之前学习了一段时间的hadoop的相关知识 ,学习理论基础的时候要同时实际操作才能对它更熟练,废话不多说来说说在hadoop上运行一个最简单的words count的程序
首先我先贴上这个程序的源代码 供大家参考 代码分为三个部分写的Run、 map阶段、 reduce阶段
Map:
-
package wordsCount;
-
-
import java.io.IOException;
-
import java.util.StringTokenizer;
-
-
import org.apache.hadoop.io.IntWritable;
-
import org.apache.hadoop.io.LongWritable;
-
import org.apache.hadoop.io.Text;
-
import org.apache.hadoop.mapreduce.Mapper;
-
-
public
class WordsMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
-
@Override
-
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
-
throws IOException, InterruptedException {
-
-
String line = value.toString();
-
StringTokenizer st =
new StringTokenizer(line);
-
while(st.hasMoreTokens()){
-
String word = st.nextToken();
-
context.write(
new Text(word),
new IntWritable(
1));
-
}
-
-
}
-
-
}
Reduce:
-
package wordsCount;
-
-
import java.io.IOException;
-
-
import org.apache.hadoop.io.IntWritable;
-
import org.apache.hadoop.io.Text;
-
import org.apache.hadoop.mapreduce.Reducer;
-
-
public
class WordsReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
-
-
@Override
-
protected void reduce(Text key, Iterable<IntWritable> iterator,
-
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
-
// TODO 自动生成的方法存根
-
int sum =
0;
-
for(IntWritable i:iterator){
-
sum = sum + i.get();
-
}
-
context.write(key,
new IntWritable(sum));
-
}
-
}
-
package wordsCount;
-
-
-
import org.apache.hadoop.conf.Configuration;
-
import org.apache.hadoop.fs.Path;
-
import org.apache.hadoop.io.IntWritable;
-
import org.apache.hadoop.io.Text;
-
import org.apache.hadoop.mapreduce.Job;
-
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
-
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
-
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
-
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
-
-
public
class Run {
-
-
public static void main(String[] args) throws Exception{
-
// TODO 自动生成的方法存根
-
Configuration configuration =
new Configuration();
-
Job job =
new Job(configuration);
-
job.setJarByClass(Run.class);
-
job.setJobName(
"words count!");
-
-
job.setOutputKeyClass(Text.class);
-
job.setOutputValueClass(IntWritable.class);
-
-
job.setInputFormatClass(TextInputFormat.class);
-
job.setOutputFormatClass(TextOutputFormat.class);
-
-
job.setMapperClass(WordsMapper.class);
-
job.setReducerClass(WordsReduce.class);
-
-
FileInputFormat.addInputPath(job,
new Path(
"hdfs://192.168.1.111:9000/user/input/wc/"));
-
FileOutputFormat.setOutputPath(job,
new Path(
"hdfs://192.168.1.111:9000/user/result/"));
-
-
job.waitForCompletion(
true);
-
}
-
}
Run里面的输入和输出路径根据自己的来修改
这个程序就不用去讲解了吧 到处都能找到
首先在hadoop上运行这个程序用两个方法
方法一:将自己的编译软件与hadoop相连(我用的是MyEclipse去链接hadoop),直接运行程序。MyEclipse连接hadoop的教程待会我会在文章结尾处给出一个链接供大家参考。
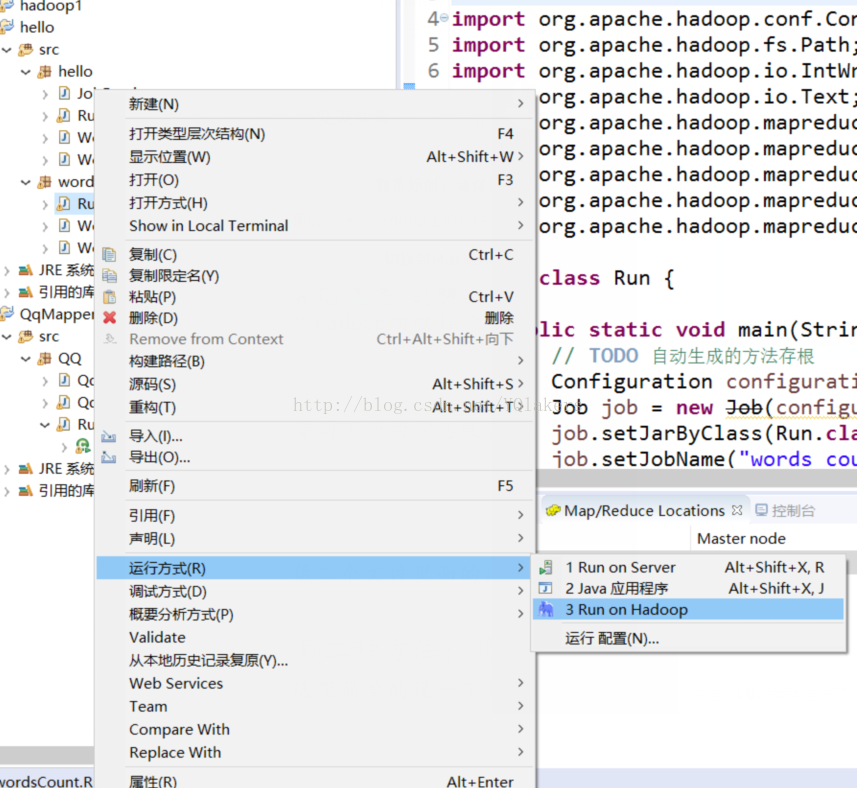
看到下面的信息就表示你成功了 然后你在再到你的输出文件夹里面就能查看运行的结果了
第二个文件里面的内容就是输出结果
第二种方法:将mapreduce程序打包成jar文件
这里简单的说一下打包的方法
然后下一步,完成就可以了
将打包好的jar文件传到你的装hadoop的机器上(我的hadoop集群是装在linux虚拟机中的)用SSH把jar传过去之后:
在你安装hadoop的目录下的bin目录下有一个hadoop的可执行文件,然后执行下面的操作就可以了:

来解释下我的shell语句
/home/xiaohuihui/wordscount.jar:打包之后的jar文件的所在位置(传到虚拟机中位置)
wordsCount/Run:这个位你的jar包中的主函数(这里的主函数就是Run.class)的名字 可以打开你的jar文件查看便知道
还可以在这个语句之后加上你的输入和输出的文件路径,但是这个我已经在我的程序中设置了
如果你运行上面的shell语句之后看到下面的输出,那恭喜你,成功了!!
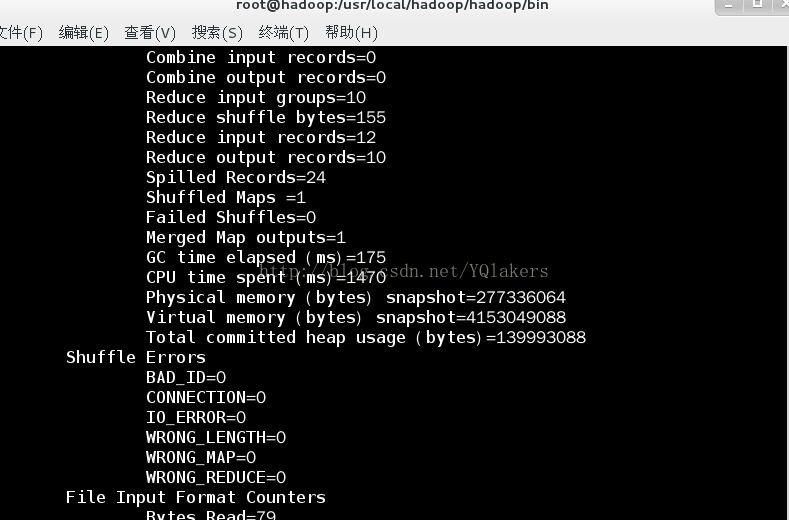
查看结果你可通过在你的Eclipse连接好hadoop查看,还可以通过在hdfs文件系统的网页去查看(localhost:50070)。
还有一个很重要的一步就是,运行之前保证你的hadoop已经启动了,可以通过jps来查看你的进程中是否已经启动hadoop集群
Eclipse连接hadoop:http://blog.csdn.net/xjavasunjava/article/details/12320045
