1、唠唠叨叨
在我之前的文章中讲述过如何利用xpath来抓取网页的内容,不过之前的开发语言我都是使用的Python。如果GoLang也想用Xpath该如何使用呢?下面就来简单的讲一下如何用Golang爬取github.com的一些小内容来做切入点学会这个知识吧。
回顾一下:
2、先看一下效果
比如爬取github.com的这几个控件的内容
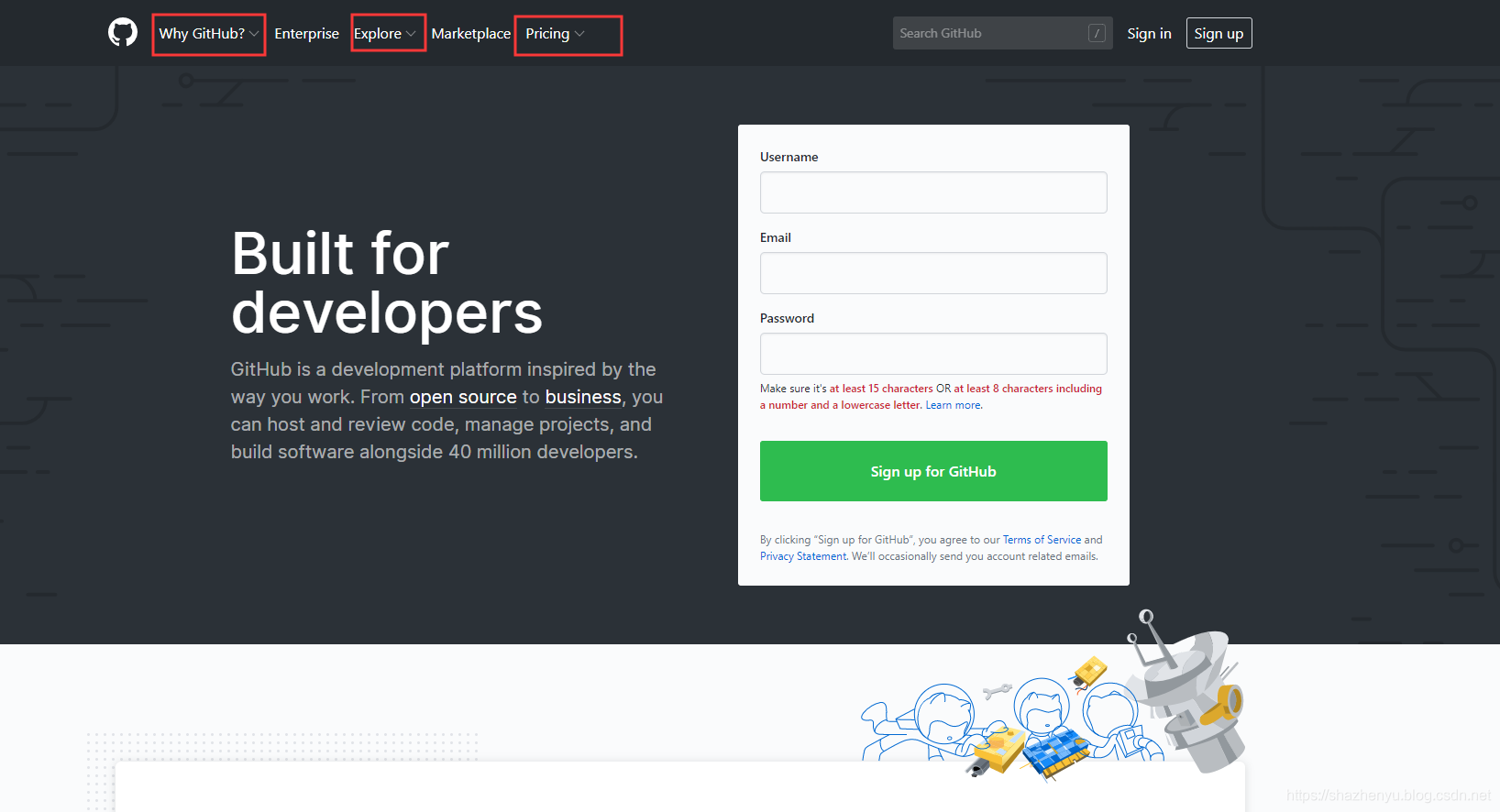
爬取后得到的内容:
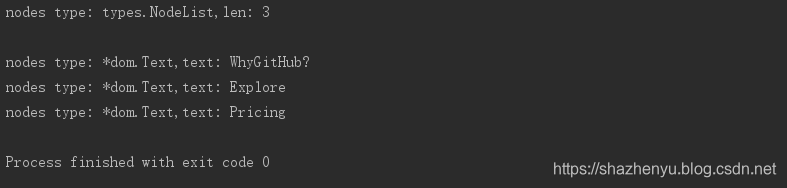
3、项目所需包
先安装项目所需的包,再说其它:
https://github.com/pkg/errors
https://github.com/lestrrat-go/libxml2
4、核心代码
/**
Author: 沙振宇
CreateTime:2019-12-4
UpdateTime:2019-12-4
Info: “利用 Xpath 读取 html 内容”
“通过Github来演示Xpath如何使用”
*/
package main
import (
"fmt"
"github.com/lestrrat-go/libxml2"
"github.com/lestrrat-go/libxml2/xpath"
"net/http"
"strings"
)
// 去除空格和换行符
func getReplace(str string) string{
// 去除空格
str = strings.Replace(str, " ", "", -1)
// 去除换行符
str = strings.Replace(str, "\n", "", -1)
return str
}
func main() {
urlPath := "https://github.com/"
res, err := http.Get(urlPath)
if err != nil {
panic("failed to get : " + err.Error())
}
doc, err := libxml2.ParseHTMLReader(res.Body)
if err != nil {
panic("failed to parse HTML: " + err.Error())
}
defer doc.Free()
nodes := xpath.NodeList(doc.Find(`//summary[@class="HeaderMenu-summary HeaderMenu-link px-0 py-3 border-0 no-wrap d-block d-lg-inline-block"]/text()`))
fmt.Printf("nodes type: %T,len: %d\n\n", nodes, len(nodes))
for i := 0; i < len(nodes); i++ {
fmt.Printf("nodes type: %T,text: %s\n", nodes[i], getReplace(nodes[i].String()))
}
}
5、Github源码分享
https://github.com/ShaShiDiZhuanLan/Demo_Xpath_Go
6、其它小知识
6.1、git代码回滚
再用git上传代码导github中,遇到了一个问题,就是我想要删除一些没必要的commit记录。于是我把代码回滚到之前的记录,然后commit一下。查看本地库已经删除了,但push时发现怎么也push不上去,后来直接使用强制提交git push -f才提交成功。
# 注: n代表想往前回滚的次数
git reset --hard HEAD~n
# 强制提交
git push -f -u origin 分支名
6.2、github访问过慢
github.com访问有时过慢,于是利用“http://tool.chinaz.com/dns”查询了DNS链接最快的响应IP:
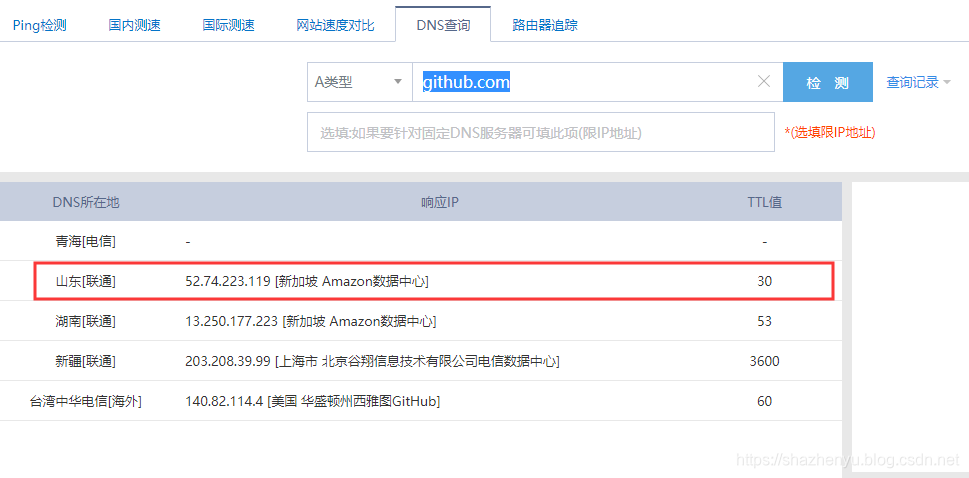
把这个IP配置到hosts中,
windows的话在:“C:\Windows\System32\drivers\etc\hosts”中配置,
linux的话再:“/etc/hosts”中配置
例如上述,把以下配置到hosts末尾即可:
52.74.223.119 github.com
