文章链接:https://www.ixueshu.com/document/22cde1e97521595bc36aadb3dd6ff858318947a18e7f9386.html.
文章主要工作
- 论述了构建网络安全知识库的三个步骤,并提出了一个构建网络安全知识库的框架;
- 讨论网络安全知识的推演
1.框架设计
总体知识图谱框架如图1所示,其包括数据源(结构化数据和非结构化数据)、信息抽取及本体构建、网络安全知识图谱的生成:
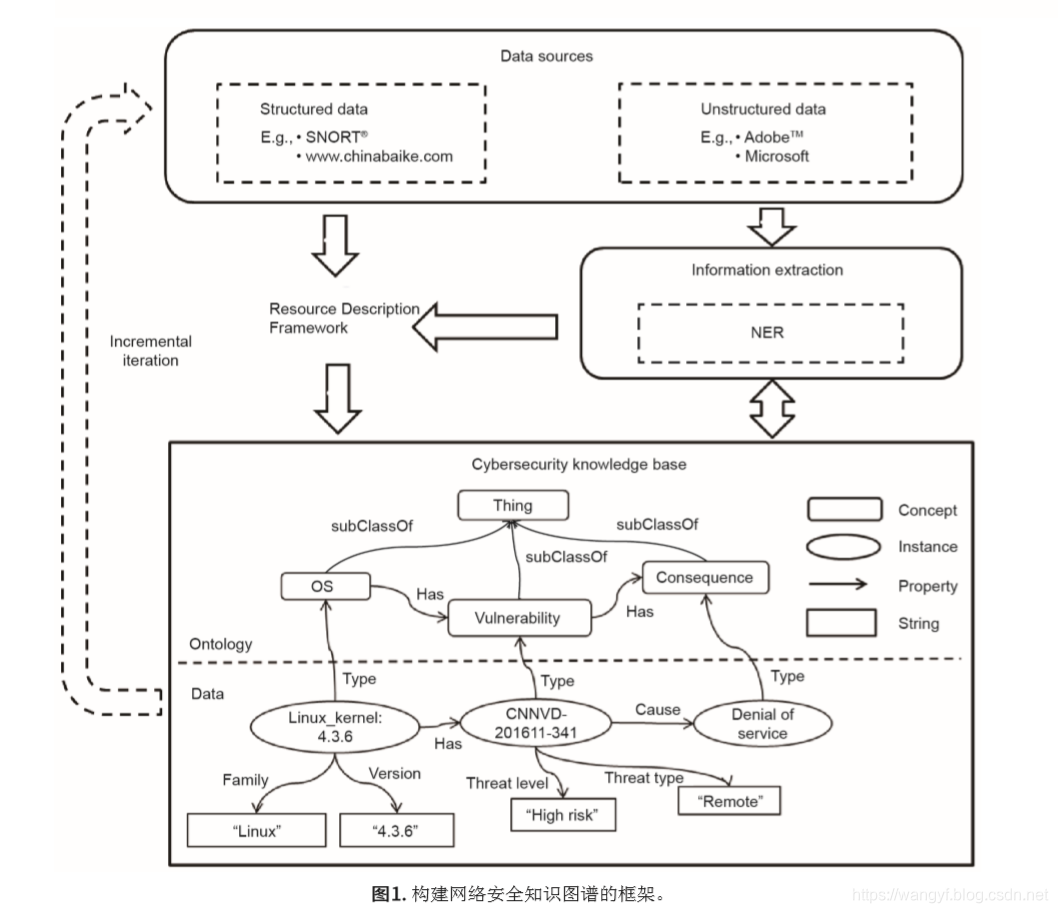
1.1 网络安全本体构建
文中提出了一个基于网络安全知识库的五元组模型,该模型包含:概念、实例、关系、属性和规则。网络安全知识库的架构如图2所示。
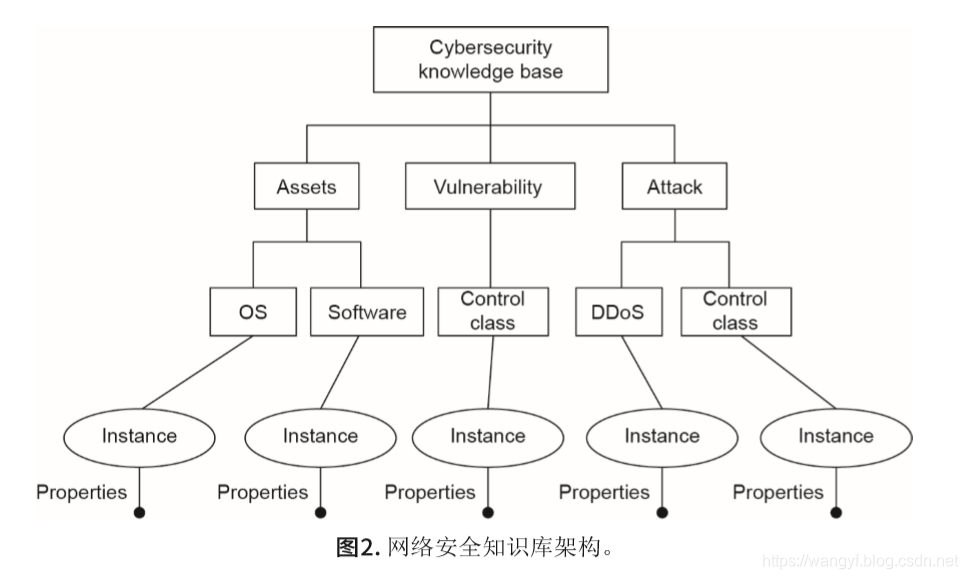
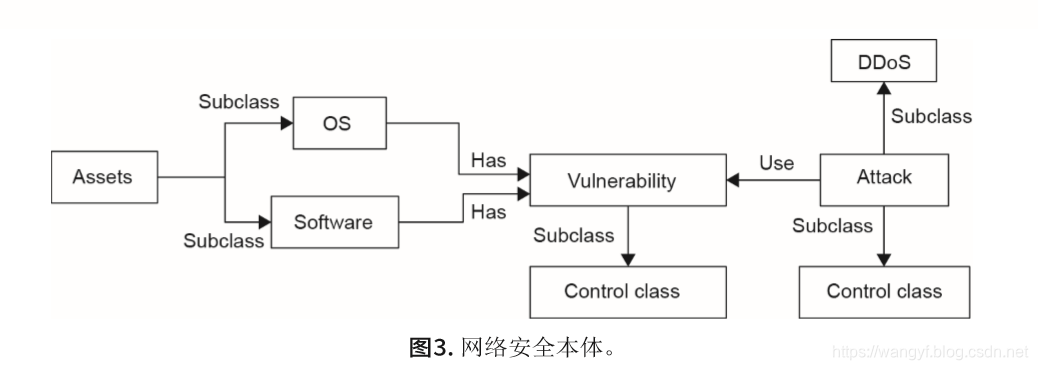
该架构如图2所示,其中包括三个本体:资产(Assets)、漏洞(Vulnerability)和攻击(Attack)。图3表示网络安全本体,其中包含五个实体类型:漏洞、资产、软件、操作系统、攻击。
1.2 基于机器学习提取网络安全相关实体
由于条件随机场模型(CRF)保留了条件概率框架的优点,如最大熵Markov 模型,也解决了标记偏差的问题,所以适用于命名实体识别。
Stanford NER提供了线性链条件随机场(CRF)序列模型的一般实现,于是文中使用它来提取网络完全相关的实体。下面是Stanford NER的一些主要特征:
- UseNGrams:利用n-gram取特征,即词的子串。
- MaxNGramLeng:这个特征的值类型为整型。如果这个特征的值为正,则大于该值的n-gram将不会在 模型中使用。在本文中,我们将maxNGramLeng的值设 置为6。
- UsePrev:这可以给我们提供<previous word, class of previous word>的特征,并与其他选项一起启用, 如<previous tag,class>。这导致基于当前单词与一对< previous word,class of previous word >之间的关系的特 征。当有连续的词属于同一个类时,这个特征将是非常 有用的。
- UseNext:和UsePrev特征非常相似。
- UseWordPairs:这个特征基于两个词对—— <Previous word,current word,class> 和 <current word, next word,class>。
- UseTaggySequences:这是一个重要的特征,它 使用类的序列而不是单词的集合,而是使用第一、第二 和第三顺序类和标签序列作为交互特征。
- UseGazettes:如果为真,则由下一个名为“gazette”的特征将把文件指出为实体字典。
- Gazette:该值可以是一个或多个文件名(以逗 号、分号或空格分隔的名称)。如果从这些文件加载公 开的实体词典,每行应该是一个实体类名称,后跟一个 空格,后面再跟上一个实体。
- CleanGazette:如果这个值为真,则仅当全部词 在字典中被匹配时,此特征才会触发。如果在字典中 有一个词“Windows 7”,那么整个词应该在字典中进 行匹配。
- SloppyGazette:如果这个值为真,词和字典中 的词局部匹配也能触发这个特征,如“Windows ”可以 和“windows 7”进行匹配。
2. 知识推演
2.1 数据源
- 漏洞的来源:CVE、NVD、 SecurityFocus、CXSECURITY、Secunia、中国国家漏 洞数据库(CNVD)、 CNNVD和安全内容自动化协议中 国社区(SCAP)。
- 攻击的数据来源
(1).一类来自信息安全网站,其中包括Pediy BBS、Freebuf、 Kafan BBS和开放Web应用安全项目(OWASP);
(2).另一 类来自企业自建信息响应中心,包括360安全响应中心 (360SRC)和阿里巴巴安全响应中心(ASRC)。
2.2 属性推演
如图4所示,图中有三个实例:Ni、Nj和Nl,每一个实例对应一对(key,values)值。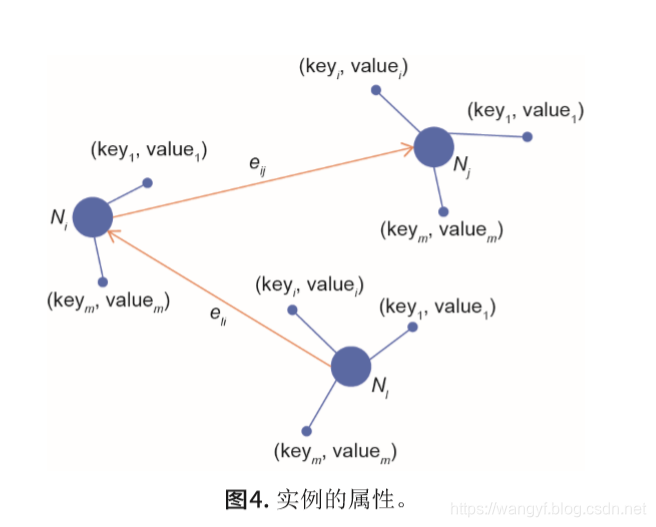
属性值Valueik的 预测公式如下:
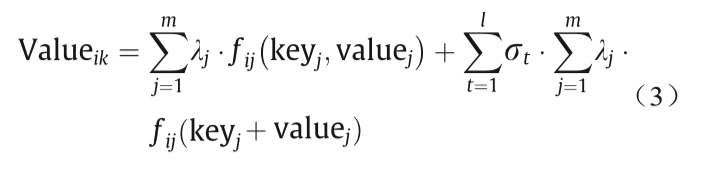
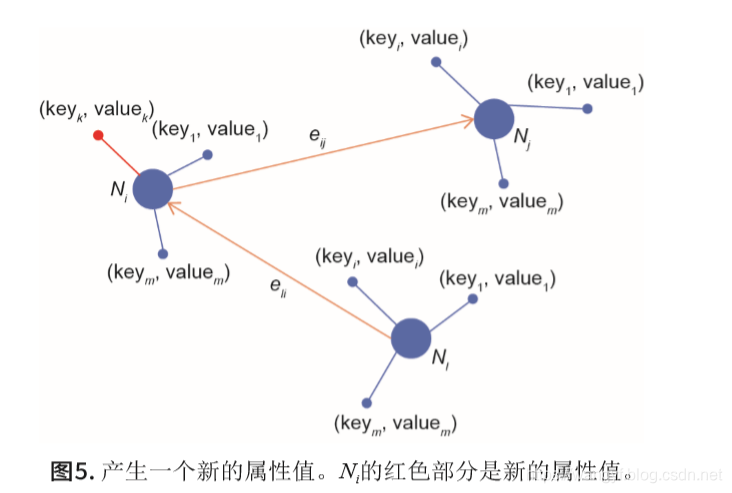
对于实例Ni,通过计算下述公式可以得到新的属性,如图5所示。
2.3 关系推演
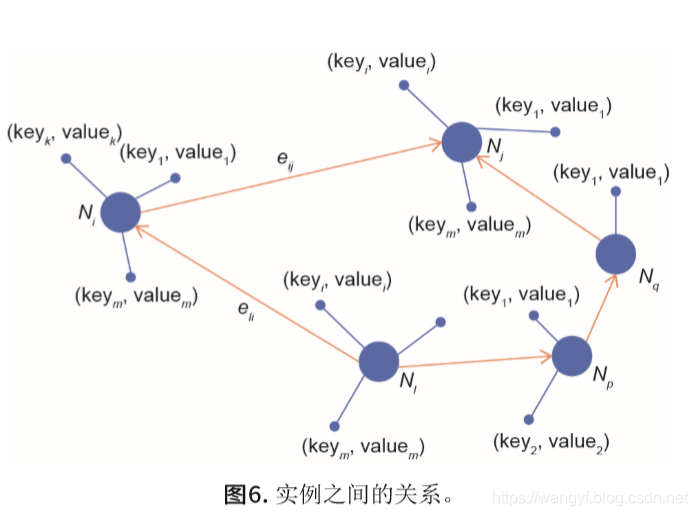
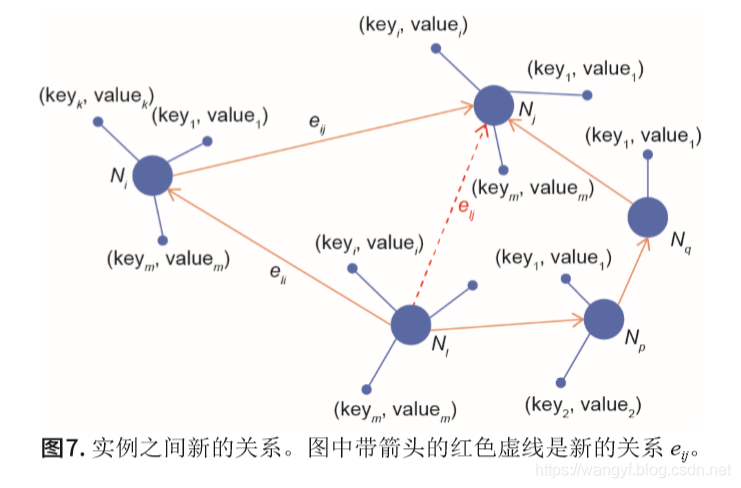
常用推理方法有三种:基于嵌入的技术、基于低维 向量表示和路径排序算法。在本文中,我们选择使用路径排序算法。路径排序的基本思想是使用连接两个实体的路径作为特征来预测两个实体之间的关系。实例Ni、Nj和Nk 之间的属性值和关系如图6所示。
关系推理的预测公式如下:
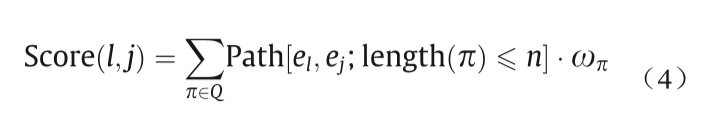
式中,π为所有从l到j的可达路径,length(π)≤n。如果 Score(l, j)≥τ,τ为阈值,则elj成立;否则不成立。通过路径排序算法可以得到新的关系,如图7所示。
2.4 评估标准
在信息检索和提取系统中,有两个主要的评估指 标,包括精确率和召回率。有时,为了全面评估系统的性能,通常计算精确率和召回率的调和平均值。这就是我们通常所说的F-Measure。在本文中,我们使用 F-Measure的特殊形式F1值。精确率、召回率和F1值由真正、假正和假负定义。定义如下:
- 真正(TP):将正类预测为正类数。
- 假正(FP):将负类预测为正类数。
- 假负(FN):将正类预测为负类数。
精确率(Precision)由以下公式给出:
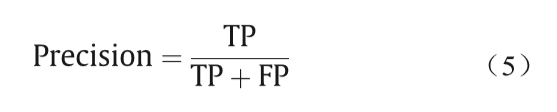
召回率(Recall)由以下公式给出:

F1值由以下公式给出:
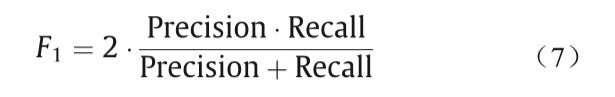
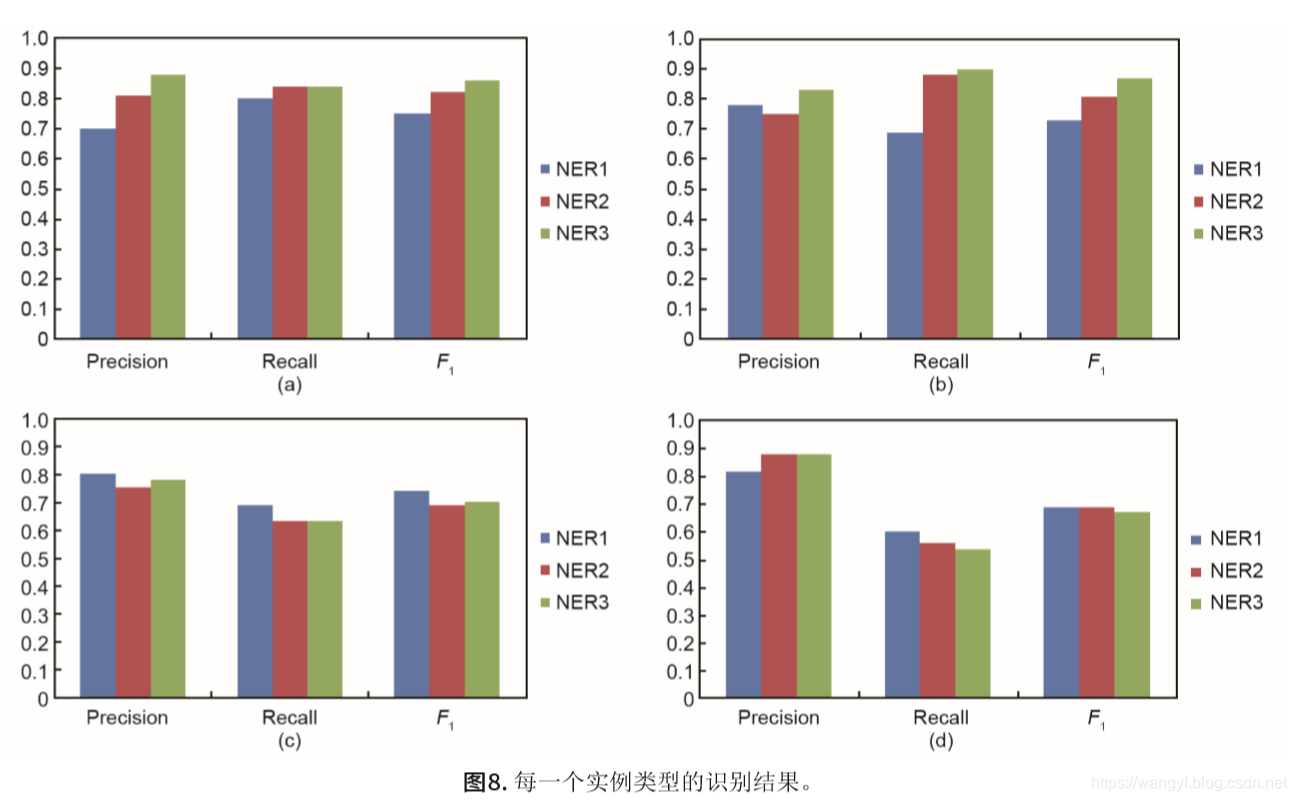
2.5 实验结果(主要复制文章细节)
为了验证useGazettes的影响,我们建立了三个模型 (NER1、NER2和NER3)。
- NER1没有使用useGazettes作为它的特征
- NER2使用useGazettes,并选择了cleanGazette选项
- NER3也使用了useGazettes,但是它选择了 sloppyGazette选项。
然后,采用了10倍交叉验证的方法 来评估这些模型,将数据分成10个数据块,将十分之九的块用作训练数据,其余用作测试数据。
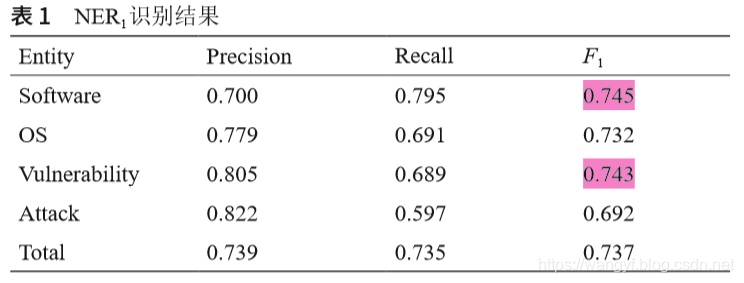
NER1的平均识别结果如表1所示,该表显示结果的精度相对较高。对于F1度量,软件和漏洞的识别率相近,且高于其他任何实体类型,也就是说, 软件和漏洞的识别在整体识别效果方面取得了良好的表现。
然后,我们使用了包含useGazettes的特征,并选择 了cleanGazette的选项来训练NER2。NER3是根据包含 useGazettes和sloppyGazette两个选项的特征进行训练的。 平均识别结果如表2所示。
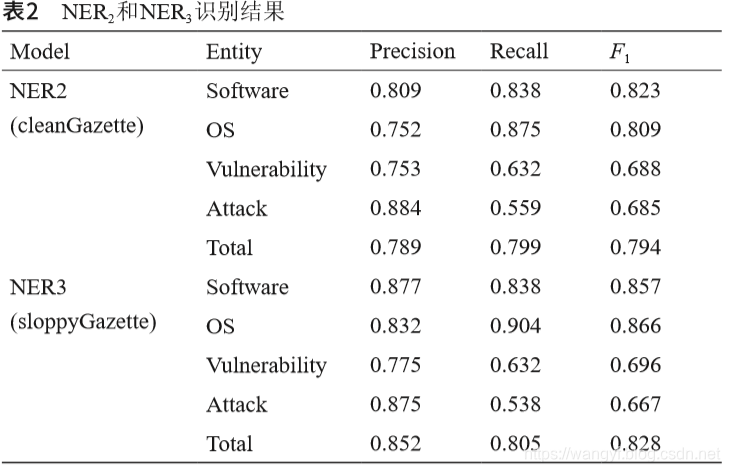
如表2所示,在NER2的识别结果中,对软件的识别取得了良好的整体表现。对于NER3,OS的识别实现了高F1值。就软件和操作系统的认可而言,NER3的整体 性能比NER2好。这个结果表明sloppyGazette选项有助于识别与网络安全相关的实体。NER2和NER3的后果和平均值的F1测量值仍然很低,均小于70%。图8给出了这三种模型之间的直观比较。