转自我和朋友们的微信公众号:AI圈终身学习(ID:AIHomie),欢迎加入打卡群一起学习。
0. 写在前面
数据分析这项技能,对于比赛或者说服同事上司都是非常有意义的。但是在自然语言处理领域的比赛当中,我们似乎已经有固定的pipeline:
- 去去低频词,选择合适的文本长度(文本预处理)
- 然后选点牛逼的词向量训练方法,做做加权或者拼接啥的(特征预处理)
- 套一些用烂的模型,最后融合(建模)
- 训练时打乱或者删词或者蒸馏(训练方式)
- 加上一些运气(比较重要)
这样就能取得不菲的成绩,所以很多人都不重视这个步骤。但是,要拿冠军,这些琢磨不可少。其实更多的原因,是难以找到自然语言处理的分析教程,又不想去啃一本书(低效)。今天有空看了Kaggle上的Quara赛题,看到一个不错的关于数据分析的kernel,在这里分享一下。
1. 任务介绍
这是Quara(国外知乎)在kaggle上的第二个比赛。总的来说这是一个二分类问题-根据用户的问题,判断用户的提问有没有灌水。我举个中文的例子,比如这样的问题**“川普说要来我这学python”**就属于灌水。我这里列全官方的解释,灌水问题有这样一些特点:
- 语气非中性,通过夸张、修辞或隐喻的语气去强调特定人群
- 存在藐视或有煽动性
- 信息虚假
- 用性信息吸引眼球
总的来说,灌水问题的提问者对问题答案毫无兴趣。
2 数据与类别查看
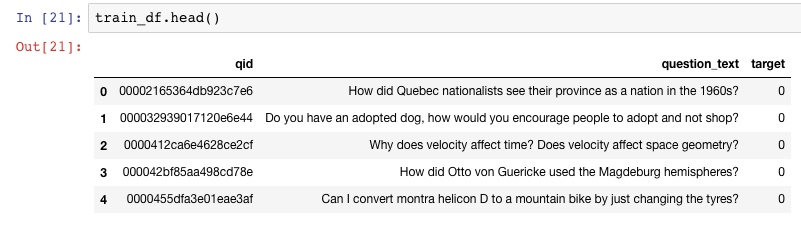
Quara赛题训练集中数据为130万条,先看前五条数据:
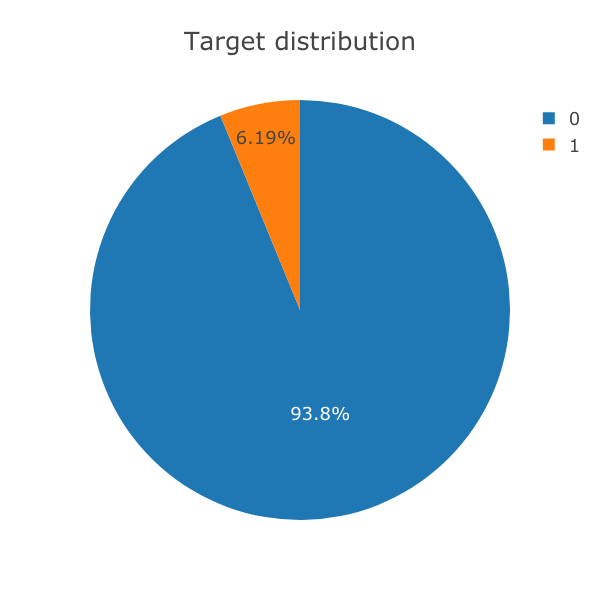
再看类别占比如下,大概6%的问题(target=1)属于灌水问题(insincere question),94%属于非灌水问题(sincere question):
3. 数据分析
每个任务分析数据时,我们要有这样几个问题:
- 数据类别有几种,分别占比是多少?(已经查看)
- 词在不同类别中是如何分布的?
- 哪些词是重要词?
- 词长是如何分布的?
- 我们如何选取特征?
- …
3.1 先看词云
我们先用词云看下语料中单个词词频的分布:

这些都是语料里的高频词。但是看着五花八门,花里胡哨,只能干瞪眼。所以一种方法是在每个类别里去看看高频词分别是哪些。
3.2 分类查看高频词
我们现在分类查看1-gram的词频分布,结果如下:
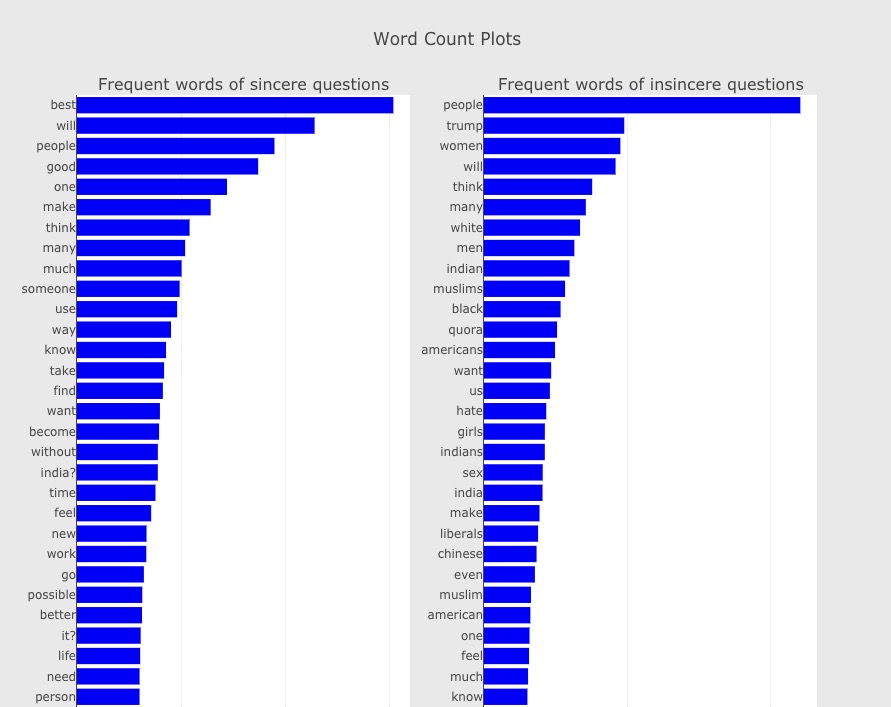
观察发现:
- 诸如’people’, ‘will’, 'think’等高频词在两个类别里都出现了。
- 只在非灌水问题中靠前的高频词有’best’, ‘good’。
- 只在灌水问题中靠前的高频词有’trump’, ‘women’, ‘white’。
是不是已经发现有点点意思了,至少我们可以跟老板说,全球人民(除了中国)在Quora上喜欢用川普来灌水。
我们现在分类查看2-gram的词频分布,差别就更大了,结果如下:
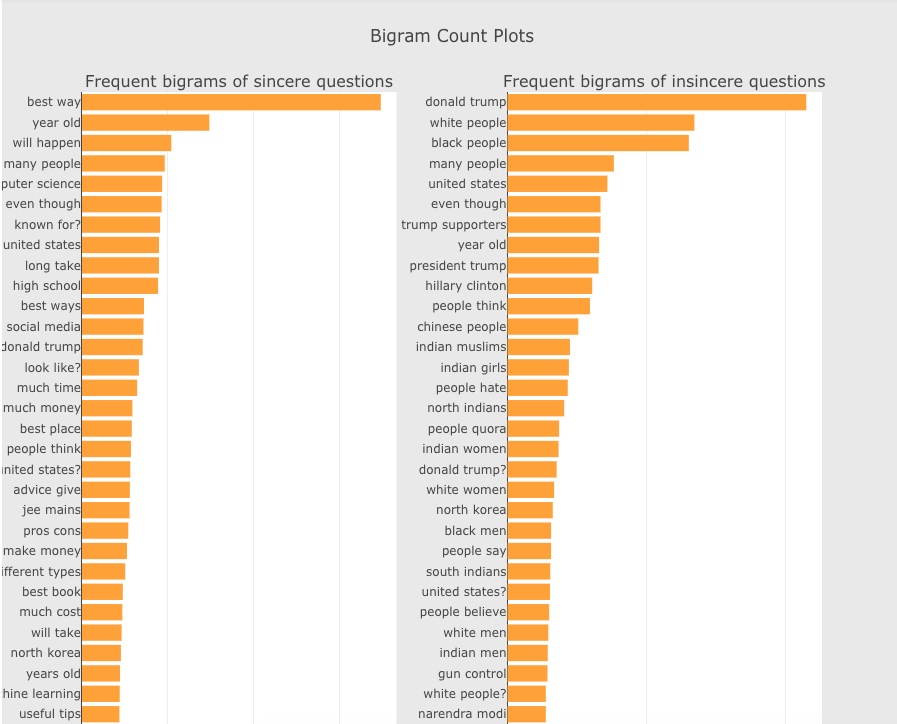
差别很明显,但是我们在工程中能怎么用呢?目前我也没有很好的方式。
3.3 分类查看词长
我们应该猜想,在不同的类别中,问题的词长分布会不会不一样呢?我们分别查看这样几种分布:
- 每个类中词数量(word)
- 每个类中字数量(char)
- 每个类中符号数量(punc)
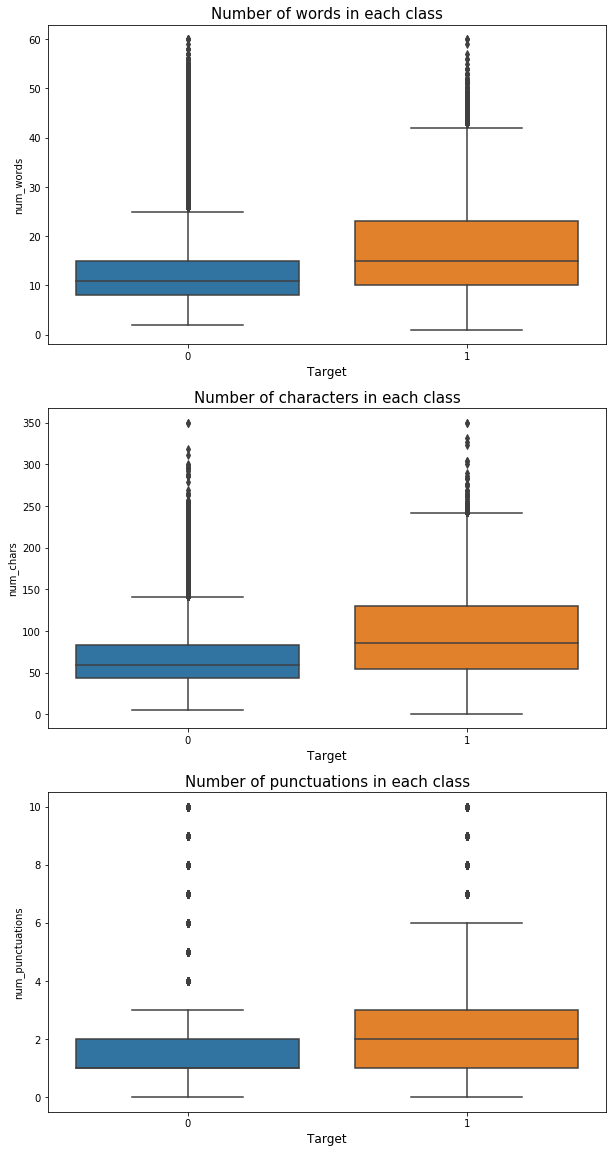
分析发现,灌水问题字符数量比非灌水问题多,因此这可以作为一个特征。
3.4 Baseline
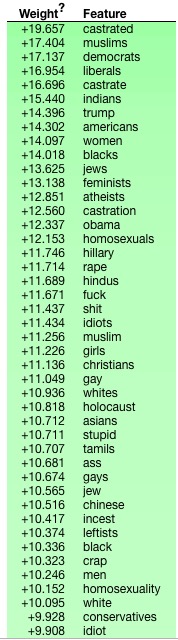
作者上面一顿操作猛如虎的分析过后,选择了和上面毫无关系的TFIDF特征加线性回归模型作为baseline,线下f1在0.60左右,基本没法看。但是通过eli5库查看对模型重要的词:
4. 结语
感谢您读到了这里,通过阅读全文,相信您也感觉到了数据分析在自然语言处理领域中的尴尬地位。看起来,数据分析看上去似乎是在把应该自动化的工作人工化,是会增加企业成本的一门技术。但是我依然觉得它现在非常重要的原因有:
- 团队汇报需要,表示你对任务有足够的了解
- 某个特征说不定能对模型有提升帮助
- 神经网络开发殆尽,未来越来越多的工作需要外部知识的帮助提升系统性能,因此对数据的分析是必不可少的
后面有时间我们会发布我们的baseline,提前关注公众号不迷路。
因为部分文字和代码可能作者写的不清楚,如果您有任何问题,您可以在我们的知识星球或者微信群里直接提问。没有问题也欢迎加入一起学习。



