常要比面向个人用户的GPU贵上10倍。
Nvidia一般每一两年发布一次新版本的GPU,例如2017年发布的是GTX 1000系列。每个系列中会有数个不同的型号,分别对应不同的性能。
基础软件及环境配置:
- 安装cuda(cuda对C语言进行扩展,允许定义一种称为kernel的函数,当次函数被调用时,在N个cuda线程中执行了N遍)。
- 安装cudnn。
cudnn是Nvidia的专门针对深度学习的加速库。
整机配置:
通常,我们主要用GPU做深度学习训练。因此,不需要购买高端的CPU。至于整机配置,尽量参考网上推荐的中高档的配置就好。不过,考虑到GPU的功耗、散热和体积,我们在整机配置上也需要考虑以下三个额外因素。
- 机箱体积。GPU尺寸较大,通常考虑较大且自带风扇的机箱。
- 电源。购买GPU时需要查一下GPU的功耗,例如50W到300W不等。购买电源要确保功率足够,且不会过载机房的供电。
- 主板的PCIe卡槽。推荐使用PCIe 3.0 16x来保证充足的GPU到主内存的带宽。如果搭载多块GPU,要仔细阅读主板说明,以确保多块GPU一起使用时仍然是16x带宽。注意,有些主板搭载4块GPU时会降到8x甚至4x带宽。
小结:
- 在预算范围之内,尽可能买较新的GPU
- 整机配置需要考虑到GPU的功耗、散热和体积。
附录
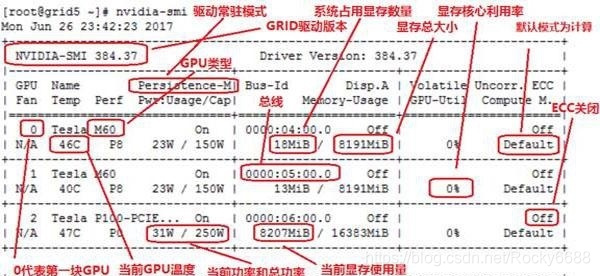
在此附上Nvidia的GPU命令行的参数: