1. 深度学习的本质
首先深度学习也是机器学习的一个分支,深度学习是基于神经网络的一种建模方法。深度学习的本质是通过构建具有很多隐藏的机器学习模型和海量的训练数据来学习更有用的特征,从而到达提高分类性能和预测的准确性。
2. 深度学习的目的
深度学习通过模拟人脑进行分析学习的神经网络,神经网络模拟人脑的机制来解释数据例如:图像、声音、文本等
3. 反向传播推导
反向传播算法(Backpropagation)是目前用来训练人工神经网络(Artificial Neural Network,ANN)的最常用且最有效的算法。其主要思想是:
(1)将训练集数据输入到ANN的输入层,经过隐藏层,最后达到输出层并输出结果,这是ANN的前向传播过程;
(2)由于ANN的输出结果与实际结果有误差,则计算估计值与实际值之间的误差,并将该误差从输出层向隐藏层反向传播,直 至传播到输入层;
(3)在反向传播的过程中,根据误差调整各种参数的值;不断迭代上述过程,直至收敛。
推导过程:如图是一个全连接的神经网络


(4)先定义一些变量:
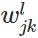 表示第
表示第
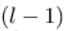 层的第
层的第
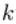 个神经元连接到第
个神经元连接到第
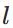 层的第
层的第
 个神经元的权重;
个神经元的权重;
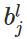 表示第层的第个神经元的偏置;
表示第层的第个神经元的偏置;
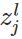 表示第层的第个神经元的输入,即:
表示第层的第个神经元的输入,即:
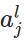 表示第层的第个神经元的输出,即:
表示第层的第个神经元的输出,即:
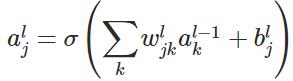
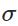 表示激活函数。
表示激活函数。
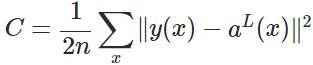
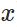 表示输入的样本,
表示输入的样本,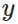 表示实际的分类,
表示实际的分类,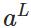 表示预测的输出,
表示预测的输出,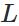 表示神经网络的最大层数。
表示神经网络的最大层数。
3. 公式及其推导
层第个神经元中产生的错误(即实际值与预测值之间的误差)定义为:
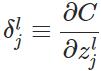
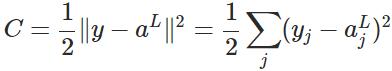
 表示Hadamard乘积,用于矩阵或向量之间点对点的乘法运算。
公式1的推导过程如下:
表示Hadamard乘积,用于矩阵或向量之间点对点的乘法运算。
公式1的推导过程如下:
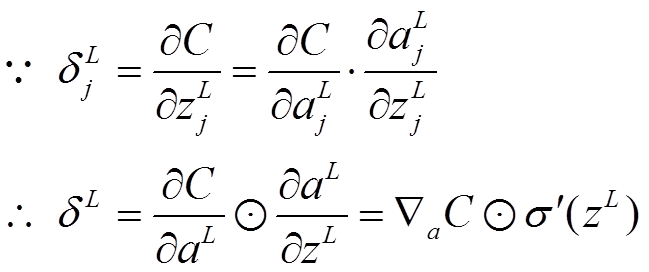
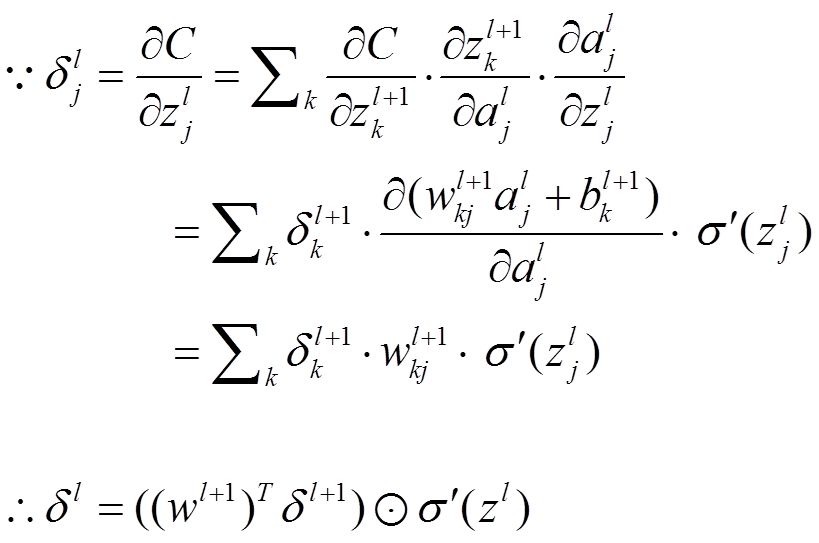
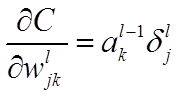
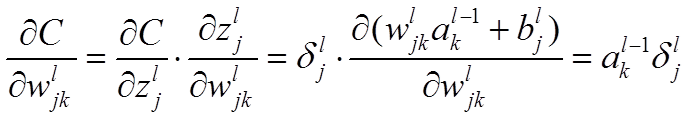
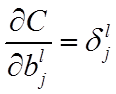
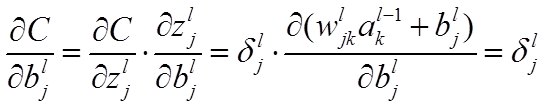
求解损失函数最小化的问题,然后通过梯度下降不断更新参数,达到训练神经网络的效果。
4. 为什么要用激活函数?
(1)、 激活函数有很多种,在神经网络中常用的三种,分别是tanh [-1, 1]、sigmoid (0, 1 )、Relu (0, x)。分别在什么情况下用,可以自己查询相关资料。
(2)、激活函数是用来加入非线性因素的,因为非线性模型的表达能力不够,有些数据可以线性可分,而有些数据是线性不可分的,对于线性可分的数据就需要做线性变换,比如把x, y 轴变成x^2 * y^2等之类的变换;或者引入非线性函数。
(3)、在神经网络中,我们通过使用激活函数来使数据线性可分,通过函数把特征保留并映射出来,这是神经网络能够解决非线性问题的关键。
总之:激活函数就是使神经网络具有拟合非线性函数的能力, 使神经网络具有强大的表达能力
5. 什么是梯度消失、梯度爆炸
在反向传播的过程中,前面几层的权重正常更新,而接近到后面层权重基本上不更新(更新到0,基本后面的网络层都死掉了),导致后面的层学不到任何东西,也就是说后面的层只相当于输出一个映射,那么深层的神经网络就仅仅相当浅层的神经网络了。梯度消失和梯度爆炸都是梯度不稳定的表现,所以当层数增多容易引起梯度不稳定的表现。
6. 为什么会有梯度消失、梯度爆炸?
由于画图不方便,我就上传我之前做过的笔记,同时也参考了highway network解决梯度消失

7. 为什么需要深层神经网络?
(1)、神经网络层数的增多会使每一层任务变得简单。 例如:计算乘法,我们可以在第一层计算按位加法,第 二层计算两个数的加法,第三层再计算乘法,这样使算法的逻辑更加简单,清晰。也就是说中间层可以做更深的抽象。
(2)、数学上可以证明只有一层隐藏层的神经网络可以表示任意的函数,但是神经元的数量却是指数级的递增,因此,通过使用深层的神经网络可以解决这个问题。
8. 在合理的范围,增大batch_size有何好处?
(1)、batch在神经网络本来是作为计算加速的,通过把数据进行统一大小,然后批量进入神经网络模型,以此到达加速的效果。那么batch可以无限增大吗?答案是否定的,小编也搜过这样的答案,不妨看一下知乎的大牛:怎么选取合适的batch大小。以我的浅见:
第一、 合适的batch大小可以内存的利用率,这个是必然的,大矩阵乘法的并行化效率提高。
第二、 跑一次全数据集所需要的迭代次数减少了,时间成本可以节省了。
第三、在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小
上述的引文也讨论了盲目增大batch的后果也有三点:
第一、 内存利用率提高了,但是内存容量可能撑不住
第二、 跑一遍全数据集的迭代次数减少,要想达到同样的精度,所需要花费的时间大大增加了,从而对参数的修正就显得更加缓慢了。
第三、 batch_size 增加到一定的程度,其确定的下降方向已经基本不再变化。
本篇文章引用多篇博主的博客,如果没有来及提及博主,望见谅,勿喷。