Large-scale Distance Metric Learning with Uncertainty
Abstract
现有的大多数DML方法都采用点对约束或者三元组约束,在这种情况下约束的数量是原始样本的平方或者三次方,因此处理大规模数据集具有挑战性。此外,真实世界的数据可能包含各种不确定性,特别是对于图像数据。不确定性可能会误导训练过程并导致模型性能下降。通过观察图像数据,作者发现可以从一小组具有不同失真的干净潜在示例中观察到原始数据。在这项工作中,作者提出了margin preserving 度量学习框架,该框架同时学习距离度量和潜在示例。通过利用潜在示例的理想属性,可以显着提高培训效率,同时学习度量也对原始数据的不确定性变得强大。此外,作者证明从潜在的例子中学习度量同样适用于原始数据。基准图像数据集的实验证明了该方法的有效性和高效性。
问题提出
给定一组成对约束条件,DML试图学习一个度量标准,使得来自同一类的示例之间的距离足够小(小于预定义的阈值),而不同的距离之间的距离足够大。 三元组约束由三个例子组成 ,其中 和 具有相同的标签, 来自不同的类。 一个理想的度量可以将 从 和 中大幅推开。 目前DML面临两个挑战:
- 三元组约束规模:使用三元组约束的数量可以高达 ,其中n是原始训练示例的数量。它使DML在计算上难以处理大规模问题。目前解决方案大概为两类:1)通过随机梯度下降(SGD)进行学习;2)使用活动集进行学习。 通过SGD的策略,DML方法可以在每次迭代时仅采样一个约束或者一小批约束来观察完整梯度的无偏估计,并避免从整个集合计算梯度。其他方法通过一组活动约束(即违反当前度量)来学习度量,其中大小可以比原始集合小得多。 这两种策略都可以缓解大规模的挑战,但有固有的缺点。 基于SGD的方法必须搜索整个三元组约束条件,这会导致收敛缓慢,特别是当活动约束条件很少时。 另一方面,依赖于活动集的方法必须在每次迭代中识别集合。 不幸的是,这个操作需要计算与当前度量的成对距离,其中成本是 ,并且对于大规模问题而言太昂贵。
- 数据的不确定性:对于图像数据来说,姿态,照明和噪声等失真可能会造成数据的不确定性。 直接使用原始数据进行学习会导致较差的泛化性能,因为该度量标准倾向于过度拟合数据中的不确定性。 通过研究发现,大多数原始图像可以被具有不同失真的数量较少的干净潜在样本代替,如下图。这一观察启发我们用潜在样本代替原始数据来学习度量。 潜在的例子是未知的,只有具有不确定性的图像可用。
作者提出了一个同时学习距离度量和潜在样本的框架,该框架充分探索了潜在样本的特性来解决上述挑战。首先,由于潜在样本的规模较小,识别活动集的策略在学习该度量时变得可承受。我们通过避免尝试不活动的约束来加速学习过程。此外,与原始数据相比,潜在案例的不确定性显着下降。因此,直接从潜在案例中学习的指标可以关注数据的属性,而不是数据中的不确定性。为了进一步提高鲁棒性,我们采用了大量的边际属性,即不同类别的潜在示例应该被数据依赖边缘排除。图1说明,潜在样本的适当边际也可以保留原始数据的大量边际。我们对包括具有挑战性的ImageNet数据集在内的基准图像数据集进行实证研究,以证明所提出方法的有效性和有效性。
Margin Preserving Metric Learning
对于样本
,学习一个满足三元组约束的度量:
其中 ,M是PSD矩阵。
对于大规模图像数据集,作者假设每个观察到样本来自均值为零的失真样本,即:
其中 将原始数据投影到其相应的潜在示例。
然后,我们考虑观察数据和目标之间的期望距离,即学习一个这样的度量:
定义 , 和 分别表示 , 和 的潜在示例。 对于同类样本之间的距离,我们有
最后一个等式是由于 和 是独立同分布,因为它们来自同一个类。
同样,我们也可以得到不相似点对之间的距离
组合方程2和方程3,我们发现原始三元组中的距离之间的差异可以低于由三个潜在例子组成的三元组中的距离,因此可以得到
因此,可以通过在潜在示例上定义的约束来学习度量
该目标函数下学到的度量满足原始数据对应的目标函数(即Eq1)。 与原始约束相比,潜在实例之间的边际增加了因子 。 该术语表示原始数据与其相应的潜在示例之间的预期距离。 这意味着本地集群越紧密,应该增加的边际越少。 此外,由于原始数据的分布不同,因此每个类别都有不同的边际,比全局边际更具灵活性。
引入三元组约束 ,我们可以将优化问题重写为
其中m是潜在示例的数量且 。 我们为学到的度量添加F范数以防止过拟合。 是损失函数,在这里采用hinge loss。即:
这个问题很难解决,因为度量和潜在的例子都是要优化的变量。 因此,我们建议以交替的方式解决它,详细步骤如下所示。
暂略。
实验
对比方法:
- :具有欧几里德距离的3-NN。
- :最先进的DML方法,可在每次迭代中用当前度量标识一组活动三元组。 对于每个示例,在三个最近的邻居内搜索活动的三元组。
- :在线DML方法,每次迭代接收一个随机三元组。 它只在三元组约束处于活动状态时更新度量标准。
- :使用SGD的最有效的DML方法之一。 我们采用在比较中每次迭代时随机抽取一小批三联体的版本。 采样后,生成一个伯努利随机变量来决定是否更新当前度量。 通过PSD投影,它可以保证在每次迭代中学习的度量在PSD锥体中。
- :该方法同时学习度量和潜在示例,其中τ表示潜在示例数量和原始数量之间的比率 与其他方法不同,3-NN是以潜在实例作为参考点来实现的。 采用3-NN与原始数据的方法称为 。
MINIST
数据集介绍
该数据集由60000个训练集和10000个测试集组成。 数据集中有10个类,它们对应于数字0-9。每个样本是28×28灰度图像,这导致784维特征,并且它们被归一化为[0,1]。
实验一:
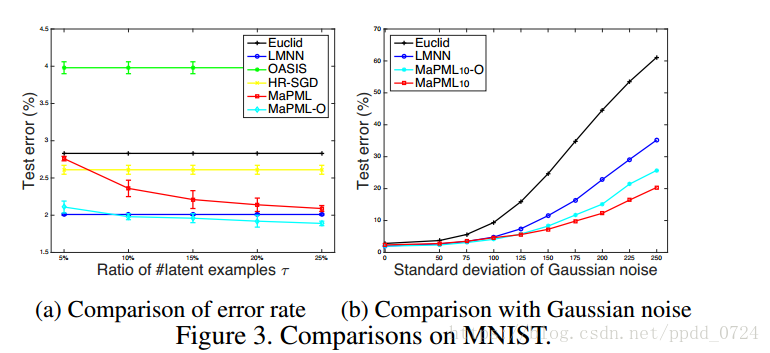
上图(a)比较了在测试集上不同度量的错误率。对于MaPML,作者将潜在样本的比例从5%变为25%。首先,使用活动集学习的结果优于随机三元组结果(OASIS>HR-SGD>LMNN)。它证实随机抽样三元组的策略不能充分探索数据集,因为三元组数量极大。其次, 的性能与LMNN相当,表明所提出的方法只需少量潜在实例(即10%)即可学习好的度量。当潜在示例数量较少时,潜在示例的kNN性能比整个训练集略差。但是,具有潜在示例的k-NN在实际应用中可以更加健壮。
为了证明鲁棒性,我们进行了另一个实验,将零均值高斯噪声(即 )随机地引入原始训练图像的每个像素。高斯噪声的标准差范围为[50/255,250/255], 固定为10。图3(b)显示当噪声级别较低时,MaPML10、MaPML10-O和LMNN性能相当。随着噪声的增加,LMNN的性能急剧下降。这可以通过以下事实来解释:用原始数据学习的度量被噪声信息误导。相比之下,MaPML和MaPML-O所产生的错误适度增加,这表明学习的度量比从原始数据中学习的度量更强大。 MaPML在所有方法中表现最好,这是由于潜在示例中的不确定性远远低于原始方法中的不确定性。这意味着具有潜在实例的k-NN更适合于具有很大不确定性的实际应用。
实验二:
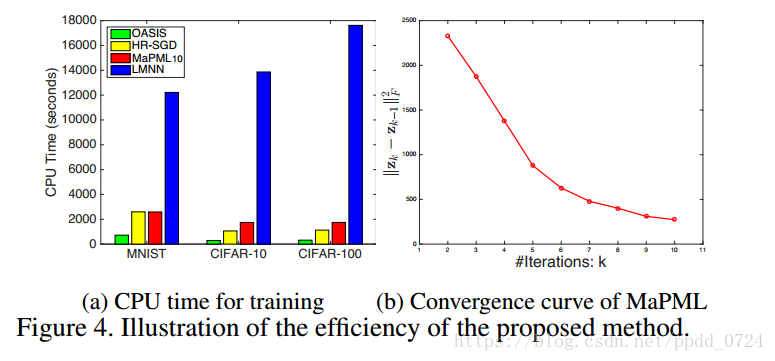
图4(a)显示了不同算法的CPU时间。如预期的那样,使用SGD的所有算法都比LMNN更有效,LMNN必须在每次迭代时从重新定义的活动集计算完整梯度。 此外,MaPML10的运行时间与HR-SGD的运行时间相当,这表明了MaPML的一小部分潜在示例的效率。 请注意,OASIS具有极低的成本,因为它允许内部度量超出PSD锥体。 图4(b)说明了MaPML的收敛曲线,并表明所提出的方法在实践中快速收敛。

最后,由于我们将所提出的方法直接应用于原始像素特征,所学习的潜在示例可以作为图像被恢复。 图5说明了原始训练集中学习到的潜在示例和相应示例。 很显然,原始示例来自具有不同扭曲的潜在示例。
CIFAR-10 & CIFAR-100
数据集介绍
CIFAR-10包含10个类别,包含50000个32×32大小的彩色图像用于训练,10000个图像用于测试。
CIFAR-100在训练和测试中具有相同数量的图像,但是具有100个类别。
由于深度学习算法在这些数据集上表现出压倒性的性能,因此我们采用Caffe中的ResNet18作为特征提取器,该网络在ImageNet ILSVRC 2012数据集上进行预训练,最终每个图像被表示为一个512维的特征向量。
实验一
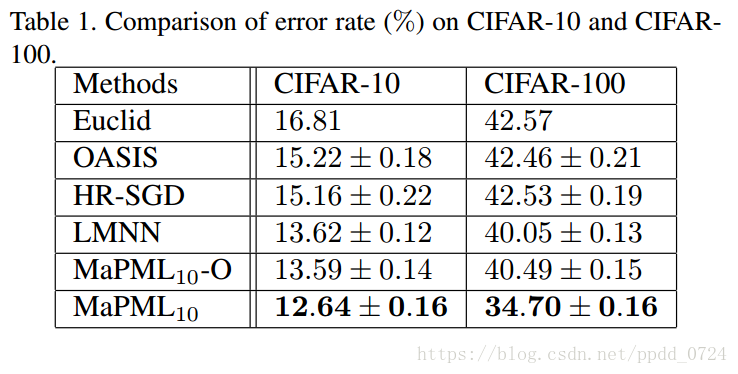
表1总结了比较中方法的错误率。 首先,我们有与MNIST相同的观察结果,其中采用活动三元组的方法的性能比具有随机取样三元组的方法的性能好得多。 与MNIST不同,MaPML10在两个数据集上都优于LMNN。 这是因为这些数据集中的图像描述的自然对象比MNIST中的数字含有更多的不确定性。 最后,MaPML10-O的性能优于OASIS和HR-SGD,这表明学习的度量可以与由深度特征表示的原始数据很好地协作。 它证实即使对于原始数据也保留了大额保证金财产。
ImageNet
数据集介绍
ImageNet ILSVRC 2012包含1,281,167个训练图像和50,000个验证数据。 对每幅图像应用与上述相同的特征提取过程。 鉴于大量的训练数据,我们将OASIS和HR-SGD的三元组数增加到106.相应地,用于解决MaPML中的子问题的最大迭代次数也提高到了105。
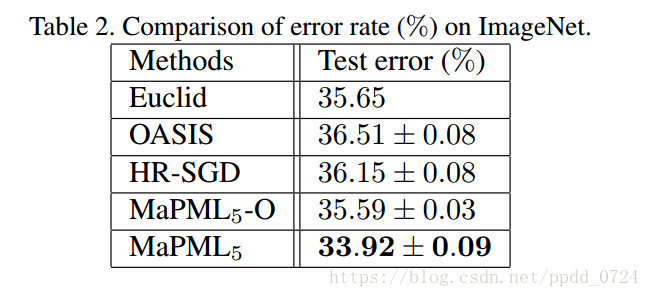
LMNN在24小时后没有完成训练,所以没有报告结果。 相反,MaPML在大约一个小时内获得度量。由于ResNet18在ImageNet上进行了培训,提取的功能针对此数据集进行了优化,并且很难进一步提高性能。 但是,通过潜在的例子,MaPML可以进一步将错误率降低1.7%。 这表明具有低不确定性的潜在实例更适合于大规模数据集作为参考点。 请注意,少量的参考点也将加速测试阶段。 例如,使用原始组合预测图像的标签花费0.15s,而使用潜在示例评估花费仅为0.007s。 它使MaPML具有潜在实例成为实时应用的潜在方法。
结论
作者提出了一个同时学习度量和潜在样本的框架。 通过对少量清晰的潜在样本进行训练,MaPML可以高效地对活动三元组进行采样,并且获得的模型对现实数据中的不确定性具有鲁棒性。 MaPML仅通过潜在示例进行学习时,可以保留原始数据较大的边际属性。 并通过实验证实了该算法的效率和性能。此外,将提出的策略结合到深度量度学习中也是一个有吸引力的方向。 它可以加速深嵌入的学习,并且潜在的例子可以进一步提高性能。
参考文献:Qian Q, Tang J, Li H, et al. Large-scale Distance Metric Learning with Uncertainty[J]. 2018.