项目介绍
给定一些单词,统计其中每一种单词的数量;
本项目将采用scala编程语言,编写两种单词统计代码,一种在本地运行,一种在spark集群上运行;
本文将完整地讲解代码含义和运行情况。
IDEA上运行
这个程序非常简单,如果是scala语言的初学者,也可以直接看:
object test {
//定义数组变量,也是单词统计需要统计的文本
val arr = Array("hello tom","hello jerry","hello hello")
//flatMap设置了以空格为分隔符,这样可以将数组变成(hello,tom,hello,jerry,hello,hello);
//第一个map执行之后将数组变成((hello,1),(tom,1),(hello,1),(jerry,1),(hello,1),(hello,1));
//groupBy生成一个map,将上一行内容变成((hello,[1,1,1,1]),(tom,[1]),(jerry,[1]))。“_._1”的意思是参照第一个值分类,即参照单词分类;
//第二个map,其中t是(单词,[1,...1]),t._1代表单词,t._2.size可以计算出这个单词对应多少个1,也就是有多少
val count =arr.flatMap(_.split(" ")).map((_,1)).groupBy(_._1).map(t=>(t._1,t._2.size))
def main(args: Array[String]): Unit = {
println("hello world" )
//查看输出结果
println(count)
}
}
spark上运行
1、代码
import org.apache.spark.{SparkConf, SparkContext}
object wordcount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("wordcount")
val sc = new SparkContext(conf)
//以上代码具有普适性,以下代码是关键;
//textFile用来读取txt文件,args(0)作为文件名;
//这里的flatMap会依据空格作为分隔符,将输入文件整理成map;
//map和上面的一样;
//reduceByKey是根据键值对的键进行统计,这里键值对是(单词,1),将所有单词相同的键值对统计到一起;
//sortBy中的_._2代表根据第二个元素来排序,即键值对的值;
//saveAsTextFile(args(1))将文件保存至args(1)指定的文件夹下
val rdd = sc.textFile(args(0))
.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
.sortBy(_._2,false).saveAsTextFile(args(1))
//停止
sc.stop()
}
}
2、添加依赖,编写代码,生成.jar
这部分不再详述,我只将我的做法贴出来供大家参考
在之前的基础上在pom.xml中添加:
<!-- https://mvnrepository.com/artifact/org.scala-tools/maven-scala-plugin -->
<dependency>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.11</version>
</dependency>
将工程文件打包成.jar包,然后传到我的集群结点hdp-node-01中。
(顺便声明:这是我从我的实训报告中扣下来的图片,如果有改作业老师查重到这篇博客,不要认为我是抄的)
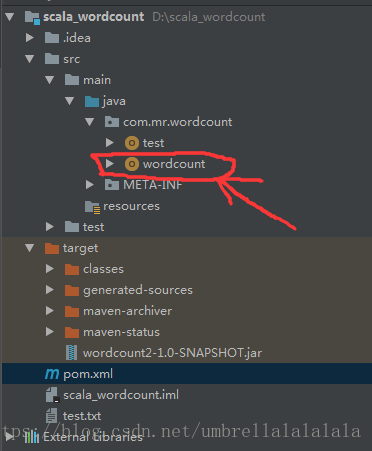
完整的工程文件目录如下:
3、跑程序
/usr/local/apps2/spark-2.2.0-bin-hadoop2.6/bin/spark-submit \
--class com.mr.wordcount.wordcount \
--master spark://hdp-node-01:7077 \
--executor-memory 512m \
wordcount2-1.0-SNAPSHOT.jar scala_wordcount/input.txt scala_wordcount/output```
我是将spark安装到了/usr/local/apps2中,所以我的spark-submit文件在/usr/local/apps2/spark-2.2.0-bin-hadoop2.6/bin/spark-submit中。
上面命令最后一行的解释:
.jar代表这个包,scala_wordcount/input.tx代表代码中的args(0),是程序的输入文件,scala_wordcount/output代表代码中的args(1),代表程序的输出会存放到output文件夹中。
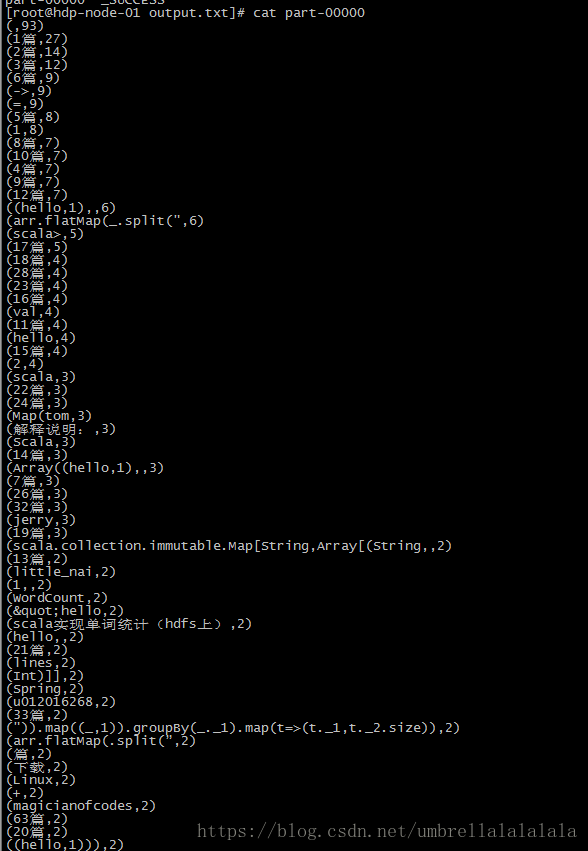
4、 效果
我在input.txt粘贴了一整页网页内容,最终计数效果如下