目录
3、在Client模式下,Driver进程会在当前客户端启动,客户端进程一直存在直到应用程序运行结束。
1、首先介绍yarn的模型图
(1)、yarn 模型图

(2)、yarn的流程如下:
YARN中的应用程序的提交处理,可以依次分为以下步骤:
(1)用户通过client向RM提交应用程序
(2)RM在接收到一个新的应用程序后,会先选择一个container用于启动该应用程序特有的AM
(3)AM启动后,向RM请求运行应用程序所需要的资源
(4)RM会尽可能地分配AM所请求的资源的容器,表达为container容器ID和主机名
(5)AM根据给定的容器ID和主机名,要求对应的NodeManager使用这些资源启动一个特定于应用程序的任务。
(6)NodeManager启动任务,并监视该任务使用资源的健康状况。
(7)AM持续监视任务的执行情况。
(8)当任务执行完成时,AM会向RM汇报并注销执行任务的容器,以及注销自己。
2、cluster模式下提交任务流程
(1)、流程图如下
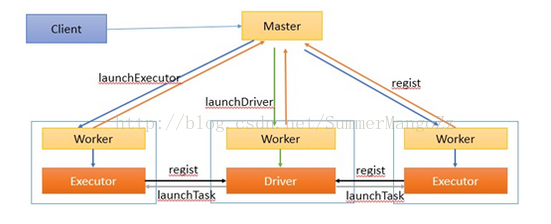
(2)、工作流程如下:
1.在集群的节点中,启动master (ResourceManager), worker(NodeManager)进程,worker(NodeManager)进程启动成功后,会向Master(ResourceManager)进行注册。
3.客户端提交任务后,master通知worker节点启动driver(application Master)进程。(worker的选择是随意的,只要worker有足够的资源即可)
driver进程启动成功后,将向Master返回注册成功信息
4.master通知worker启动executor进程
5.启动成功后的executor进程向driver进行注册
6.Driver对job进行划分stage,并对stage进行更进一步的划分,将一条pipeline中的所有操作封装成一个task,并发送到向自己注册的executor进程中的task线程中执行
7.所有task执行完毕后,程序结束
通过上面的描述我们知道:Mater(ResourceManager)负责整个集群的资源的管理和创建worker(NodeManager),worker负责当前结点的资源的管理,并会将当前的cpu,内存等信息定时告知master,并且负责创建Executor进程(也就是最小额资源分配单位),Driver(applicationMaster)负责整个应用任务的job的划分和stage的切割以及task的切割和优化,并负责把task分发到worker对应的节点的executor进程中的task线程中执行, 并获取task的执行结果,Driver通过SparkContext对象与spark集群获取联系,得到master主机host,就可以通过rpc向master注册自己。
spark集群的master就是 yarn的ResourceManager,负责整个集群的资源的管理和创建worker。
spark集群的worker就是yarn的NodeManager,负责当前结点的资源(cpu,内存)的管理。
Driver是每个应用任务唯一的。就是yarn的applicationMaster。
每个执行算子都会产生一个job。
每个宽依赖会有一个stage。
executor*core=task的个数,一个task对应处理一个分区。
3、在Client模式下,Driver进程会在当前客户端启动,客户端进程一直存在直到应用程序运行结束。
(1)、client模式下的流程图
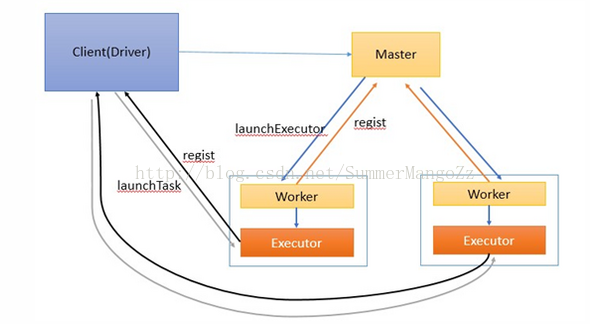
(2)、工作流程如下:
1.启动master和worker . worker负责整个集群的资源管理,worker负责监控自己的cpu,内存信息并定时向master汇报
2.在client中启动Driver进程,并向master注册
3.master通过rpc与worker进行通信,通知worker启动一个或多个executor进程
4.executor进程向Driver注册,告知Driver自身的信息,包括所在节点的host等
5.Driver对job进行划分stage,并对stage进行更进一步的划分,将一条pipeline中的所有操作封装成一个task,并发送到向自己注册的executor
进程中的task线程中执行
6.应用程序执行完成,Driver进程退出
4、Spark任务调度
各个RDD之间存在着依赖关系,这些依赖关系就形成有向无环图DAG,DAGScheduler对这些依赖关系形成的DAG进行Stage划分,划分的规则很简单,从后往前回溯,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。完成了Stage的划分。DAGScheduler基于每个Stage生成TaskSet,并将TaskSet提交给TaskScheduler。TaskScheduler 负责具体的task调度,最后在Worker节点上启动task。
