最近,增量学习,持续学习,终生学习的概念越来越火,也引起了学术界工业界的极大关注,我们知道,传统的机器学习,就是给定一个训练集,我们在这个训练集上训练出一个模型,然后在测试集上做测试,这样基本就是一个完整的机器学习流程。增量学习,考虑的是模型持续学习的能力,比如,我们在数据集 上有一个数据集合: ,我们可以找到一个模型及一组参数,让其在该数据集上的联合概率分布最大:
这是传统机器学习要干的事情,增量学习,就是在这个基础上,如果我们有了一个新的数据集 ,我们希望模型在 上的联合概率分布能达到最大:
很显然,最直观的作法,就是将数据集 联合起来一块训练,同时去调整参数 ,但是,如果我们只能见到 的数据,而 的数据不可见的时候,我们又该达到这个目的呢,这就是增量学习想解决的问题。
我们都知道,机器学习可以看成是一种数据拟合,给定了什么样的数据分布,模型就会尽量去拟合这些数据分布,如果我们给定了 ,模型就会去拟合 ,如果给定了 模型就会去拟合 ,模型在拟合 的时候,可能就会将 的分布全部给遗忘了,对 的拟合越好,越准确,对 的遗忘可能就会越严重。增量学习首先要解决的就是持续学习中的遗忘问题。
反过来,如果我们尽量让模型记住 的分布,那么模型可能很难学到 的分布,所以模型如果想同时学到 的分布,就得在遗忘与学习之间取得平衡。
large scale incremental learning 是 2019 CVPR 的一篇文章,专门探讨的是大规模增量学习的问题,与以往只是少量的类别增量学习不同,这篇 paper 想解决的是大规模增量学习的问题,这篇 paper 对以往的增量学习算法也做了一些总结,主要分为以下三类:
- 完全不用旧数据,也就是说完全不用 的数据,而达到同时学习 分布的目的,这类方法主要有知识蒸馏,模型参数调整等策略
- 利用生成的旧数据,这类方法,主要是利用生成模型,先学习旧数据比如说 的分布,然后再利用生成模型,生成一些类似 的数据,然后再和 混在一起训练
- 最后一种方法,是利用部分历史数据,比如从 中选择部分代表性样本,然后和 混在一起训练
large scale incremental learning 利用了第三种策略,以往的很多文章也证明,第三种回顾测试的鲁棒性是最好的,而且很稳定。
这篇文章的思路还是很巧妙的,他们发现增量学习中,FC 层对新数据有很大的偏向,也就是说,训练的时候,模型会偏向新的数据,这个也很好理解,因为新数据占的比重最大,所以模型拟合的时候,肯定也是往数据多的分布去拟合,但是这种拟合的偏差是可以很容易的纠正过来,这就是这篇文章的核心: Bias Correction,直接在 FC 层进行 Bias 的纠正:

如上图所示,文章里将混合数据分成两部分,一部分是训练集,一部分是验证集,这两部分都包含了历史数据
和新数据
,训练集用来训练整个模型,而验证集用来对 FC 层进行纠正,纠正的方式也很简单:
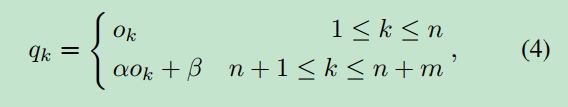
就是对于属于旧类别的数据,保持不变,而对于新类的数据,利用一个线性拟合的方式去纠正,在做 Bias Correction 的时候前面训练好的 CNN 和 FC 层都保持不变,这样相当于只是对最后的输出做了一个 correction,这个输出再通过交叉熵,在验证集上进行拟合,得到参数
这个方法虽然很简单,但是效果却非常惊艳,在 CIFAR-100 和 ImageNet 上都取得了很好的结果,具体的实验结果可以参考论文。
参考文献:
large scale incremental learning ,Yue Wu, Yinpeng Chen, Lijuan Wang, Yuancheng Ye, Zicheng Liu, Yandong Guo, Yun Fu
