知识图谱应用如图所示,目前各大互联网公司已落地多个知识图谱产品,或者正在积极构建知识图谱,图谱技术成为“兵家必争”之地。
1. 什么是知识图谱?
知识图谱(Knowledge Graph)的概念由谷 歌 2012 年正式提出,旨在实现更智能的搜索引擎,并且于 2013 年以后开始在学术界和业界普及,并在智能问答、情报分析、反欺诈等应用 中发挥重要作用。
知识图谱以语义网( Semantic Web) 和领域本体( Ontology) 为其关键技术的大规模语义网络知识库。
Knowledge Graph是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系。其基本组成单位是“实体-关系-实体”三元组,以及实体及其相关属性-值对,实体间通过关系相互联结,构成网状的知识结构。Knowledge Graph本质是以语义三元组为基础的结构化的海量知识库。
知识图谱的定义让人不明觉厉,那实际构建的知识图谱是什么样子?

2. 知识图谱的几个关键概念
2.1 本体
领域术语集合。本体最为抽象,简单理解就是一堆概念,这堆概念集合能够描述某个具体的domain里的一切事物的共有特征,然后概念间又有一定的关系,所有构成一个具有层级特征的结构。所以在语义网里ontology和schema基本不分家。
在上面知识图谱的例子中,本体是足球领域schema
2.2 类型 type
具有相同特点或属性的实体集合的抽象,如足球球员、足球联赛、足球教练等。
2.3 实体
实体就是type的实例,如足球球员--梅西,足球联赛--西甲等。
2.4 关系
实体与实体之间通过关系关联起来,如梅西是巴塞罗那的球员。
2.5 属性
实体自带信息是属性,如梅西 出生日期 1987年6月24日, 身高 1.7米等。
2.6 知识图谱
图状具有关联性的知识集合。可以由三元组(实体entity,实体关系relation,实体entity)表示。
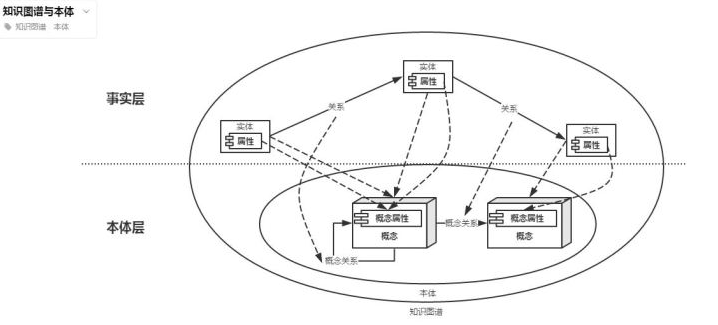
这幅图描述了知识图谱中的概念之间的关系。
2.7 知识库
知识库(Knowledge Base),就是一个知识数据库,包含了知识的本体和知识。Freebase是一个知识库(结构化),维基百科也可以看成一个知识库(半结构化),等等。知识图谱可以看成是由图数据库存储的知识库。
3. 工业界如何构建知识图谱?
- 美图知识图谱技术链:

- 转转的二手电商知识图谱构建

工业界的特点是它有细分的领域,有良好的业务模型,有大量的数据沉淀。他们一开始先构建Schema,数据有一部分来自于结构化数据,另外需要从半结构化、非结构化数据中获取知识。转转的知识图谱物品词库的构建,大部分数据来自 自有的结构化数据。
知识图谱本身就是图状的知识,关键就是知识获取,获取图中的元素:点、边,即抽取实体、关系。
4. 学术界如如构建知识图谱?
-
知识图谱构建流程

-
知识图谱技术
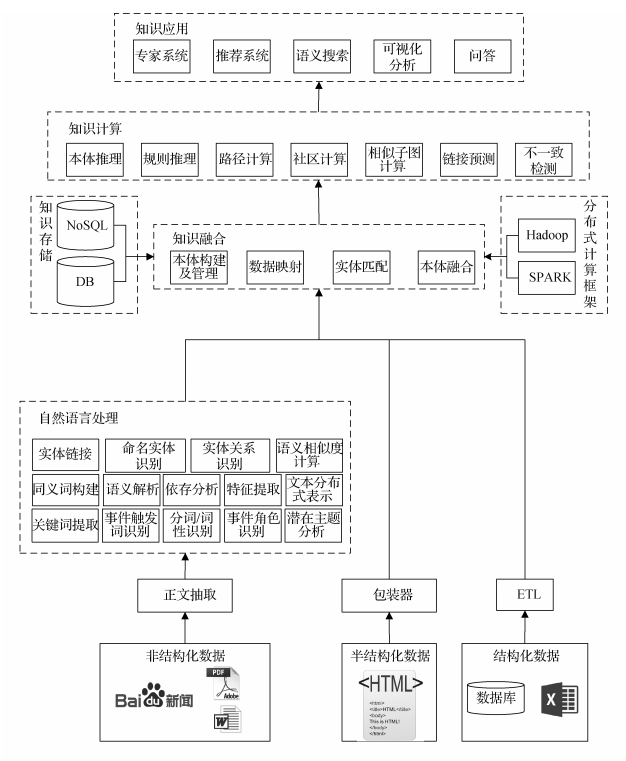
学术界是先抽取实体、关系,然后在这些数据的基础上进行本体抽取,而且难度比较大,涉及大量本体构建的工作。
5. 小结
本体的构建大体有两种方式:自顶向下和自底向上。
-
开放域知识图谱的本体构建通常用自底向上的方法,自动地从知识图谱中抽取概念、概念层次和概念之间的关系。这也很好理解,开放的世界太过复杂,用自顶向下的方法无法考虑周全,且随着世界变化,对应的概念还在增长。 其中最典型就是Google的Knowledge Vault。
-
领域知识图谱多采用自顶向下的方法来构建本体。一方面,相对于开放域知识图谱,领域知识图谱涉及的概念和范围都是固定或者可控的;另一方面,对于领域知识图谱,我们要求其满足较高的精度。现在大家接触到的一些语音助手背后对接的知识图谱大多都是领域知识图谱,比如音乐知识图谱、体育知识图谱、烹饪知识图谱等等。正因为是这些领域知识图谱来满足用户的大多数需求,更需要保证其精度。自顶向下是先为知识图谱定义好本体与数据模式,再将实体加入到知识库。该构建方式需要利用一些现有的结构化知识库作为其基础知识库,例如Freebase项目就是采用这种方式,它的绝大部分数据是从维基百科中得到的。
学术界的本体构建一般采用自底向下,工业界一般采用自顶向下的方式构建。
知识图谱的很多构建细节,在后续的文章中再详细展示。