采集弹幕数据
导入数据并进行处理
jieba分词
设置词云参数
生成词云并保存到本地
最终效果


完整代码
# !/usr/bin/env python
# —*— coding: utf-8 —*—
# @Time: 2020/1/1 15:53
# @Author: Martin
# @File: Barrage_Analysis.py
# @Software:PyCharm
import pandas as pd
import jieba
import matplotlib.pyplot as plt
from random import randint
from wordcloud import WordCloud
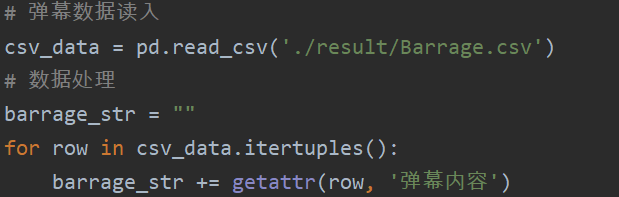
# 弹幕数据读入
csv_data = pd.read_csv('./result/Barrage.csv')
# 数据处理
barrage_str = ""
for row in csv_data.itertuples():
barrage_str += getattr(row, '弹幕内容')
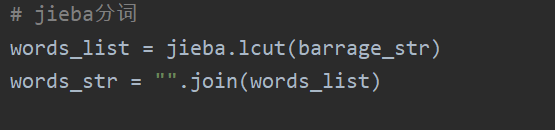
# jieba分词
words_list = jieba.lcut(barrage_str)
words_str = "".join(words_list)
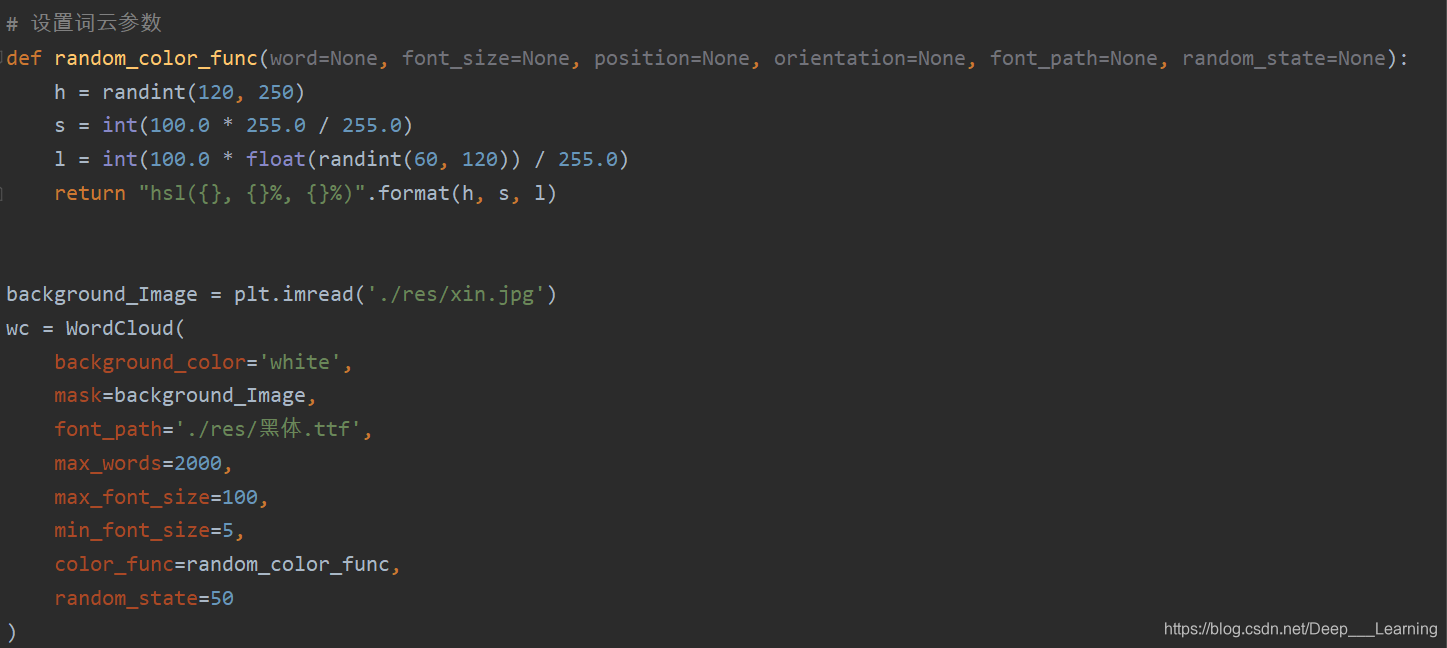
# 设置词云参数
def random_color_func(word=None, font_size=None, position=None, orientation=None, font_path=None, random_state=None):
h = randint(120, 250)
s = int(100.0 * 255.0 / 255.0)
l = int(100.0 * float(randint(60, 120)) / 255.0)
return "hsl({}, {}%, {}%)".format(h, s, l)
background_Image = plt.imread('./res/xin.jpg')
wc = WordCloud(
background_color='white',
mask=background_Image,
font_path='./res/黑体.ttf',
max_words=2000,
max_font_size=100,
min_font_size=5,
color_func=random_color_func,
random_state=50
)
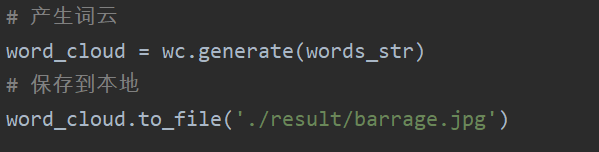
# 产生词云
word_cloud = wc.generate(words_str)
# 保存到本地
word_cloud.to_file('./result/barrage.jpg')
