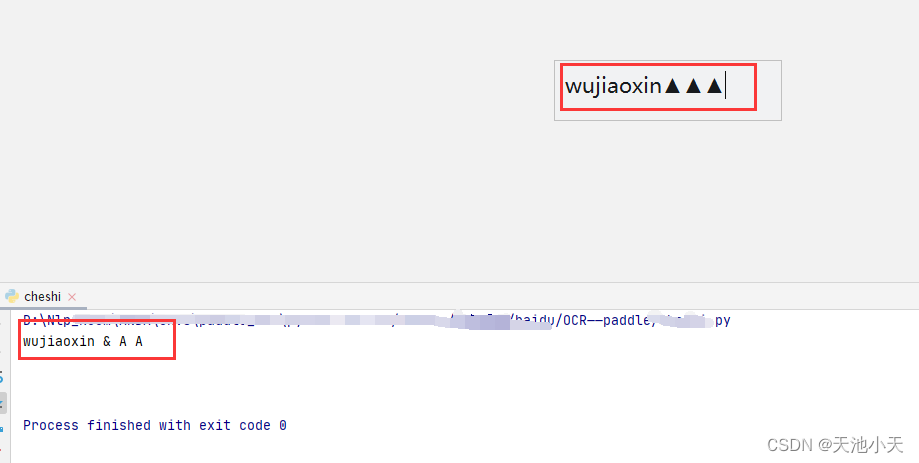
识别OCR 中特殊字符,如:五角星,桃心(图片)
Error:could not find a version that satisfies the requirement pytesseract
pytesseraot.pytesseraot.TesseractlotFoundError: tesseact is not installed or it's not in you PATH.See READNE file for mowe infonmEation
前言
一、解决方案–pytesseract
==ModuleNotFoundError: No module named ‘pytesseract‘=
pip install pytesseract无数次失败
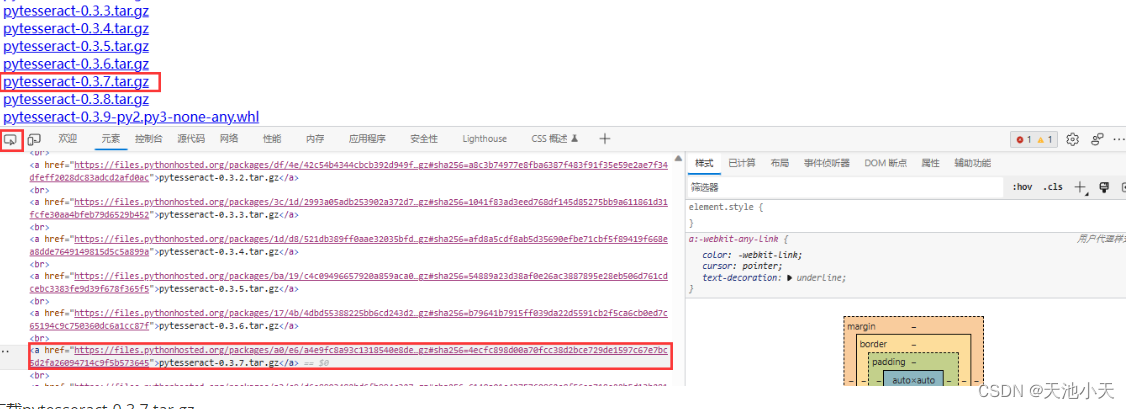
通过网页打开---->>Links for pytesseract (pypi.org)
如果下载不了,接下来点击F12 从元素下载
-
下载pytesseract-0.3.7.tar.gz
-
放到 “python安装路径”\Lib\site-packages\ 解压缩
-
进入pytesseract文件夹,里面有setup.py
-
在此处运行cmd,输入命令:
-
python setup.py install
解决方案-Tesseract
Tesseract是一个开源的OCR(Optical Character Recognition,光学字符识别)引擎
pytesseraot.pytesseraot.TesseractlotFoundError: tesseact is not installed or it's not in you PATH.See READNE file for mowe infonmEation.
异常原因:
仅仅是通过PIP工具安装了pytesseract库,并没有安装第三方OCR识别工具包,需要下载安装并进行环境配置
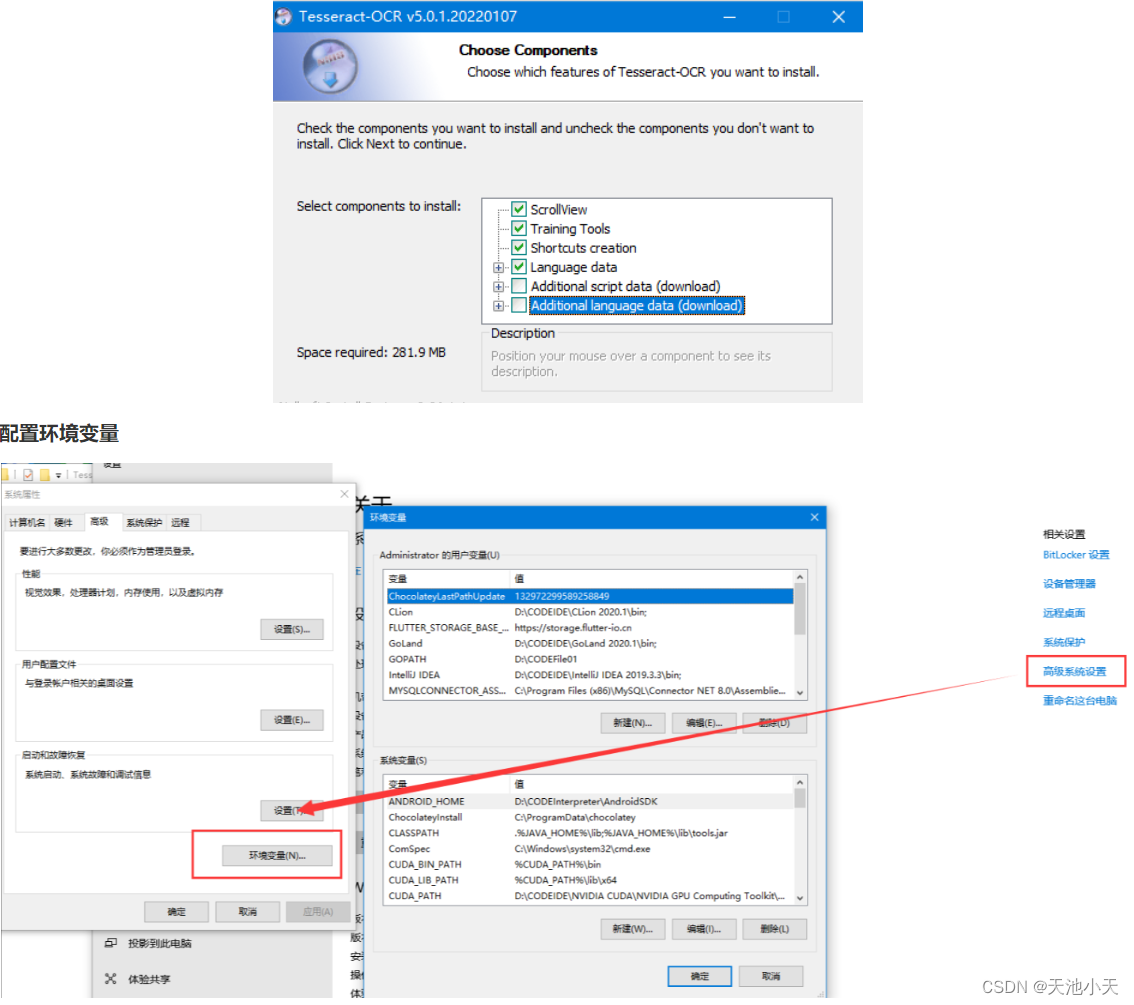
检测版本
检查版本,进入CMD,输入tesseract --version
C:\Users\Administrator>tesseract --version
tesseract v5.0.1.20220107
leptonica-1.78.0
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0
Found AVX512BW
Found AVX512F
Found AVX2
Found AVX
Found FMA
Found SSE4.1
Found libarchive 3.5.0 zlib/1.2.11 liblzma/5.2.3 bz2lib/1.0.6 liblz4/1.7.5 libzstd/1.4.5
Found libcurl/7.77.0-DEV Schannel zlib/1.2.11 zstd/1.4.5 libidn2/2.0.4 nghttp2/1.31.0
问题解决
代码演示
提取图片文字
from paddleocr import PaddleOCR, draw_ocr
from PIL import Image
# load model
# Paddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改 lang参数进行切换
# lang参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`
ocr = PaddleOCR(lang="ch",
use_gpu=False,
det_model_dir="../../paddleORC_model/ch_ppocr_server_v2.0_det_infer/",
cls_model_dir="../ch_ppocr_mobile_v2.0_cls_infer/",
rec_model_dir="../ch_ppocr_server_v2.0_rec_infer/")
# load dataset
img_path = 'image2.png'
result = ocr.ocr(img_path)
for line in result:
print(line)
问题: 桃心提取不到
解决方案:
from pytesseract.build.lib.pytesseract import pytesseract
from PIL import Image
# 读取图片
img = Image.open('image2.png')
pytesseract.tesseract_cmd='D:\\Nlp_Room\Tesseract-OCR\\tesseract.exe'
# 使用pytesseract识别图片中的文本
text = pytesseract.image_to_string(img)
# 输出识别结果
print(text)
可通过末尾计数