datawhale数据竞赛day01-认识数据
2019未来杯高校AI挑战赛 > 城市-房产租金预测”
认识数据
- 了解比赛的背景
- 分类问题还是回归问题
- 熟悉比赛的评分函数
对比赛数据做EDA
- 缺失值分析
- 特征值分析
- 是否有单调特征列(单调的特征列很大可能是时间)
- 特征nunique分布
- 统计特征值出现频次大于100的特征
- Label分布
- 不同的特征值的样本的label的分布
认识数据
背景:数据集中的数据类别包括租赁房源、小区、二手房、配套、新房、土地、人口、客户、真实租金等。
要求:建立模型,预测房屋租金,此问题是跟回归问题
比赛的评分函数:待了解
对比赛数据做ETA
一、缺失值分析
- 统计数据的总条数:41440
print(len(data_train))
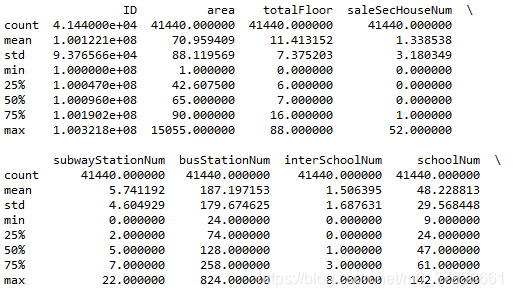
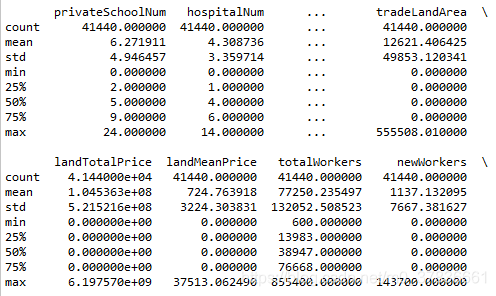
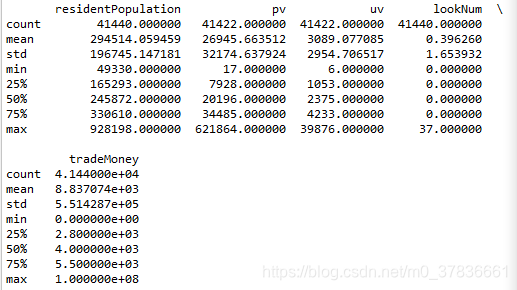
- 查看数据的基本情况
print(data_train.describe())
3. 查看有无缺失值
print(data_train.isnull().sum())
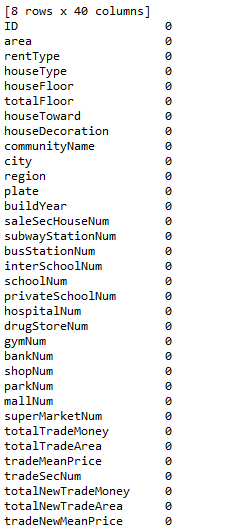

可见pv,uv缺失18条记录
函数式编程
"# 缺失值分析\n",
"def missing_values(df):\n",
" alldata_na = pd.DataFrame(df.isnull().sum(), columns={'missingNum'})\n",
" alldata_na['existNum'] = len(df) - alldata_na['missingNum']\n",
" alldata_na['sum'] = len(df)\n",
" alldata_na['missingRatio'] = alldata_na['missingNum']/len(df)*100\n",
" alldata_na['dtype'] = df.dtypes\n",
" #ascending:默认True升序排列;False降序排列\n",
" alldata_na = alldata_na[alldata_na['missingNum']>0].reset_index().sort_values(by=['missingNum','index'],ascending=[False,True])\n",
" alldata_na.set_index('index',inplace=True)\n",
" return alldata_na\n",
"\n",
"missing_values(data_train)"
二、特征值分析
大多数数据都是int或float型;有部分字段是object型,即文本型中文或英文的,如rentType字段,这些字段在之后需要做处理
-
定量数据
定量数据有:area,totalFloor,saleSecHouseNum,
subwayStationNum,busStationNum, interSchoolNum, schoolNum, privateSchoolNum,hospitalNum, drugStoreNum, gymNum, bankNum, shopNum, parkNum, mallNum, superMarketNum,totalTradeMoney ,totalTradeArea,tradeMeanPrice,tradeSecNum,totalNewTradeMoney,totaINewTradeArea,tradeNewMeanPrice,tradeNewNum,remainNewNum,supplyNewNum,supplyLandNum,supplyLandArea,tradeLandNum,tradeLandArea,IandTotalPrice,landMeanPrice,totalworkers,newWorkers,residentPopulation,PV,uv,lookNum -
定性数据
定性数据:rentType,houseType,houseFloor,houseToward,houseDecoration,communityName,city,region,plate,buildYear
三、是否有单调特征列
单调特征列很可能是时间,判断单调列,可以做类似时间序列,如果两个都是单调,可以探索他们的关系
def increasing(vals):
flag = 0
for i in range(len(vals) - 1):
if vals[i+1] > vals[i]:
flag += 1
return flag
cols = [col for col in data_train.columns]
for col in cols:
inc = increasing(data_train[col].values)
if inc/data_train.shape[0] >= 0.55:
print('单调特征:', col)
print('单调特征值个数:', inc)
print('单调特征值比例:', inc / data_train.shape[0])

四、特征nunique分布
此步骤是为之后数据处理和特征工程做准备,先理解每个字段的含义以及分布,之后需要根据实际含义对分类变量做不同的处理
定性数据
- rentType
print(data_train['rentType'].unique())
print(data_train['rentType'].describe())
data_train['rentType'].value_counts().plot(kind = 'pie')

4种,大多数都是未知方式
- houseType
print(data_train['houseType'].unique())
print(data_train['houseType'].describe())
print(data_train['houseType'].value_counts())

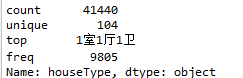


104种,大多数都是3室以下,其中1室1厅1卫的最多,2室1厅1卫和2室2厅1卫次之
- houseFloor
print(data_train['houseFloor'].unique())
print(data_train['houseFloor'].describe())
print(data_train['houseFloor'].value_counts())
data_train['houseFloor'].value_counts().plot(kind = 'pie')
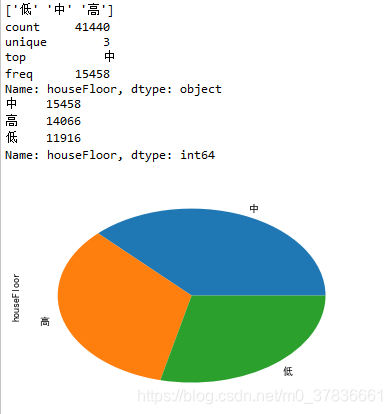
3种,分布较为均匀
-
houseToward

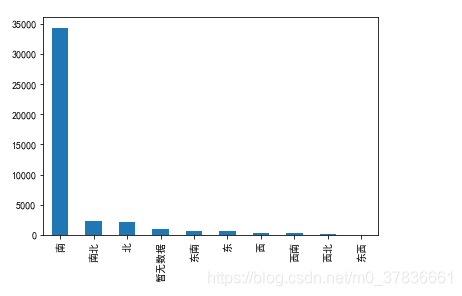
10种,朝南的最多 -
houseDecoration
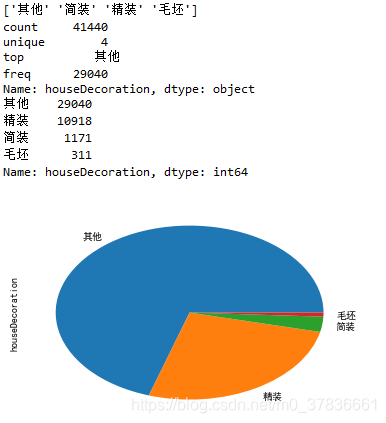
4种,大半是其他,精装次之 -
communityName
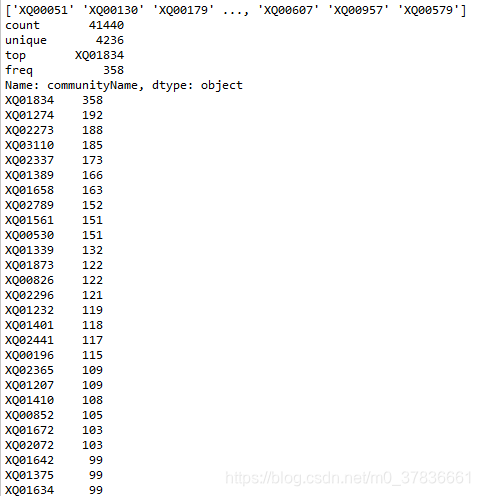

4236种,分布较为稀疏 -
city

全都在SH -
region
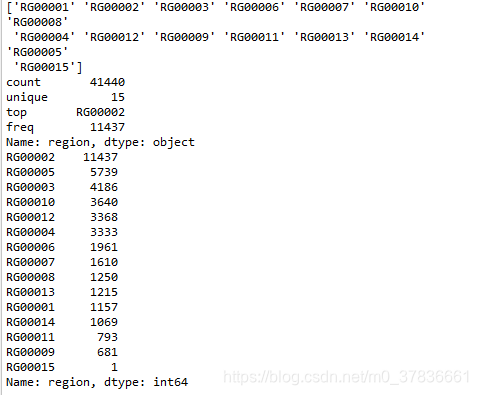
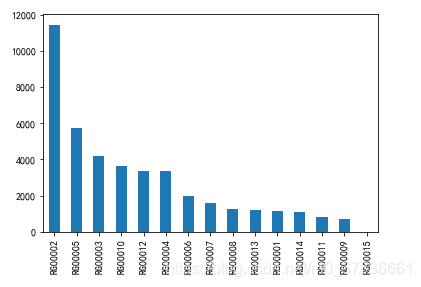
15种,RG00002最多 -
plate

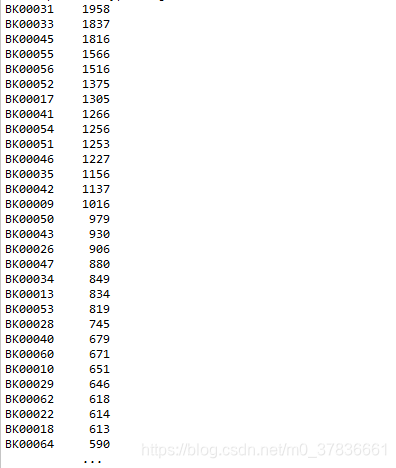

15种,有些地方较为密集 -
buildYear

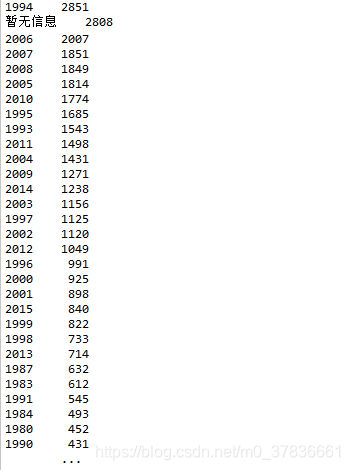

80种,大多都在94年后
定量数据
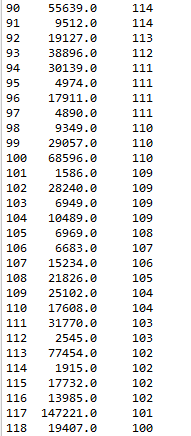
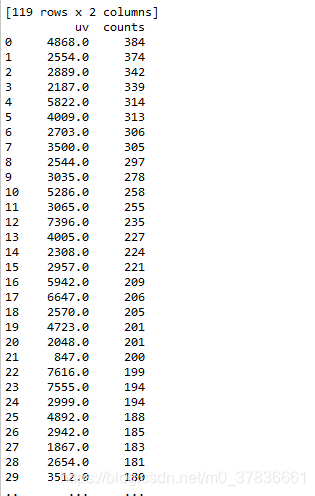
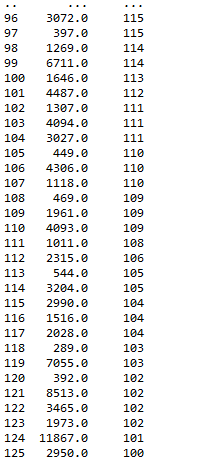
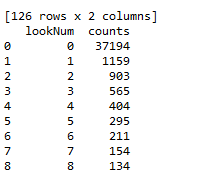
五、统计特征值出现频率大于100的特征
此步骤和特征nunique分布结合步骤结合起来看,有一些小于100的是可以直接统一归类为其他的
#统计特征值出现频率大于100的特征
cols = [col for col in data_train.columns]
for col in cols:
df_value_counts = pd.DataFrame(data_train[col].value_counts())
#重新定义索引
df_value_counts = df_value_counts.reset_index()
df_value_counts.columns = [col, 'counts']
print(df_value_counts[df_value_counts['counts'] >= 100])
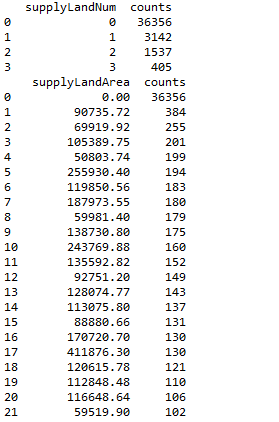
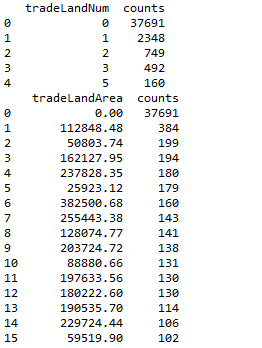
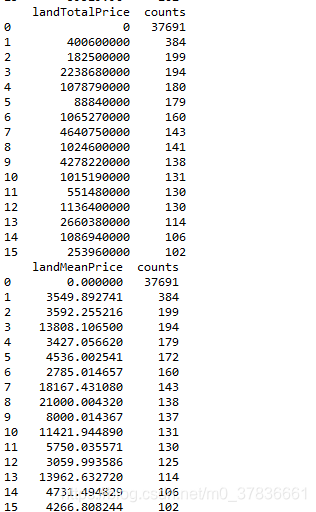

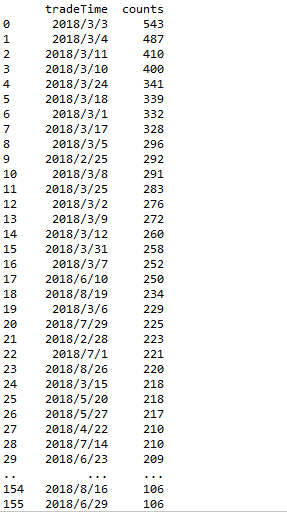
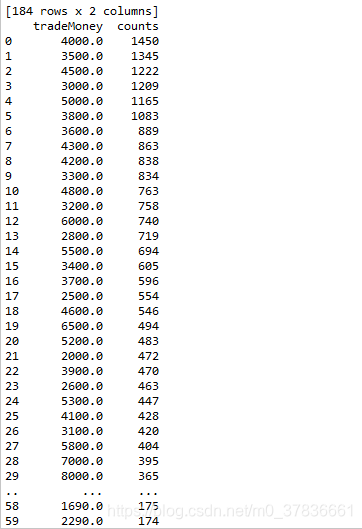
六、Label分布
#看label分布
fig,axes = plt.subplots(2,3,figsize = (20,5))
fig.set_size_inches(10,6)
sns.distplot(data_train[data_train['tradeMoney'] <= 10000]['tradeMoney'], ax = axes[0][0])
sns.distplot(data_train[(data_train['tradeMoney']>10000) & (data_train['tradeMoney'] <= 20000)]['tradeMoney'],ax = axes[0][1])
sns.distplot(data_train[(data_train['tradeMoney']>20000) &(data_train['tradeMoney'] <= 50000)]['tradeMoney'], ax = axes[0][2])
sns.distplot(data_train[(data_train['tradeMoney']>50000) &(data_train['tradeMoney'] <= 100000)]['tradeMoney'], ax = axes[1][0])
sns.distplot(data_train[(data_train['tradeMoney']>100000)]['tradeMoney'], ax = axes[1][1])
print('money<=10000', len(data_train[data_train['tradeMoney']<=10000]['tradeMoney']))
print('10000<money<=20000', len(data_train[(data_train['tradeMoney']>10000) & (data_train['tradeMoney'] <= 20000)]['tradeMoney']))
print('20000<money<=50000', len(data_train[(data_train['tradeMoney']>20000) & (data_train['tradeMoney'] <= 50000)]['tradeMoney']))
print('50000<money<=100000', len(data_train[(data_train['tradeMoney']>50000) & (data_train['tradeMoney'] <= 100000)]['tradeMoney']))
print('money>10000', len(data_train[data_train['tradeMoney'] > 100000]['tradeMoney']))
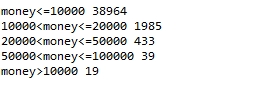
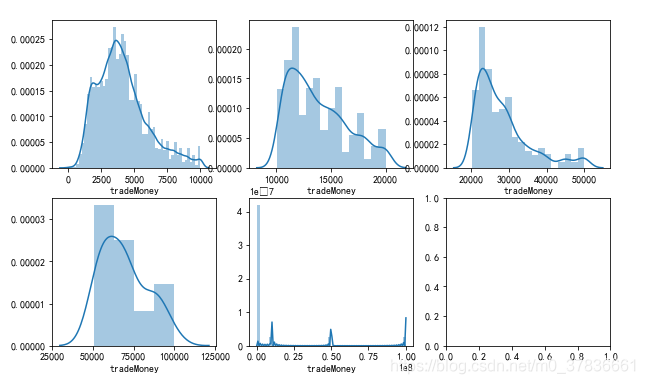
将目标变量tradeMoney分组,并查看每组间分布,可以看出绝大多数都是集中在10000以下,且该分布左偏
八、不同的特征值的样本的label的分布
可以和多样的特征结合起来分析,但是现在没有时间了,待完善
