今天看了kaggle竞赛:quora question pairs的一个解决方案,受益匪浅,在此记录一下作者的解题思路。
一、quora question pairs简介
首先,介绍一下quora question pairs任务:
train_set格式:

test_set格式:

quora question pairs任务的主要内容是:训练model,判定question1和question2是否表达同一个意思,表达同一个意思,label=1,or else,label=0。
二、quora question pairs feature engineering思路
1、预处理
(1)规范一些写法:




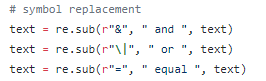

(2)去除停用词
(3)stemming
(4)text.lower()
2、feature engineering
(1)statistics feature
-
抽取question1,question2中not的数量,并根据question1,question2中not数量是否>0,构建一个feature list fs:
如果两个question的not数量均大于0,fs.append(1) else fs.append(0)
如果两个question的Not数量仅有一个大于0,fs.append(1) else fs.append(0)
如果两个question的not数量呈如下形式 count_i < 0 < count_j,则fs.append(1) else fs.append(0)
最后得到的len(fs)=3 -
question1和question2中share word 数量占question1和question2 word总数的比例:(share_1_to_2 + share_2_to_1)/(sum_1 + sum_2)
-
加入 idf 权重的 share_word/total_word:
idf[word] = math.log(num_docs / (idf[word] + 1.)) / math.log(2.)
sum_shared_word_in_q1 = sum([q1words[w] * self.idf.get(w, 0) for w in q1words if w in q2words])
sum_shared_word_in_q2 = sum([q2words[w] * self.idf.get(w, 0) for w in q2words if w in q1words])
sum_tol = sum(q1words[w] * self.idf.get(w, 0) for w in q1words) + sum(q2words[w] * self.idf.get(w, 0) for w in q2words)
share_word/total_word = [1.0 * (sum_shared_word_in_q1 + sum_shared_word_in_q2) / sum_tol] -
两个question的char length和word length
-
两个question的char length之差
-
两个question的char length之比: min/max
-
计算subset中word在subset中出现的频率:word_num/subset_num:可以表征word是否为common word,如果为common word,则其对于prediction可能意义不大
-
计算subset中word可以正确释义label的数量占word总数的比例:该比例越大,说明该word对label的指示性越强
-
计算单侧word的正确比例= (label=0)正确时word出现次数 / word在question1 or question2中出现的数量 :比例越大,说明该word对于label的预测能力越大
-
计算双侧word的正确比例= (label=1)正确时word出现次数 / word在question1 or question2中出现的数量 :比例越大,说明该word对于label的预测能力越大
-
计算word出现在question1 or question2中的数量占word总数的比例(label = 0)
-
计算word同时出现在question1 and question2中的数量 占 word总数的比例(label = 1)
-
将能显著预测label=1的那些word,是否同时出现在question中的情况进行tag,返回:如果word同时出现在question中,则tag.append(1) else tag.append(0)
-
将能显著预测label=0的那些word,是否同时出现在question中的情况进行tag,返回:如果word不同时出现在question中,则tag.append(1) else tag.append(0)。note that:该tag的length = subset中能显著预测label的word的个数
-
在label=1的sample中,questions中shared_word不能预测label的概率 = [1 - r for r in rate_list]
-
在label=0的sample中,questions中的diff_word不能预测label的概率 = [1 - r for r in rate_list]
-
返回question1,question2的tfidf [sum, mean, len]
-
返回question1和question2是否相等的情况
首先,定义question1 =1
如果question2 != question1,则question2 = 1 else question2 = 0 -

-
question1, question2中[a-z]字符的个数,以及2者char数量的差值
-
question1,question2中 1gram,2gram,3gram,4gram的jaccard_coef(q1,q2)
-
两个question之间的distance [question_distance , word_stem_distance]
-
两个question的Ngram distance
-
两个question是否同为问句(查看questions[0:1]的单词是否为表达问句的word,如:when,will, does, is)
(2)representation feature
- way1:利用sum(word_word2vec)表示两个question
- way2:利用sum(idf * word_word2vec)表示两个question
- 分别计算way1,way2下sentence的cosin_similarity
(3)nlp feature
以“树的形式”表征feature,下回分解
(4)graph feature
下回分解
(5)采用deep learning的方式,计算question1,question2的相似度
- 采用Siamese architecture计算两个question的相似度(Siamese architecture常用在图像检索中),Siamese architecture结构如下:
将questions的word2vec输入CNN中抽取特征,然后在进行fully connected,最后,计算二者的cosin_similarity

- Interaction based model
计算两个questions的interaction matrix,然后抽取interaction matrix的特征,最后根据抽取的特征计算两个questions的相似度

三、quora question pairs model方案

四、post_process
下次分解