利用python的包进行图像文字识别:
pytesseract的安装教程:https://blog.csdn.net/qq_36535820/article/details/103426054
导入pytesseract包
>>> import pytesseract
>>> from PIL import Image图像文字识别结果:
待识别图像:
图像11:
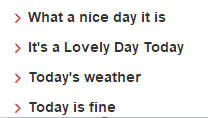
图像文字识别代码及结果:
>>> im11 = Image.open(r'E:\\公司文件\\11.png')
>>> print(pytesseract.image_to_string(im11))
> What a me day :1 Is
> Its a Lovely Day Today
> Today's weather
> Today Is nne图像12:

图像文字识别代码及结果:
>>> im12 = Image.open(r'E:\\公司文件\\12.png')
>>> print(pytesseract.image_to_string(im12))
ABCDEFG
HI JKLMN
OPQRSTU
VWXYZ图像13:

>>> im13 = Image.open(r'E:\\公司文件\\13.png')
>>> print(pytesseract.image_to_string(im13))图像14:

图像文字识别代码及结果:
>>> im14 = Image.open(r'E:\\公司文件\\14.png')
>>> print(pytesseract.image_to_string(im14))
JA,.,.,..»./wmwaxwu,
mu zémééaa/f.u~ru».4:t xx. wdganu/ruh. ,»6wK«
Iwyaé wifl m uni.»//nag»/-2‘: den}
/7 Mr’? he/-yd/¢. .,., 4... /M 1.1-/./Viym
vnu .4! W rrnww-ma, 4»; Am.» flu. flan.
tm._JA A A,/. 9/Am/yflé. jM4n’¢r1fAll:
arfvazH:fiu»«¢d/m mud, My/56¢
u-./ aw¢Auy.yyuam.mAfm,.., wy vngzmi
mm/aimzzsflum .4u(../.»«m,...;H: '
Ia-1;‘ mg; on. .2 aé:mz.Z7mm¢<,/w ea-rm". -1:43./:5-r
war m a mg, 41., «M».
50-‘ 47.57/24. J3.»»..§_{:m.‘i'/1 2.»;
: uyx %Vdz fl ..d.m, yfmm
vmwfi'H4£u.fM22w/ K/F07.‘Dtu Am 4,,,,g“,_
/I/71$]! Aim] 3*./11 {A44 /....4 Mia rs /u¥ m,
DWI‘-W012-gfil mm;
图像15:

图像文字识别代码及结果:
>>> im15 = Image.open(r'E:\\公司文件\\15.png')
>>> print(pytesseract.image_to_string(im15))
try V"J’L\/J ')v\ H
H4y/ o
1 eight
2 nine
» 3 ten
’ I . eleven
7 twelve
I ; thirteen
' fourteen
10
11
12
13
14
8
fifteen
sixteen
seventeen
eighteen
nineteen
twsnw
M twenty-(Mme
T,
15 ts
16 t]
17 f<
18 f
7195
205
216折腾了好久,仍然只是在cmd上面测试成功,且图像文字识别效果不是很好。针对书写的清晰英文识别率较高,对不清晰、潦草或位置摆放不恰当的图片英文文字内容识别率差差。还没测试图像中文识别效果,估计也不会太好。
当然这些图片未经过任何处理,在经过一定处理后的图片,图像识别率会提升,但提升多少还未有测试。我看博客有个博主推荐了一片大神写的代码实现图像处理,提高pytesseract图像文字识别率,大家可以去看看(我没实践过,不知道代码实际效果了)。
