我们将探讨如何使用Spring Cloud Stream和Kafka Streams编写流处理应用程序。
Spring Cloud Stream Horsham 版本(3.0.0)对应用程序使用Apache Kafka的方式进行了一些更改,可以使用Kafka和Kafka Streams的binders。
1.Spring Cloud Stream下有几种类型的Kafka的binders?
这通常是一个令人困惑的问题:如果我想基于Apache Kafka编写应用程序,应该使用哪种binders。 Spring Cloud Stream为Kafka提供了两个binders ,spring-cloud-stream-binder-kafka和spring-cloud-stream-binder-kafka-streams。
spring-cloud-stream-binder-kafka是要编写标准事件驱动的应用程序而要使用普通Kafka生产者和使用者的应用程序。spring-cloud-stream-binder-kafka-streams使用Kafka Streams库开发流处理应用程序。
注意:在本文章中,我们将重点介绍Kafka Streams的binders。
本篇文章主要是Spring Cloud Stream和Kafka Streams之间的整合,而没有涉及Kafka Streams本身的细节。 想要实现一个好的基于Kafka Streams的流处理应用程序,强烈建议对Kafka Streams库有更深入的了解。 本文仅停留在实际的Kafka Streams库的简单使用,后面有时间会深入研究Kafka Streams的使用
2.创建Spring Cloud Stream Kafka Streams应用程序
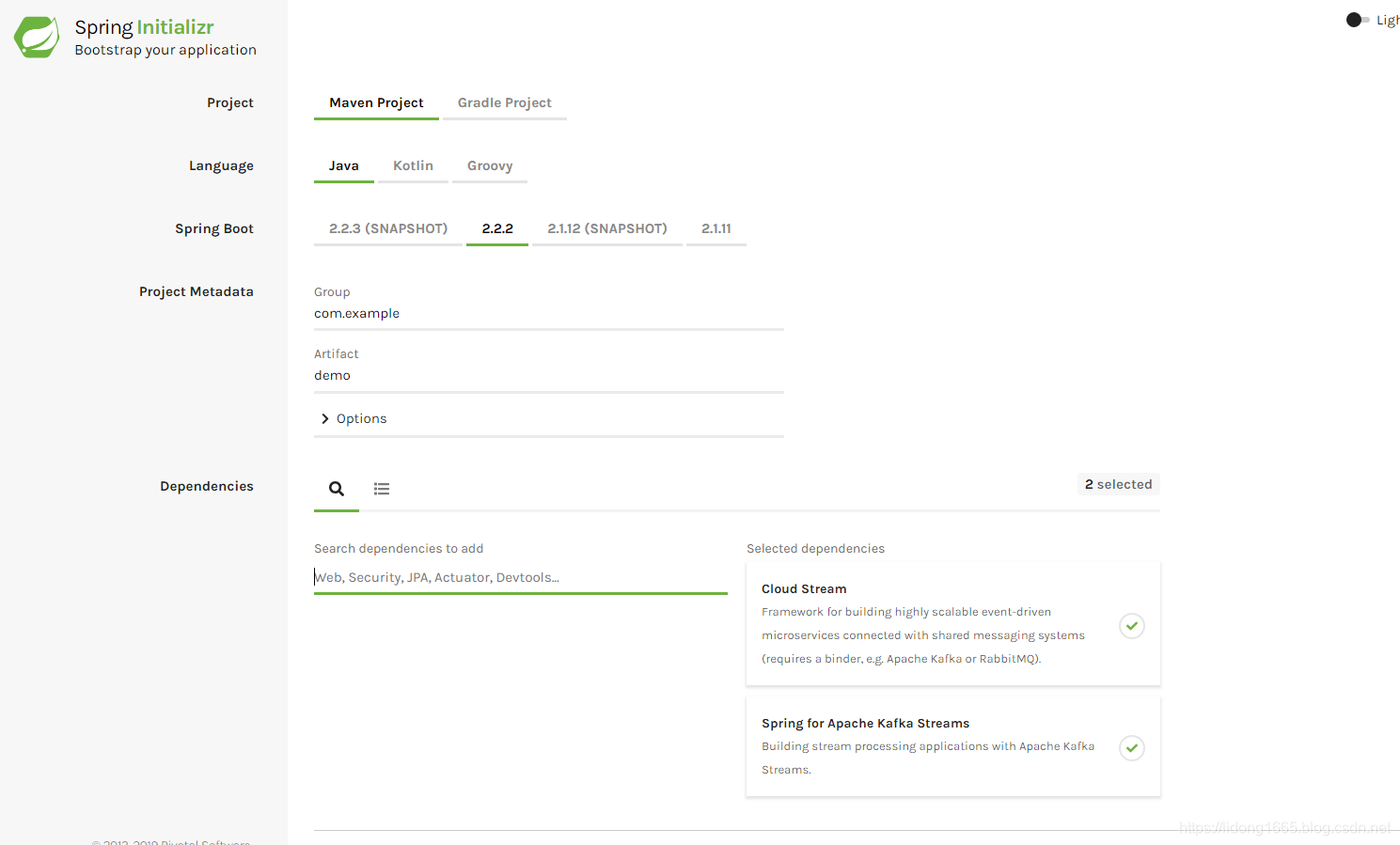
从本质上讲,所有Spring Cloud Stream应用程序都是基于Spring Boot应用程序。 为了创建新项目,请转到pring Initializr,然后创建一个新项目。 选择Cloud Stream和Spring for Apache Kafka Streams作为依赖项。 这将生成一个项目,其中包含开始开发应用程序所需的所有组件。 这是Initializr的屏幕截图,其中选择了基本依赖项。
3.编一个简单的示例(WordCount)
这是一个非常基本但非常实用的Kafka Streams应用程序,它是使用Spring Cloud Stream的功能编写的
3.1创建 SpringCloudKafkaStreamsExampleApplication
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.common.utils.Bytes;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.kstream.Grouped;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.Materialized;
import org.apache.kafka.streams.kstream.TimeWindows;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import java.time.Duration;
import java.util.Arrays;
import java.util.Date;
import java.util.function.Function;
@SpringBootApplication
public class SpringCloudKafkaStreamsExampleApplication {
public static void main(String[] args) {
SpringApplication.run(SpringCloudKafkaStreamsExampleApplication.class, args);
}
public static class WordCountProcessorApplication {
public static final String INPUT_TOPIC = "words";
public static final String OUTPUT_TOPIC = "counts";
public static final int WINDOW_SIZE_MS = 30000;
@Bean
public Function<KStream<Bytes, String>, KStream<Bytes, WordCount>> process() {
return input -> input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.map((key, value) -> new KeyValue<>(value, value))
.groupByKey(Grouped.with(Serdes.String(), Serdes.String()))
.windowedBy(TimeWindows.of(Duration.ofMillis(WINDOW_SIZE_MS)))
.count(Materialized.as("WordCounts-1"))
.toStream()
.map((key, value) -> new KeyValue<>(null, new WordCount(key.key(), value, new Date(key.window().start()), new Date(key.window().end()))));
}
}
static class WordCount {
private String word;
private long count;
private Date start;
private Date end;
@Override
public String toString() {
final StringBuffer sb = new StringBuffer("WordCount{");
sb.append("word='").append(word).append('\'');
sb.append(", count=").append(count);
sb.append(", start=").append(start);
sb.append(", end=").append(end);
sb.append('}');
return sb.toString();
}
WordCount() {
}
WordCount(String word, long count, Date start, Date end) {
this.word = word;
this.count = count;
this.start = start;
this.end = end;
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
public long getCount() {
return count;
}
public void setCount(long count) {
this.count = count;
}
public Date getStart() {
return start;
}
public void setStart(Date start) {
this.start = start;
}
public Date getEnd() {
return end;
}
public void setEnd(Date end) {
this.end = end;
}
}
}
如上面的代码,这是一个非常简单的单词统计应用程序,仅将统计的结果数据打印到控制台,但仍然是功能完善的Kafka Streams应用程序。 在外层,通过使用@SpringBootApplication注解标识这是一个启动类的应用程序。 然后,我们提供一个java.util.function.Function的bean,通过lambda表达式封装单词统计的的逻辑。 将KStream<Bytes, String>作为其输入,KStream<Bytes, WordCount>`为输出。
注意:时间窗口为30s,即:30s执行一次单词出现的次数统计。
3.2 application.yml配置文件
spring.cloud.stream:
bindings:
process-in-0:
destination: words
process-out-0:
destination: counts
kafka:
streams:
binder:
applicationId: hello-word-count-sample
configuration:
commit.interval.ms: 100
default:
key.serde: org.apache.kafka.common.serialization.Serdes$StringSerde
value.serde: org.apache.kafka.common.serialization.Serdes$StringSerde
#Enable metrics
management:
endpoint:
health:
show-details: ALWAYS
endpoints:
web:
exposure:
include: metrics,health
#Enable logging to debug for spring kafka config
logging:
level:
org.springframework.kafka.config: debug
spring:
cloud:
stream:
kafka:
binder:
brokers: localhost:9092
min-partition-count: 5
kafka:
bootstrap-servers: localhost:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: counts-group
enable-auto-commit: true
auto-commit-interval: 1000
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
server:
port: 8096
spring.cloud.stream.bindings:process-in-0.destination: 标识源数据的Topic 如:wordsspring.cloud.stream.bindings:process-out-0.destination: 标识结果集的Topic 如:countsspring.cloud.stream.kafka.binder.applicationId:标识应用的Id 如:hello-word-count-samplespring.cloud.stream.kafka.binder.brokers: Kafka的broker地址 如:localhost:9092
3.3 KafkaConsumer 消费wordcount的结果集
import com.alibaba.fastjson.JSON;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
/**
* kafka消费counts的topic中的数据,这里我们只是为了演示,直接输出到控制台,以后我们就可以存储数据库中。
*/
@Component
@Slf4j
public class KafkaConsumer {
@KafkaListener(topics = "counts")
public void listen(ConsumerRecord<?, ?> record) throws Exception {
String value = (String) record.value();
log.info("partition = {},topic = {}, offset = {}, value = {}",record.partition(), record.topic(), record.offset(), value);
WordCount wordCount = JSON.parseObject(value, WordCount.class);
log.info(wordCount.toString());
}
}
到这里我们就可以启动kafka的broker,来测试以上应用程序。
4.测试案例
4.1 启动Zookeeper服务
bin\windows\zookeeper-server-start.bat config/zookeeper.properties
4.2 启动Apache Kafka服务
bin\windows\kafka-server-start.bat config/server.properties
4.3 使用kafka-consule-producer命令在控制台发送字符串

4.4查询测试结果
2019-12-09 18:15:03.183 INFO 10008 --- [ntainer#0-0-C-1] com.lidongexample.KafkaConsumer : partition = 0,topic = counts, offset = 5446, value = {"word":"beijing","count":1,"start":1575886500000,"end":1575886530000}
2019-12-09 18:15:03.244 INFO 10008 --- [ntainer#0-0-C-1] com.lidongexample.KafkaConsumer : WordCount{word='beijing', count=1, start=Mon Dec 09 18:15:00 CST 2019, end=Mon Dec 09 18:15:30 CST 2019}
2019-12-09 18:15:03.244 INFO 10008 --- [ntainer#0-0-C-1] com.lidongexample.KafkaConsumer : partition = 0,topic = counts, offset = 5447, value = {"word":"lidong","count":1,"start":1575886500000,"end":1575886530000}
2019-12-09 18:15:03.244 INFO 10008 --- [ntainer#0-0-C-1] com.lidongexample.KafkaConsumer : WordCount{word='lidong', count=1, start=Mon Dec 09 18:15:00 CST 2019, end=Mon Dec 09 18:15:30 CST 2019}
2019-12-09 18:15:03.245 INFO 10008 --- [ntainer#0-0-C-1] com.lidongexample.KafkaConsumer : partition = 0,topic = counts, offset = 5448, value = {"word":"aihuhui","count":1,"start":1575886500000,"end":1575886530000}
2019-12-09 18:15:03.245 INFO 10008 --- [ntainer#0-0-C-1] com.lidongexample.KafkaConsumer : WordCount{word='aihuhui', count=1, start=Mon Dec 09 18:15:00 CST 2019, end=Mon Dec 09 18:15:30 CST 2019}
2019-12-09 18:15:03.245 INFO 10008 --- [ntainer#0-0-C-1] com.lidongexample.KafkaConsumer : partition = 0,topic = counts, offset = 5449, value = {"word":"xd","count":1,"start":1575886500000,"end":1575886530000}
2019-12-09 18:15:03.245 INFO 10008 --- [ntainer#0-0-C-1] com.lidongexample.KafkaConsumer : WordCount{word='xd', count=1, start=Mon Dec 09 18:15:00 CST 2019, end=Mon Dec 09 18:15:30 CST 2019}
2019-12-09 18:15:07.213 INFO 10008 --- [ntainer#0-0-C-1] com.lidongexample.KafkaConsumer : partition = 0,topic = counts, offset = 5450, value = {"word":"beijing","count":2,"start":1575886500000,"end":1575886530000}
2019-12-09 18:15:07.214 INFO 10008 --- [ntainer#0-0-C-1] com.lidongexample.KafkaConsumer : WordCount{word='beijing', count=2, start=Mon Dec 09 18:15:00 CST 2019, end=Mon Dec 09 18:15:30 CST 2019}
2019-12-09 18:15:07.214 INFO 10008 --- [ntainer#0-0-C-1] com.lidongexample.KafkaConsumer : partition = 0,topic = counts, offset = 5451, value = {"word":"lidong","count":2,"start":1575886500000,"end":1575886530000}
2019-12-09 18:15:07.214 INFO 10008 --- [ntainer#0-0-C-1] com.lidongexample.KafkaConsumer : WordCount{word='lidong', count=2, start=Mon Dec 09 18:15:00 CST 2019, end=Mon Dec 09 18:15:30 CST 2019}
2019-12-09 18:15:09.638 INFO 10008 --- [ntainer#0-0-C-1] com.lidongexample.KafkaConsumer : partition = 0,topic = counts, offset = 5452, value = {"word":"huge","count":1,"start":1575886500000,"end":1575886530000}
2019-12-09 18:15:09.639 INFO 10008 --- [ntainer#0-0-C-1] com.lidongexample.KafkaConsumer : WordCount{word='huge', count=1, start=Mon Dec 09 18:15:00 CST 2019, end=Mon Dec 09 18:15:30 CST 2019}
2019-12-09 18:15:11.691 INFO 10008 --- [ntainer#0-0-C-1] com.lidongexample.KafkaConsumer : partition = 0,topic = counts, offset = 5453, value = {"word":"ghhe","count":1,"start":1575886500000,"end":1575886530000}
2019-12-09 18:15:11.692 INFO 10008 --- [ntainer#0-0-C-1] com.lidongexample.KafkaConsumer : WordCount{word='ghhe', count=1, start=Mon Dec 09 18:15:00 CST 2019, end=Mon Dec 09 18:15:30 CST 2019}
以上就是统计的结果日志。
5.总结
在此文章中,我们快速介绍了如何使用Spring Cloud Stream的功能编程支持编写使用Kafka Streams的流计算应用程序。 我们看到了binder处理了很多基础的配置,使我们可以专注于实现业务逻辑。 在下一篇文章中,我们将进一步探索Apache Kafka Streams的编程模型,以了解如何使用Spring Cloud Stream和Kafka Streams开发更多优秀的流处理应用程序。
本文中案例源码:github地址
