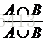CH2-认识数据
属性
数据集由数据对象组成(也就是每一个实体,样本),数据对象用属性(维度、特征)描述
-
标称属性:一些符号和事物的名称,是分类的而不必具有意义的序列,如头发颜色和学历是描述人的属性。
-
二元属性:只有0、1两种状态,可以对称(男/女),也可以不对称(HIV阴性)
-
序数属性: 可能的值具有有意义的序,如军衔有下士、中士、上尉、将军。
-
数值属性: 定量的,用实数值表示
统计描述
为数据预处理提供了基本的分析基础
-
中心趋势:均值、加权平均、中位数、众数
-
当数据很大时,我们用插值计算估算整个数据集中中位数的值
-
在众数的计算中中,适度倾斜的单峰频率可以用公式近似计算
\[mean -mode\approx3 \times(mean - median) \]
-
-
数据散布:极差、分位数、四分位数、四分位数极差(IQR)、标准差
- IQR可以用来识别离群点,一般为1.5*IQR以外的
- 利用盒图来展示五数概括
- 标准差是数据集发散的很好指示器
-
图形显示:分位数图、直方图、散点图
- 利用分位数-分位数图观察一个分布与另一个分布的比较情况
- 散点图可以考察点簇和离群点、或者相关联系的可能性
数据的相似和相异性
我们如何去度量数据的相似性和相异性(即数据的邻近性)?
如何存放数据对象和相异性值
利用数据矩阵 - N×P(N个对象P个属性)的矩阵保存数据样本
利用一个 - N×N的矩阵保存对象的相似度,也就是相异性矩阵,矩阵是对称的
对于标称数据:sim (相似性)= 1 - d(i,j)(1-相异性)
标称属性
对于标称属性,我们利用两个对象之间属性不匹配率来计算,其中P是所有的属性总数,m是两个对象取值相同的属性数
举个例子:
| 对象 | 头发颜色 | 婚姻状况 | 职业 |
|---|---|---|---|
| Dave | 黑 | 已婚 | 工程师 |
| Jony | 黑 | 未婚 | 工程师 |
| Maria | 黑 | 离异 | 医生 |
则d(dave,jony) = (3 - 2)/3 = 0.33,Dave和Jony的相异性0.33
二元属性
二元属性只有两种状态,那么我们有如下表格
| 对象j取1的属性数 | 对象j取0的属性数 | sum | |
|---|---|---|---|
| 对象i取1的属性数 | q | r | q+r |
| 对象i取0的属性数 | s | t | s+t |
| sum | q+s | r+t | p |
q表示对象i和j都取1的属性数,r表示对象i取0,对象j取1的属性数……以此类推,属性的总数是p = q+r+s+t,对于对称的二元属性:
对于非对称的二元属性,两者不是一样重要的,比如HIV阳性,那么我们认为对象i和j都取值为1的情况(正匹配),比两个都取值为0(负匹配)更有意义,在计算时我们将t抛弃:
互补的,我们得到相似系数:
这个sim(i,j)我们称之为Jaccard相似似系数(Jaccard similarity coefficient)用于比较有限样本集之间的相似性与差异性。Jaccard系数值越大,样本相似度越高。
ps:说白了就是抛弃掉对象i和对象j都取0的属性数,突出对象i和对象j都取1的情况。比如两个对象A,B,我们要判断他们两个人的相似性,一个二元属性,两个人是否得过HIV,两个人都是True,另一个二元属性,这两个人是否去过非洲,两个人都是False,我们认为这个属性不重要,把他抛弃(这在后面混合类型相异性中有用到)。
数值属性
相异性度量:我们利用欧几里得距离(L2范数)、曼哈顿距离(L1范数)、闵可夫斯基距离(LP范数)、上确界距离(Lmax)
- 欧几里得距离和曼哈顿距离都是闵可夫斯基距离的特殊情况
- 度量前的数据应该是规范化的
- 上确界距离:两个对象该属性的最大值差
序数属性
将序数进行赋值,然后映射到[0,1]这个区间上,将其变为数值属性,然后利用数值属性的方法进行度量
比如及格、良好,优秀,我们可以赋值为1,2,3利用公式z = (r -1)/(m - 1)进行映射为0,0.5,1,m是最大值,r是当前值.
混合类型
书里介绍的主要方法是将所有的属性转换到共同的区间[0.0,1.0]
对象的相异性定义为:(δ是一个指示符,如果xif或xjf缺失,或者二者等于0且是非对称的二元属性,则δ为0,否则为1)
大白话:就是抛弃了缺失值和负匹配的值。
有了定义,那么我们如何将属性转换到共同的区间呢?
- f(属性)是数值的:d(i,j) = |i - j|/(maxi - maxj)(数值差除以极差)
- f是标称或者二元的:两个对象的属性相等则d(i,j) = 0,不相等为1
- f是序列的,和原来一样
假设一组数据,有数值、二元、序列三种属性,我们就分别得到三个相异矩阵,然后将三个矩阵中的每一项取平均(相加除以三)就得到了描述混合类型的相异性矩阵。
余弦相似性
当数值数据比较稀疏的时候,比如文档、基因,传统的距离度量效果不好,比如文档,我们关注的是共有的词,要忽略0匹配的值。我们利用余弦相似性来判断文档:
其中||x||是向量x的长度,||y||是向量y的长度
大白话:余弦(cosx) = 向量积/向量模的积,夹角越大,cosx越接近于0,两者相关性越小,当cosx = 0时,二者正交,没有相关性,越接近与1,两者夹角越小,相关性越大
夹角越小,向量匹配
- Tanimoto系数:x和y的共有属性和与x和y具有的属性之间的比较
sim(x,y) = x·y/(x·x+y·y-x·y)
大白话:Tanimoto系数可以表示为