本小节深入讨论Python中的数据类型与名字绑定的关系,了解赋值过程的内部细节。
版权声明
本文可以在互联网上自由转载,但必须:注明出处(作者:海洋饼干叔叔)并包含指向本页面的链接。
本文不可以以纸质出版为目的进行改编、摘抄。
本文节选自作者的《Python编程基础及应用》视频教程。
数据类型及名字绑定
除了已经讨论过的整数-int、 浮点数-float、 布尔型-bool、字符串-str、列表-list之外,还有一些数据类型尚待讨论。
元组-只读的列表
**元组-tuple就是只读的列表。**所谓只读,是指一个元组创建出来以后, 其值或者元素可以获取,但不能修改。上一章所讲述的关于列表的嵌套、in、not in、统计、运算等都适用于元组,切片也适用。注意切片并不会导致原始列表/元组被修改,其只会创建一个新列表/元组。
那些会导致列表发生修改的成员函数,比如remove(), sort()则不适用于元组,因为元组是只读的。
patient = ('2012011', 'Eric Zhang', 'male', 77, True, (67,22,78))
print(type(patient), patient)
print(len(patient))
print(patient[1:4])
print(patient.count(True))
print(True in patient)
print(max((1,3,5)))
print((1,2) + (2,3) + (4,))
print((1,2) * 5)
执行结果:
<class 'tuple'> ('2012011', 'Eric Zhang', 'male', 77, True, (67, 22, 78))
6
('Eric Zhang', 'male', 77)
1
True
5
(1, 2, 2, 3, 4)
(1, 2, 1, 2, 1, 2, 1, 2, 1, 2)
可以看到,元组用()框起来定义。上面的代码展示了元组的嵌套、len()函数、切片、max()、count()成员函数、in、拼接、运算等操作,其方法和用途与列表完全相同。
请注意上述代码中最后一行这个奇怪的表达"(4,)", 这是告知解释器,这是由一个元素构成的元组,而不是打了括号的整数4。
下述操作则不适用于元组,因为这些操作预期会改变元组的值,而元组是只读的。
patient = ('2012011', 'Eric Zhang', 'male', 77, True, (67,22,78))
#下述代码是发生执行错误
patient[1] = 'NEW VALUE'
patientSort = patient.sort()
patient.remove(77)
patient.clear()
生成与转换
numbers = tuple([1,2,3])
print(numbers)
chars = tuple('abc')
print(chars)
digits1 = (x for x in range(9))
print("digits1:", digits1)
digits2 = tuple(x for x in range(9))
print(digits2)
执行结果:
(1, 2, 3)
('a', 'b', 'c')
digits1: <generator object <genexpr> at 0x0000019D5458BA20>
(0, 1, 2, 3, 4, 5, 6, 7, 8)
可以看到,tuple()函数接受一个列表、字符串或者一个生成者对象-generator object作为参数,并返回一个元组。注意,digits1 = (x for x in range(9))被认为是一个生成者对象-generator object。
bytes
本节是介绍性内容,初学者如果对底层细节不感兴趣,可以略过。
在工业应用中,比如用Python语言编写工业机器人的控制程序,我们经常需要跟硬件直接通信。在数字电路里,永远是二进制的,所以我们所描述的全部数据类型在计算机内部最终全部以二进制形式存储和传输。bytes是只读的“二进制字节流”类型。
buffer = b'abcdefghijklmn'
print(buffer,type(buffer),"len=",len(buffer))
print(buffer[2:9:2])
buffer = b'\x11\xff\x77'
print("%x" % (buffer[1]))
buffer = bytes(i+0x10 for i in range(10))
print(buffer)
执行结果:
b'abcdefghijklmn' <class 'bytes'> len= 14
b'cegi'
ff
b'\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19'
上述代码及执行结果展示了bytes的定义,len()函数、切片等基本操作。bytes()函数可以把一个生成者对象转换为bytes。一个字节如果看作无符号整数的话, 可以存储0-255之间的任何值。所以bytes作为字节流,其每个字节可以存任何0-255之间的任意整数,不限于’a’,‘2’ 这些"可见"字符。
转换
x = 65534
bufferLittle = x.to_bytes(2, 'little')
print("little endian:", bufferLittle)
bufferBig = x.to_bytes(2,'big')
print("big endian:", bufferBig)
y = int.from_bytes(b'\xfe\xff','little')
print(y)
执行结果:
little endian: b'\xfe\xff'
big endian: b'\xff\xfe'
65534
如上,int的to_bytes()成员函数将一个整数转换成指定字节长度(示例中为2)的bytes,第2个参数’little’指明了字节编码顺序。现存的CPU在存储和处理数据时,存在little endian和big endian两种标准,其中,little endian高位字节存高地址,big endian则正好相反。常用的Intel x86 CPU(用于PC系统)以及ARM CPU(常见于智能手机及其它嵌入式系统,智能电视之类)都是little endian的。
int的from_bytes()成员函数则把bytes重新打包成Python的int对象。
借助于struct模块,我们可以更方便地把int, float和其它数据类型同bytes进行相互转换。
bytearray
本节是介绍性内容,初学者如果对底层细节不感兴趣,可以略过。
bytearray可以译作字节数组,其功用与bytes类似,区别在于,bytearray不是只读的,可修改。
buffer = bytearray(0x00 for x in range(10))
print(type(buffer), buffer)
buffer = bytearray(b'abcdefghijklmn')
buffer[1] = ord('B')
print(buffer)
print(buffer[3:11:3])
执行结果:
<class 'bytearray'> bytearray(b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00')
bytearray(b'aBcdefghijklmn')
bytearray(b'dgj')
上述代码及执行结果展示了bytearray的定义,切片方法。其中,ord()函数来自于英文order, 它将一个字符转换成其对应的ASCII码整数。
ASCII码是一个表格,将每个字符与一个整数对应,这个整数事实上就是字符在计算机内部的实际存储值。
按位与、或、移位
本节是介绍性内容,初学者如果对底层细节不感兴趣,可以略过。
x = 0xaa
print("x =", bin(x))
print("x & 0x7f =", bin(x & 0x7f))
print("x | 0x77 =", bin(x | 0x77))
y = 0x00ff
y = y << 8
print("y =", hex(y))
执行结果:
x = 0b10101010
x & 0x7f = 0b101010
x | 0x77 = 0b11111111
y = 0xff00
上述代码及执行结果展示了按位与-&、按位或-|、左移位-<<操作符的使用方法。这些操作符只有当你跟底层硬件打交道时才会用得到。
所谓按位与,即是把原始比特值做逻辑与运算,1看作真,0看作假,结果也用1或0表示:
1 & 1 = 1; 1 & 0 = 0; 0 & 0 = 0。
按位或即是把原始比特值做逻辑或运算。左移位<<操作符则是把全部比特向左移指定位数,右边补0。除此之外,还有按位取反~,按位异或^,右移位>>等操作符,各位等到用时再查资料即可。
序列
列表-list、字符串-str、元组-tuple、bytes、bytearray都可视作序列类型。共同点在于:
-
可以通过下标或索引访问其元素(只读类型只可获取,不得修改);
-
可通过切片操作获取其子序列。
作为序列类型,上述类型的使用方法有很多相通之处。
名字绑定
在第4章,我们已经见识了将一个列表从一个变量赋值给另一个变量后的令人疑惑的操作结果:
person1 = ['10000', 'Jack Ma', 'male', 47, 'CEO']
person2 = person1
person2[1] = "Tom Henry"
print(person1)
print(person2)
执行结果:
['10000', 'Tom Henry', 'male', 47, 'CEO']
['10000', 'Tom Henry', 'male', 47, 'CEO']
看起来,似乎person2和person1指向的是同一个列表实体。因为person2被修改后,person1也跟着改变了。初学者很容易感到疑惑,本章试图从原理层面讲清楚这个重要的问题。
再看a=1
a = 1
print("id:",id(a))
a = 2
print("id:",id(a))
b = a
print("id of a:", id(a), "id of b:",id(b))
a += 1
print("id:",id(a))
执行结果:
id: 140720188347424
id: 140720188347456
id of a: 140720188347456 id of b: 140720188347456
id: 140720188347488
id()函数返回对象在Python解释器内部的编号,每一个对象都是一个唯一的id号,你可以把id号想象成该对象在内存中的地址。可以看到,a每经过一次赋值,其id号是不同的。
之前,我们是这样描述a = 1的: a是一个变量/对象,赋值操作符=把类型为整数的对象1传递给了变量/对象a,赋值之后a是一个类型为整数的变量/对象,其值为1。这种描述方法是传统习惯,目的是方便你在课程前期能够看懂,但这不是事实。
名字、对象及绑定
| a = 1执行结果: | |
|---|---|
 |
- 值1是一个对象-object,它有内存地址(id号); - a只是一个名字-name,所谓赋值,就是把这个名字绑定在相应的对象上。 |
同理,a = 2被执行时, 解释器会将名字a绑定在值为2的整数对象上。由于2是一个跟1不同的对象,所以id(a)会返回不同的地址。如下图:
| a = 2执行结果: | |
|---|---|
 |
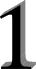 |
请注意,此时,值为1的对象此时仍然存在,但没有名字与其绑定。事实上,对象内部会有专门的引用计数来表明这个对象当前与多少个名字绑定,当对象的引用计数下降到0后,Python解释器会在恰当的时候从内存中销毁这个对象,这个机制称为“垃圾回收”。
| b = a执行结果: | |
|---|---|
 |
- 如图:b = a中的赋值并没有创建新对象; - 赋值操作只是简单地把名字b也绑定到名字a绑定的对象上; - 由于a,b都绑定了同一个对象,所以id(a)与 id(b)的值相同。 |
Python的这种操作方式有其合理之处,特别是对于那些体量比较大的对象,比如列表,赋值时不创建复制品而是简单地执行名字绑定,可以快速地完成形式上的赋值。大多数情况下,这没有什么问题。如上例,虽然名字a和名字b被绑在了同一个值为2的对象上,但无论是通过名字a还是名字b取值,都可得到2;当其中一个名字,比如b被赋以不同的新值时,名字b又会被绑定到别的对象上,名字a不受影响。
同理,a += 1 等价于 a = a + 1, 通过计算后,解释器把名字a绑定在了值为3的另一个对象上,所以我们又看到了新的不同的id(a)值。
需要注意的是,Python解释器可能会出于执行速度优化的考虑,倾向于将名字尽可能绑定在系统已有的对象上,而不是创建新对象。
a = 3
b = int(a ** 2 / 3)
print(a,b)
print(id(a),id(b))
执行结果:
3 3
140720185398368 140720185398368
a被赋值为3, b也被赋值为计算出来的结果3,与预期的不一样,a和b并没有并绑定到两个不同的值为3的整数对象,而是被绑定到同一个值为3的整数对象。作者相信这是某种形式的解释器优化的结果,解释器试图尽可能快地执行代码。
is 和 ==
a = 3
b = 3.0
print("a==b:",a==b)
print("a is b:",a is b)
print(id(a),id(b))
执行结果:
a==b: True
a is b: False
140720188347488 2675211874712
每个名字所绑定的对象都至少包括三个属性:id-就是对象的内存地址;type-类型;value-对象的值。a is b将a的id与b的id作比较,只有两者相同时才返回True,这里显然a,b没有绑定到同一个对象,所以a is b返回False;a == b将两个对象的值进行比较,3等于3.0,故返回True。在实践中,为了避免不必要的麻烦,建议尽量使用==而不是is。
只读数据类型
下表列出了我们已经讨论过的全部数据类型:
| 只读数据类型 | 可修改数据类型 |
|---|---|
| 整数-int, 浮点数-float,字符串str, 布尔-bool, 二进制字节流-bytes,元组-tuple |
列表-list, 二进制字节数组-bytearray |
对于只读类型,编程者完全可以忽略名字绑定这件事,任何赋值操作的最终结果都会跟你的期望一致。
values = (3,2,1)
valuesCopy = values
valuesCopy = (1,2,3)
print(values, "-", valuesCopy)
string = "string"
stringCopy = string
stringCopy = "new string"
print(string, "-", stringCopy)
执行结果:
(3, 2, 1) - (1, 2, 3)
string - new string
可以看到,上述代码中,valuesCopy与values, stringCopy与string都曾经同时绑定到同一个只读类型对象,由于对象是只读的,所以对象无法修改,任何对valuesCopy, stringCopy的赋值都将创建一个新对象,values,string名字绑定的原有对象不受影响。
可修改数据类型
终于到了可以解决疑惑的时间了。列表-list, 二进制字节数组-bytearray属于可修改数据类型,当列表、bytearray被赋值给多个名字时,可能会导致意料之外的结果,需要十分小心。
person1 = ['10000', 'Jack Ma', 'male', 47, 'CEO']
person2 = person1
person2[1] = "Tom Henry"
print(person1)
print(person2)
执行结果:
['10000', 'Tom Henry', 'male', 47, 'CEO']
['10000', 'Tom Henry', 'male', 47, 'CEO']
请注意,第2行person2 = person1之后,两个名字事实上绑定到了同一个列表对象。由于列表是可修改类型,对person2的修改事实上是对person1和person2共同绑定的同一个对象的修改。所以,修改完成后,person1和person2打印出来的值相同。事实上,如果打印一下id(person1)和id(person2),结果肯定是一样的。
大多数情况下,两个名字绑定同一个列表对象并没有什么不好,比如,当一个列表作为函数实参传递给形参时,这种名字绑定的方法可以非常快地完成形式上的参数传递,执行效率非常高。但如果你在函数内部修改了列表的元素值,外面那个名字所绑定的列表也会跟着改变(事实上就是同一个),这可能不是你所期望的。为了避免这种情况的发生,可以借助于列表的copy()成员函数制造一个完全独立的副本,也可以借助列表的切片,比如 person1[:]来产生一个全新的副本。还可以借助于copy模块的copy()及deepcopy()函数来完成对象复制。下面的代码展示了这些方法在bytearray和list上的应用。
import copy
chars = bytearray(b'abcdefghijklmn')
charsCopy = chars.copy()
charsCopy2 = chars[:]
print(id(chars),"-",id(charsCopy),"-",id(charsCopy2))
numbers = [0,1,2,3,4,5,6,7]
numbersCopy = numbers.copy()
numbersCopy2 = numbers[:]
numbersCopy3 = copy.copy(numbers)
numbersCopy4 = copy.deepcopy(numbers)
print(id(numbers),"-",id(numbersCopy),"-",id(numbersCopy2),
"-",id(numbersCopy3),"-",id(numbersCopy4))
执行结果:
2090502934232 - 2090502931208 - 2090502950960
2090503871624 - 2090503792584 - 2090503872008 - 2090503871560 - 2090503871880
可以看到,上述名字对应对象的id值均不相同,是相互独立的对象和名字。
当列表有嵌套时,copy()和deepcopy()是有差异的。copy()只会复制列表本身,复制出来的列表(设名为b)与原列表(设名为a)的相同元素位仍可能绑定在一个相同的子列表对象上,此时,修改a的这个子列表事实上就是修改b的同一个子列表。deepcopy()会将列表及其嵌套列表完整复制,以避免上述情况。
a = [1,2,3,[3,2,1]]
b = a.copy()
print(id(a),id(b))
print(id(a[3]),id(b[3]))
b[3][2] = 99
print(a,b)
执行结果:
1989546107528 1989546601928
1989546107464 1989546107464
[1, 2, 3, [3, 2, 99]] [1, 2, 3, [3, 2, 99]]
可以看出,通过浅拷贝copy()后,a,b绑定的是两个独立的列表对象。但由于列表有子列表[3,2,1],两个列表对象的下标3位置仍然绑定了同一个子列表对象,这从id(a[3])和id(b[3])的值可以看出来。些时,修改b[3]的元素值事实上就是在修改a[3]的对应元素值。借助于b = copy.deepcopy(a),不光列表会被复制,子列表以及子列表的子列表也会被复制,这样b与a之间不再有任何联系。
import copy
a = [1,2,3,[3,2,1]]
b = copy.deepcopy(a)
print(id(a),id(b))
print(id(a[3]),id(b[3]))
b[3][2] = 99
print(a,b)
执行结果:
1723423500488 1723423499272
1723423628168 1723423628488
[1, 2, 3, [3, 2, 1]] [1, 2, 3, [3, 2, 99]]
列表的任意元素位置也可以看作是一个名字,它同具体的对象相绑定。
虽然我们已经了解了名字、对象、绑定这些背后的秘密,但本书的后续部分,我们有时仍将沿用变量、赋值这些术语,因为习惯。
本文节选自作者的《Python编程基础及应用》视频教程。想完整零基础学习Python程序设计,欢迎使用此免费视频教程。
