xpath应该是爬取网页最简单的方法啦,因为你需要要懂xpath,可以直接通过浏览器来获取你想要的内容。
以Chrome为例,按f12检查网页,用箭头点击自己想要的地方,比如我想提取出“故宫博物院”的xpath地址,右击,点击copy,然后选择copy xpath。这样我们就获得“故宫博物院”的xpath。
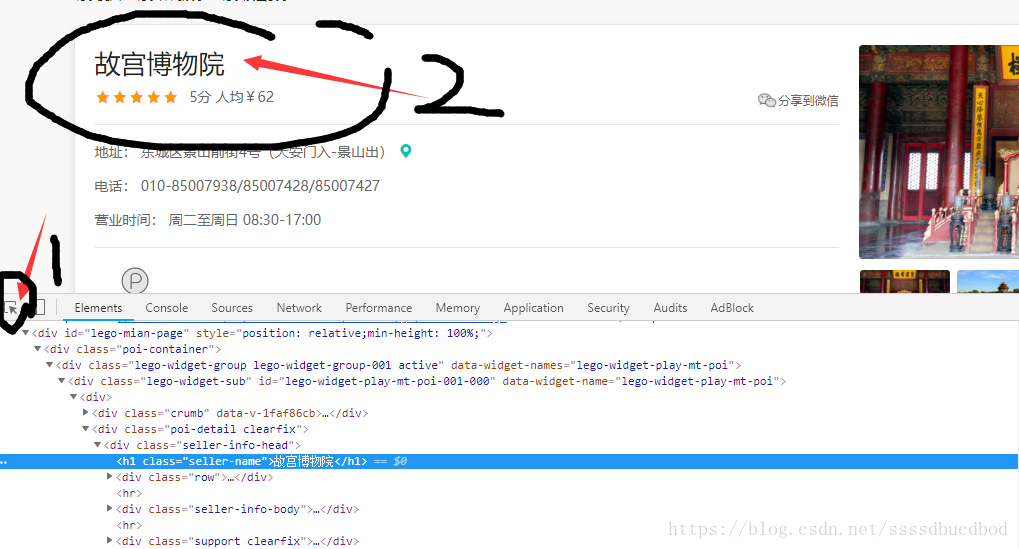
我们通过Chrome插件xpath helper来验证我们提取的xpath是否正确。

完全正确。完美。不过需要注意我们提取出的xpath是这个标签的xpath,如果我们需要提取其中的文字,我们需要在我们提取出的xpath后面加上“/text()”。
如何用python来提取出我想要的代码?这很简单,都是模板,只要按照以下的代码执行就行
import requests
from lxml import etree
import lxml
url="http://www.meituan.com/xiuxianyule/271772/"
#你需要爬取的网页
html=requests.get(url)
html.encoding="utf-8"
selecter=etree.HTML(html.text)
#将你的xpath复制到三引号里面,因为xpath里可能有双引号,所以我们加上三引号比较靠谱
s=selecter.xpath("""//*[@id="lego-widget-play-mt-poi-001-000"]/div/div[2]/div[1]/h1/text()""")
print (s)