谨以此文表示对一线工作者的感谢!
作为一个在特殊期间只能宅在家里做贡献的小小程序员,真的非常感激那些美丽的白衣天使们。刚好前几天学会了一些python的小应用,用代码表达我的感谢!
实现功能:
用python爬取哔哩哔哩搜索页面的所有视频弹幕,建立词云
1、爬取页面:

2、实现思路
实现思路就是从以上页面中获取所有视频的链接,比如说第一个视频的链接为:https://www.bilibili.com/video/av85319370?from=search&seid=4971102771316254686
然后我再从链接里面获取该视频号,这个视频就是av85319370,然后再从该视频页面的所有包里面找到弹幕包,就是以下两个包:
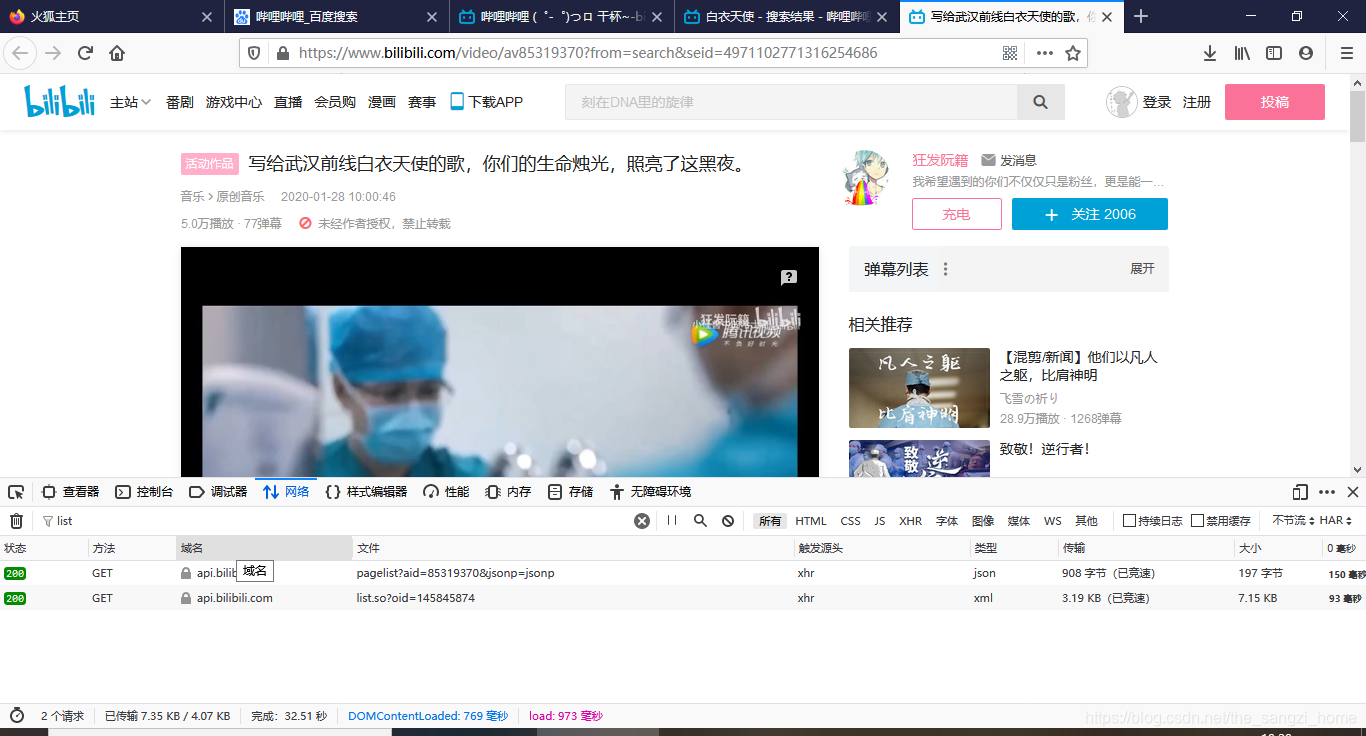
从这两个包里面我们可以知道,第二个包里面存放有该视频的所有弹幕信息,但是该视频链接的oid值存放在第一个json数据包里面,所以就得先获取第一个包的内容,再获取第二个包的内容。
将所有视频的弹幕都得到了之后,再利用jieba库进行词语截取,截取完之后将所有词语数量进行统计,最终得到数量前200的所有词语,绘制词云。。。
实现代码:
1、所需库
用于爬取页面的是 requests,BeautifulSoup, lxml,json
用于中文词汇分割的是 jieba
制作词云相关:wordcloud, numpy, PIL
2、代码
# coding=utf-8
import requests,lxml,jieba,codecs,re,json
from bs4 import BeautifulSoup
from wordcloud import WordCloud
from collections import Counter
import numpy as np
from PIL import Image
barragepath = 'C:/Users/11037/Desktop/allbarrages.txt' #存放在本地的文件位置
maskpicture = 'C:/Users/11037/Desktop/china.jpeg' #词云mask图片
wordsource = 'C:/Users/11037/Desktop/wordsource.txt' #存放制作图云词汇的文件
barrages = [] #存取所有原始弹幕
barragespages = [] #存放弹幕xml文档的页面列表
def getpage(url): #获取页面信息
html = requests.get(url).content.decode('utf-8')
return html
def getbarrage(html): #获取弹幕页面所有弹幕
bs = BeautifulSoup(html,'lxml')
dlist = bs.find_all('d')
for d in dlist:
barrages.append(d.string)
def jsongetaid(url): #从json页面中获取cid值
html = getpage(url)
data = json.loads(html)
return str(data['data'][0]['cid'])
def getAllLink(html): #得到所有弹幕的xml文档页面
global barragespages
jsonlink = [] #json页面链接
url = 'https://api.bilibili.com/x/player/pagelist?aid='
end = '&jsonp=jsonp'
pattern = re.compile('av(\d)*')
bs = BeautifulSoup(html,'lxml')
alist = bs.find('ul',class_="video-list clearfix").find_all('a')
for al in alist:
link = al['href']
match = pattern.search(link)
if match==None:
alist.remove(al)
else:
string = str(match.group())
string = string.strip('av')
string = url + string + end
jsonlink.append(string)
l2 = list(set(jsonlink))
l2.sort(key=jsonlink.index)
jsonlink = l2
newurl = 'https://api.bilibili.com/x/v1/dm/list.so?oid='
for link in jsonlink:
string = newurl + jsongetaid(link)
barragespages.append(string)
def splitbarrage(barragelist): #统计弹幕列表中重复量前200的词汇
file = codecs.open(barragepath,'wb','utf-8')
for b in barragelist:
file.write(b)
file = codecs.open(barragepath,'r','utf-8')
wordfile = codecs.open(wordsource, 'wb', 'utf-8')
text = file.read()
words = [x for x in jieba.cut(text) if len(x) >= 2]
count = Counter(words).most_common(200)
patern = re.compile("'(.*)'")
for c in count:
match = patern.search(str(c))
if match:
string = str(match.group()).strip("'")
wordfile.write(string + ' ')
wordfile.close()
def createWold(url): #创建词云
file = codecs.open(url,'r','utf-8')
text = file.read()
mask = np.array(Image.open(maskpicture))
print(text)
wordcloud = WordCloud(
background_color="White",
font_path='C:/Windows/Fonts/msyh.ttc',
width=2000,height=2000,
mask=mask).generate(text)
img = wordcloud.to_image()
img.save('C:/Users/11037/Desktop/cloudpicture.jpg')
img.show()
if __name__ == '__main__':
#搜索界面url
searchurl = 'https://search.bilibili.com/all?keyword=%E7%99%BD%E8%A1%A3%E5%A4%A9%E4%BD%BF&from_source=nav_search_new'
html = getpage(searchurl)
getAllLink(html)
for pageurl in barragespages: #遍历搜索界面的所有视频获取弹幕
print('已获取',str(pageurl),'的弹幕')
html = getpage(pageurl)
getbarrage(html)
splitbarrage(barrages)
createWold(wordsource)
运行生成的图片:


最后,祝所有的医护人员工作顺利,身体健康,祝我们的祖国繁荣昌盛!
