哈希函数+布隆过滤器+一致性哈希+哈希表
- 认识哈希函数和哈希表
- 设计RandomPool结构
- 认识布隆过滤器
- 认识一致性哈希
(from左神算法初级班第6节)
1.认识哈希函数和哈希表
1)什么是哈希函数?(非常重要)
定义:能通过哈希函数直接找到需要的记录,在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使每个关键字和结构中一个唯一的存储位置相对应。
性质:
- 经典哈希函数的输入域是无穷大的
- 输出域有范围
- 同样的输入得到同样的输出
- 相同的输出可能对应不同的输入
- 离散性(在输出域中均匀分布输出值)。离散性拓展(将输出%m,那么输出将在0~m-1均匀分布)
(面试不会要求实现哈希函数)
改出1000个哈希函数:
哈希函数每一个位相对于其他位置都是些相对独立的,所以可以通过两个无相关性的哈希函数改出1000个。
- 找到两个无相关性的哈希函数h1,h2。
- 按照h1+n*h2,来构造新的哈希函数。
例子:
如何将100T大文件所有重复的字符串打印出来?(问面试官有多少台机器,文件是否在分布式服务器中,是否有快速读取工具)
哈希函数做分流(哈希来哈希去)
- 用哈希分流到1000台机器,把每一行读取出来作为文本,利用哈希函数算出hashcode%1000,分到不同的机器上。
- 不同的字符串,会均匀分布到1000台机器上,再在每台机器上找重复
2)哈希表(哈希函数分桶)
- 基本方法(put、get、remove,时间复杂度都是O(1))
- 哈希表结构改进:将每次key得到的code%n,那么哈希表的结构表范围就是0~16,将每一个结果都挂到相应的位置上去。当有冲突的时候,如果相等则修改结果,如果不相等时,就挂到后面上去。(扩容:将每一个数据重新%,再放进新的哈希表中。)
2.设计RandomPool结构
(和哈希表有点类似)
【题目】 设计一种结构,在该结构中有如下三个功能: insert(key)将某个key加入到该结构,做到不重复加入。
delete(key):将原本在结构中的某个key移除。
getRandom(): 等概率随机返回结构中的任何一个key。
【要求】 Insert、delete和getRandom方法的时间复杂度都是 O(1)
解题步骤:
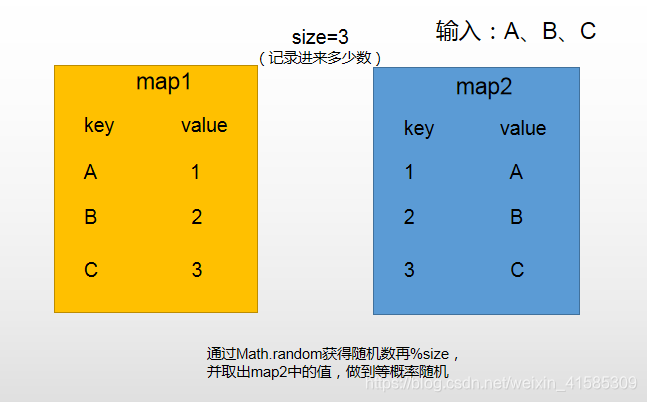
- 准备两个map和一个变量size
- 通过math.random来产生随机数再%size,做到等概率随机
- 减的时候,将最后一个值放到被减的桶中(消除掉map中的洞)
代码:
public static class Pool<K> {
private HashMap<K, Integer> keyIndexMap;
private HashMap<Integer, K> indexKeyMap;
private int size;
public Pool() {
this.keyIndexMap = new HashMap<K, Integer>();
this.indexKeyMap = new HashMap<Integer, K>();
this.size = 0;
}
public void insert(K key) {
if (!this.keyIndexMap.containsKey(key)) {
this.keyIndexMap.put(key, this.size);
this.indexKeyMap.put(this.size++, key);
}
}
public void delete(K key) {
if (this.keyIndexMap.containsKey(key)) {//减的时候,将最后一个放入到被减去的桶中
int deleteIndex = this.keyIndexMap.get(key);
int lastIndex = --this.size;
K lastKey = this.indexKeyMap.get(lastIndex);
this.keyIndexMap.put(lastKey, deleteIndex);
this.indexKeyMap.put(deleteIndex, lastKey);
this.keyIndexMap.remove(key);
this.indexKeyMap.remove(lastIndex);
}
}
public K getRandom() {
if (this.size == 0) {
return null;
}
int randomIndex = (int) (Math.random() * this.size); // 0 ~ size -1,等概率返回0~size
return this.indexKeyMap.get(randomIndex);
}
}
3.认识布隆过滤器(某种类型的集合)
解决问题:爬虫去重问题,黑名单问题等。
例如:
有100亿个url黑名单(每个url64字节)。如果在黑名单,返回true,否则false。如果用hashset()需要至少6400亿字节(640G)。
解决方法:
布隆过滤器有失误率(宁可错杀一千,不放过八百)
- 准备n+1个长度为m的数组
- 每一个arr数组中每个位置只记录bit类型的数据
- 准备k个哈希函数,每个url通过每个哈希函数得到的code%(m*n),将对应的arr描黑。
- 查url的时候,经过每个哈希函数,如果code对应的arr位置都是黑的,就返回true,如果有一个位置不是黑的,就返回false。
- 如果数组开的太小,所有位置都黑了,布隆过滤器失误率就很高(失误率跟数组开的大小有关)


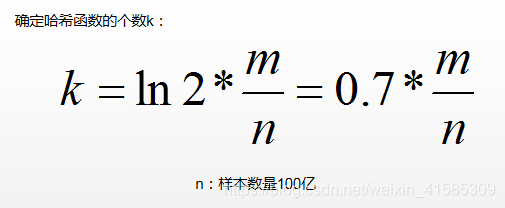
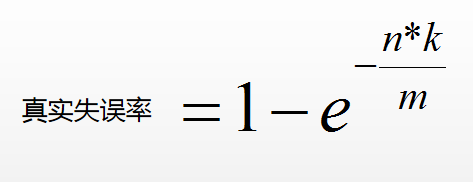
代码:
public static void main(String[] args) {//怎么实现长度为0~m-1的bit类型的数组,基本类型拼
int[] arr = new int[1000];
int index = 30000;
int intIndex = index/32;//定位来自哪个数组
int bitIndex = index % 32;//定位来自哪个数组的那个bit位
arr[intIndex] = (arr[intIndex] | (1<<bitIndex));
}
4.认识一致性哈希
1)一致性哈希的应用
-
经典服务器服务:前端所有机器带相同一份的哈希code,%后端机器个数,将请求发送给对应的后端机器。
经典服务器服务带来问题:
要加机器或者减机器的时候,所有的数据归属迁移的代价太高。 -
一致性哈希负载均衡,并且数据迁移带来的代价很低。
2)一致性哈希结构
把整个hash函数的值看成是一个环。requst通过二分方式顺时针找到最近的机器
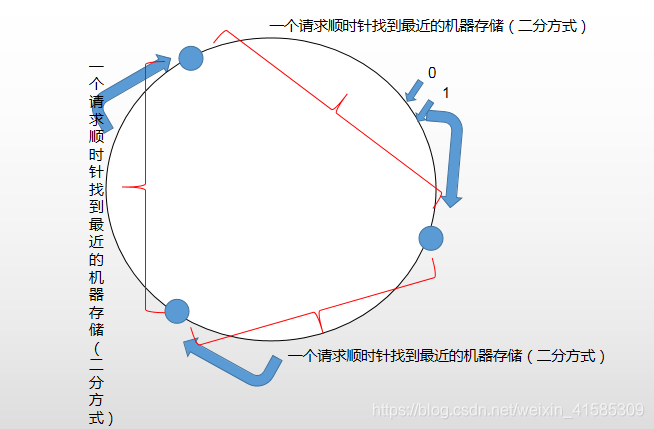
这种结构下,如果加一个机器(数据迁移代价低):
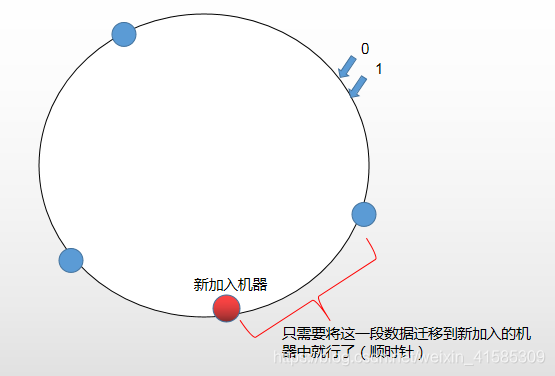
3)负载均衡问题(虚拟节点技术):
按照上面的结构,每加入一台机器,负载均衡就会被打破。
- 给每个机器分配1000个虚拟节点,让虚拟节点去抢环中的位置。
- 虚拟节点上的数据由对应的机器负责处理。
- 当加入一个新机器后,将机器的1000个虚拟节点去抢环中的位置。
- 如果减少一个机器,就减少1000个虚拟节点环的位置。
- 这样就实现了负载均衡
