1. 机器翻译attention
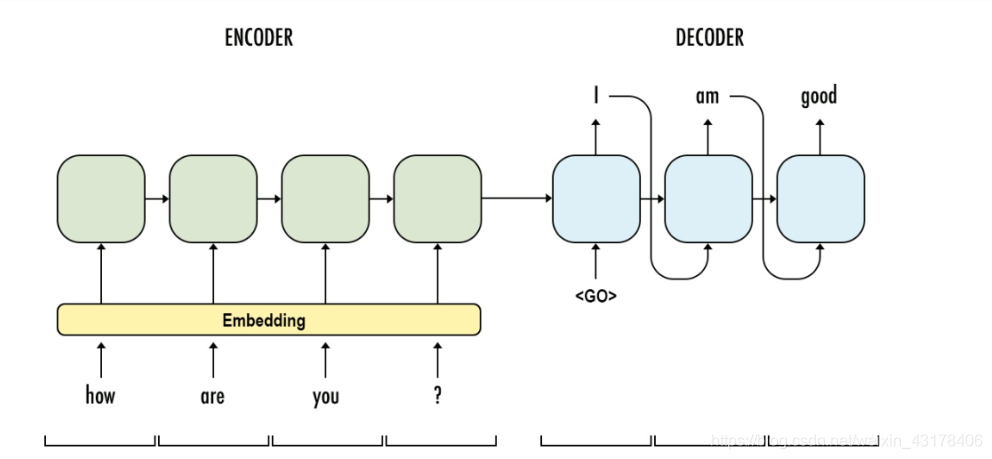
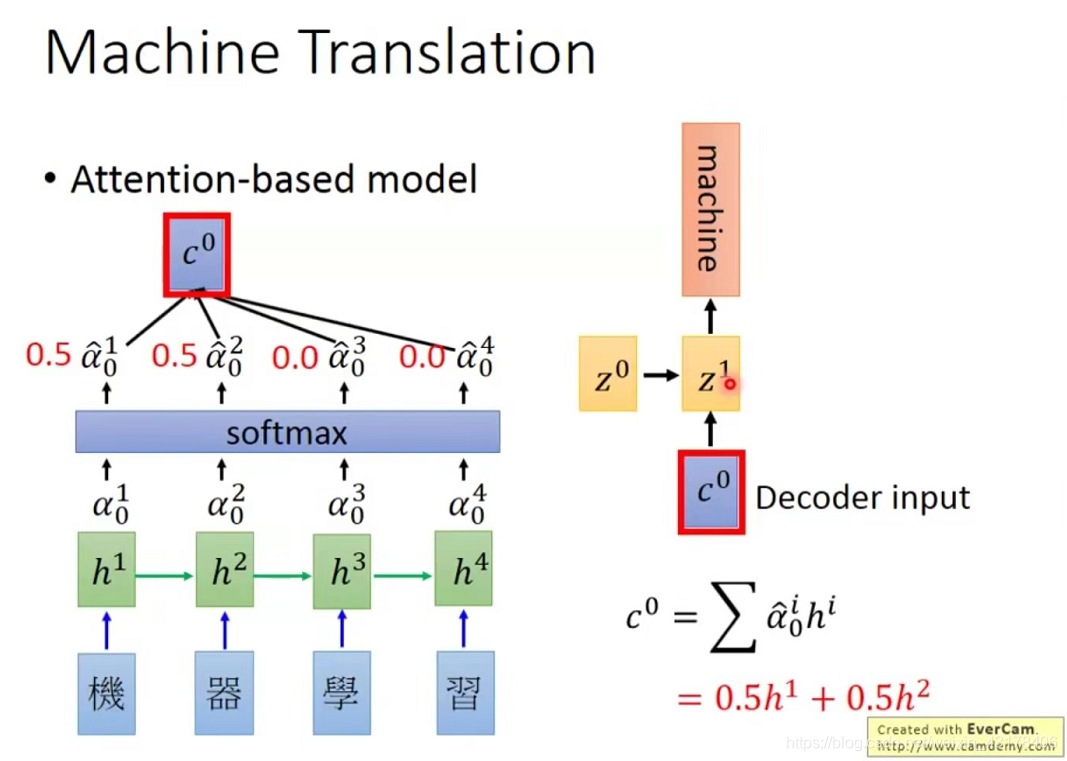
在seq2seq结构中,针对一个样本,decoder的每个输入(字向量)都是encoder的最后一个词的输出。attention机制企图达到以下目的:以将“机器学习”翻译成machine learning为例。decoder中第一次只想关注机器,从而翻译成machine;第二次只想关注学习,并翻译成learning。因此,decoder中每个输入(字向量)都是不一样的。(下图为普通的seq2seq,encoder最后一层的输出是decoder的h0)
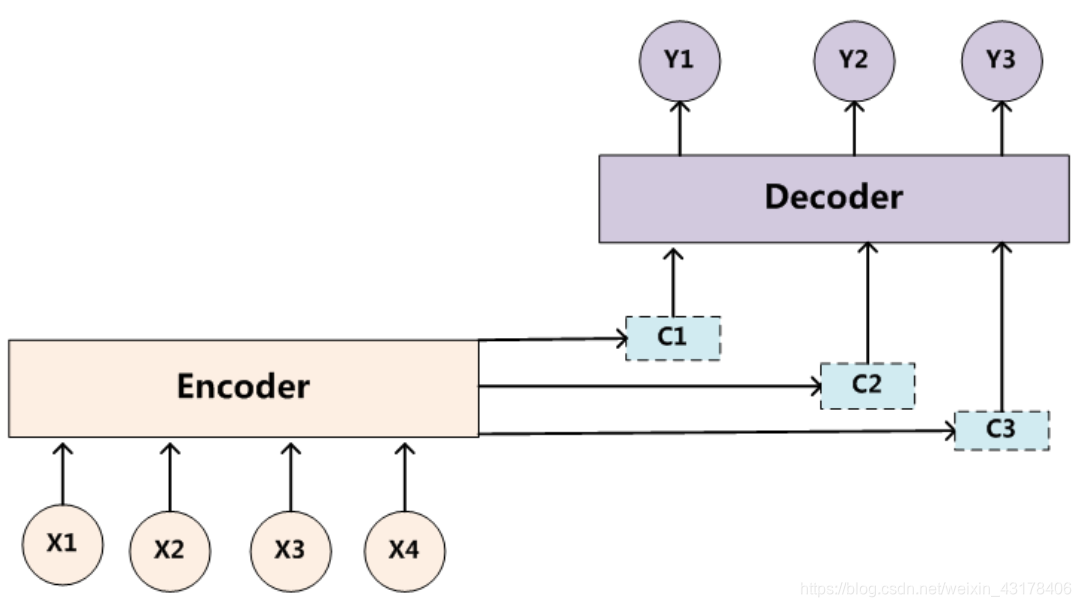
为了达到decoder每次的输入都不一样,引入了attention机制(本质上是一种加权和),如第一次只想关注机器,故可以把机和器的权重均设置成0.5,学和习的权重均设置成0(0.5和0都是讲解时的一种假设,具体为多少是学习出来的)。
现在讲解如何得到decoder的第一个输入(在encoder层加入attention机制)。机器学习四个字每个字对应一个字向量
。其组成一个矩阵X(每一行代表
),现在有一个
列向量(
是网络学习出来的,相当于一个query,代表我想找到机器)
向量分别与
相乘,得到
,h是一个列向量,
为一个数,即
与
的内积。将h向量转置成行向量后softmax得到
(p是一个行向量),softmax的结果相当于概率值,代表了
的权重。然后进行如下运算
,,为每个字向量乘以权重后相加。
上述讲到了如何得到decoder的第一次输入,如何得到decoder的第二次输入呢,原理相同,只是将
变成了
,而
由RNN的结构决定,即初始的
与本次的输入经RNN层的结果。如此循环,直至遇到EOS结束。详见下图。
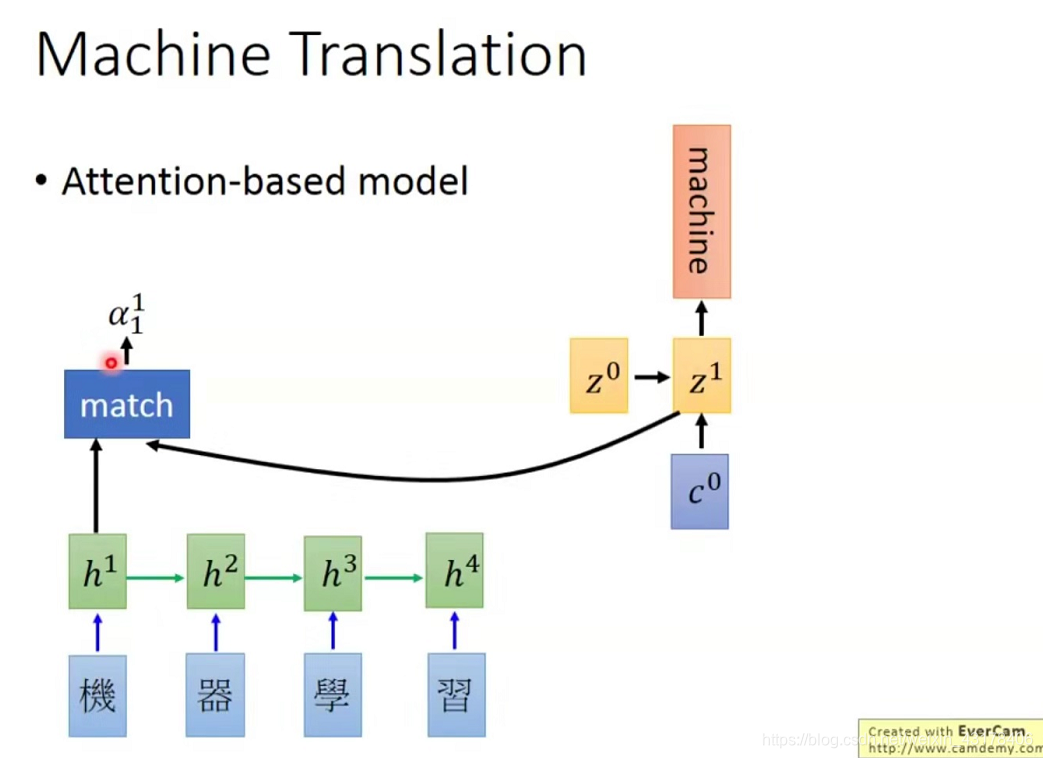
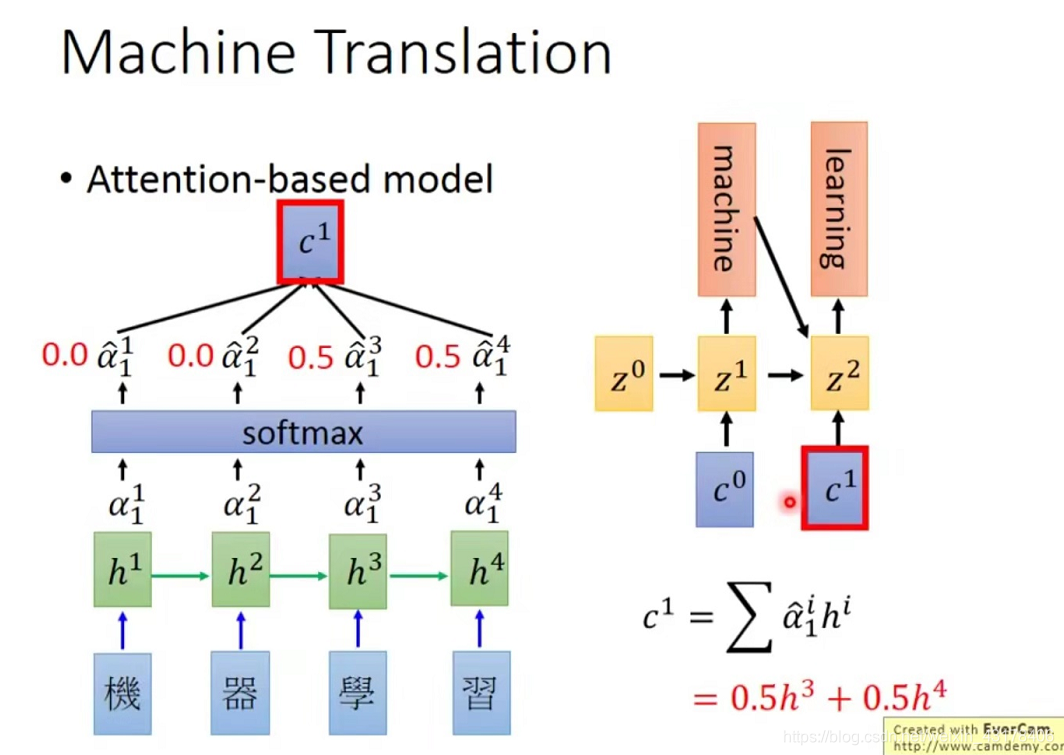
回顾上述过程,softmax里面的内容 ,我们采用的是每个向量内积的方式,而这一方式决定了每个字向量的概率(softmax前的概率),因此这一过程很重要,这一过程也被称为match操作,match操作有很多,可以是刚才的内积方式,也可以是其他很多,常见的有以下三种方式:
- 内积
- 简单神经网络
- Z(XW)T
2. attention机制的泛化表示
借助机器翻译中的attention,对attention机制做一个概括。之前看attention经常会提到三个词Q(query)、K(key)、V(value)。下面以阅读理解为例讲解这三个字母的含义,给一篇文章和一个问题,得到该问题的答案。该篇文章就相当于上述的V(矩阵,每一行代表字向量或者词向量,也即机器翻译中的‘机器学习’四个字构成的矩阵),问题就相当于Q(第一行代表该问题,第二行是对该问题向量的修正,也即机器翻译中的Z),K可以等于V,也可以是VW等方式进行转化,主要是拿V的变形(机器翻译中直接是V或者X本身)与Q相乘再softmax得到每个
的概率值,得到概率值后再与V相乘(效果是数与向量相乘再相加,得到加权后的向量,多次这样操作,就得到了矩阵,每行代表加权后的向量)。
因此上述过程可以表示成
简单的attention操作是在输入与target之间进行的,下面讲到的self-attention则是在输入之间进行的,具体操作下面会讲到
3. self-attention
给定一个输入向量X,可以通过下面操作分别得到K、Q、V:在encoder层,
。同样的原理encoder+attention后的输出为
,在transformer结构中out=softmax(QK^T)V。具体的分解过程如下图所示,可更好的理解self-attention。
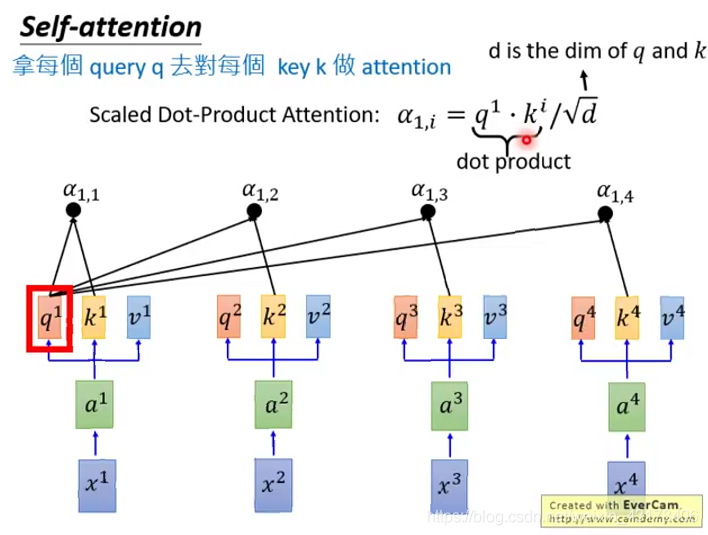
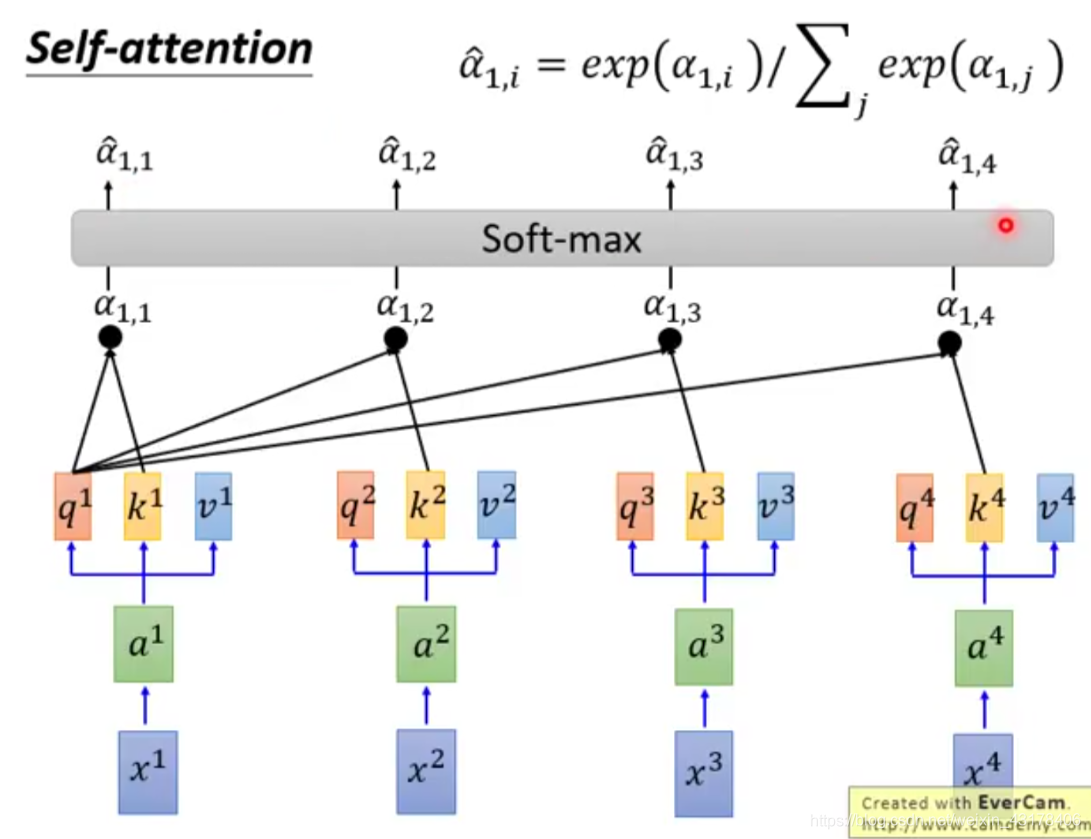
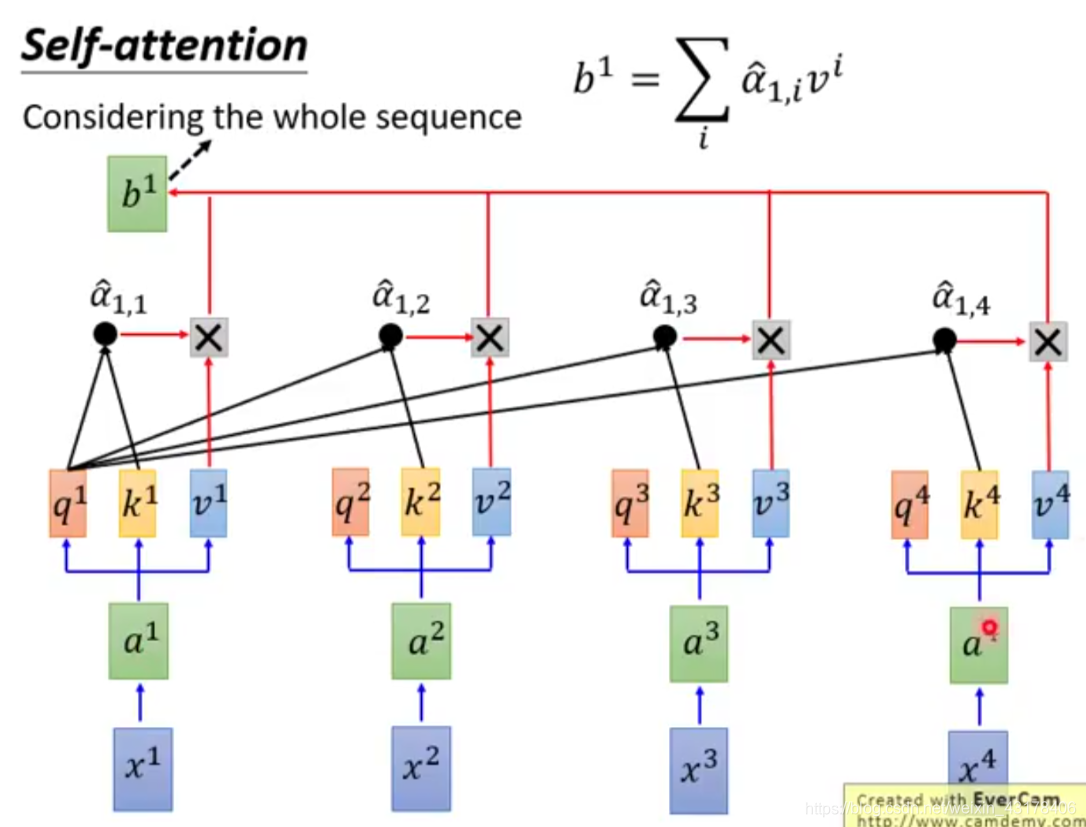
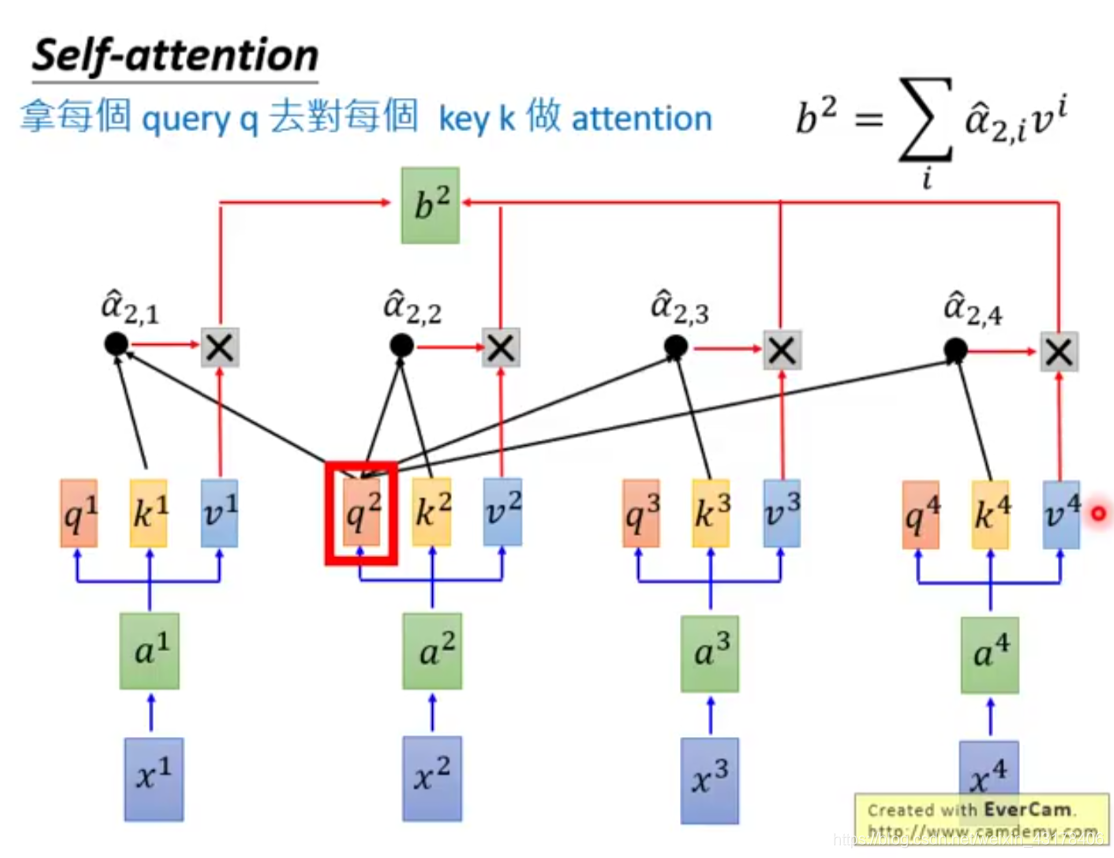

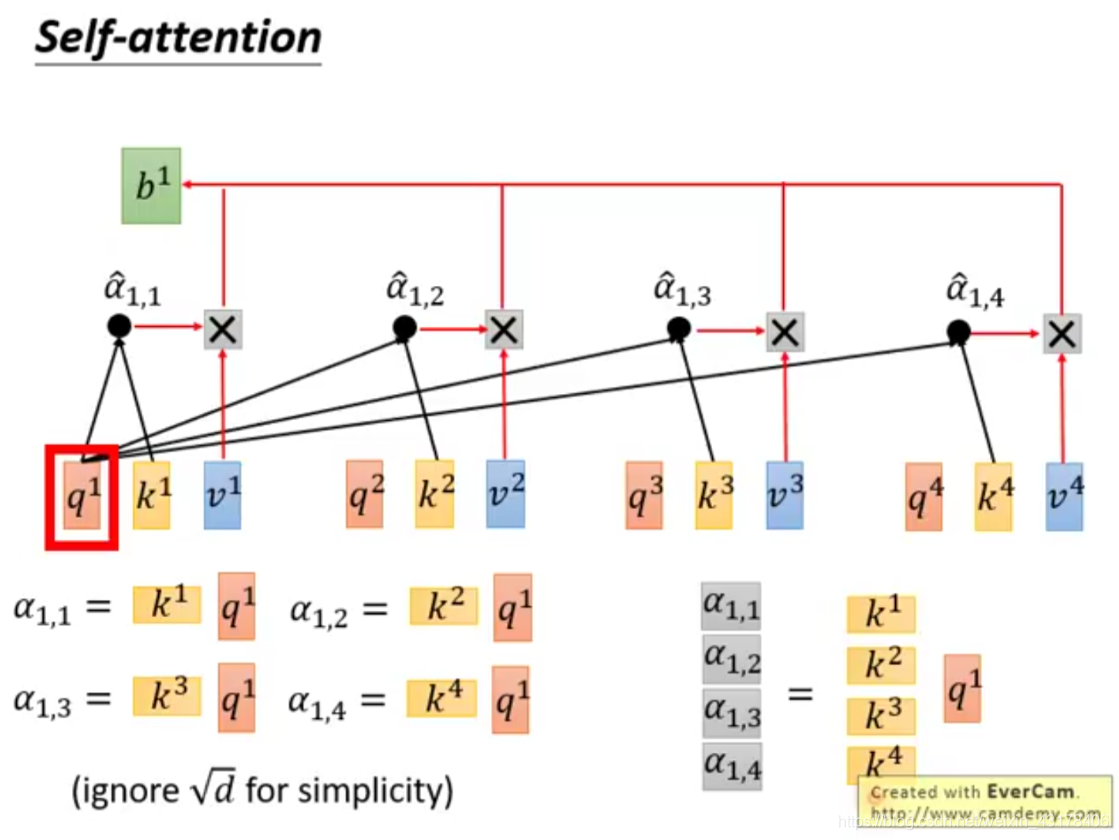
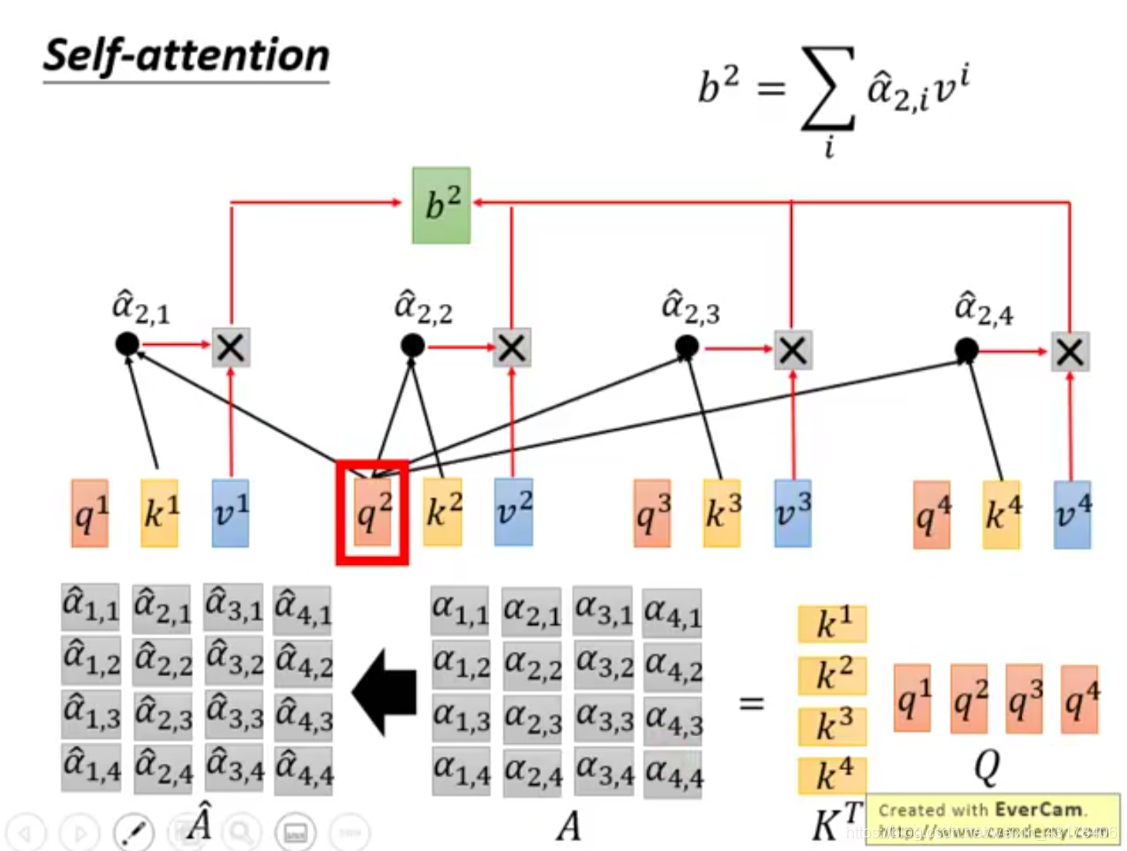
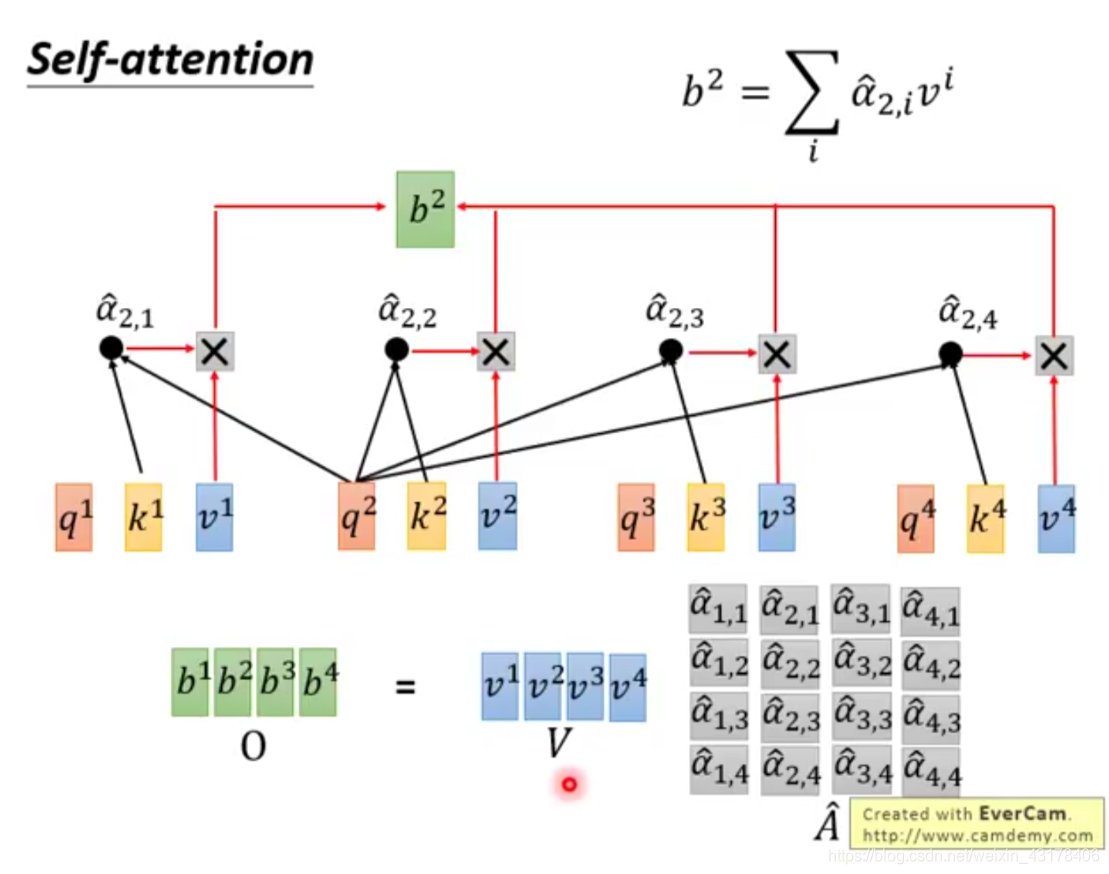
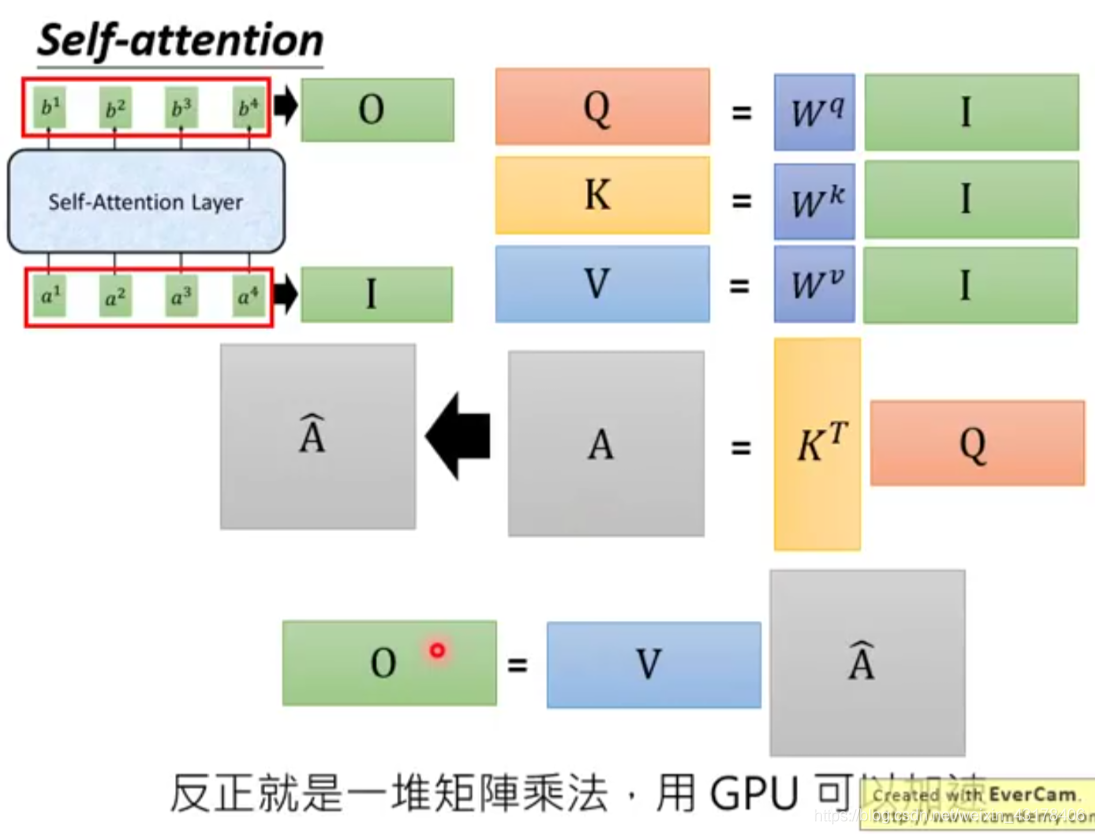
可以看到self-attention中Q的每个向量是相互独立的,即
不依赖于
,故可以直接矩阵运算(并行)。机器翻译的例子中,虽然也可以表示成矩阵形式,但是
依赖于
,或者说
依赖于
,故只能串行运算。
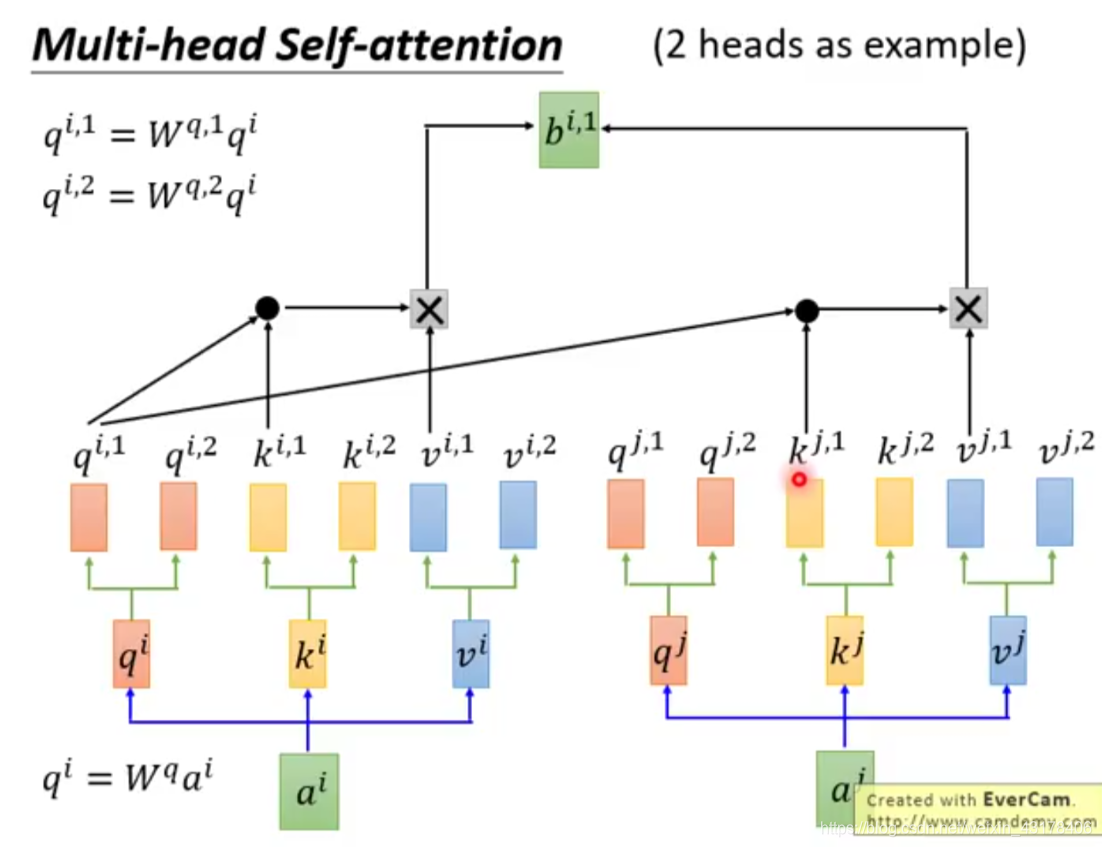
multi-self-attention
multi-self-attention和selfattention的原理很相似,只是得到Q、K、V时不止得到一个,而是多个,以两个为例,
上述过程也可以写成矩阵相乘得方式,只是现在的矩阵是广义的形式,本例中K、Q、V都是三维,最后两维的矩阵即
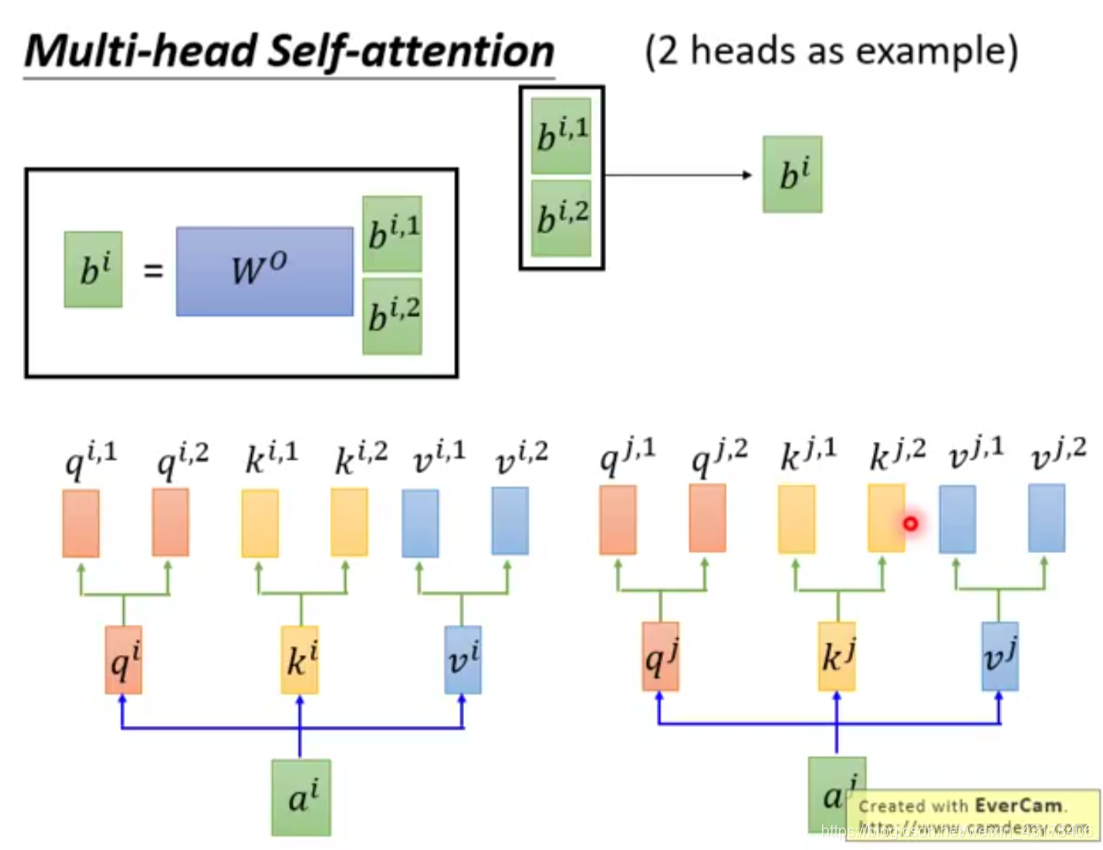
,第0维即代表了i。之前对于一次self-attention得到的是一个向量,现在由于multi,得到的是一个矩阵,每行代表一头的结果,然后对这多头进行method操作,method可以是向量求和,也可以是均值,拼接等。tansformer中为拼接操作。
分解的图如下所示: