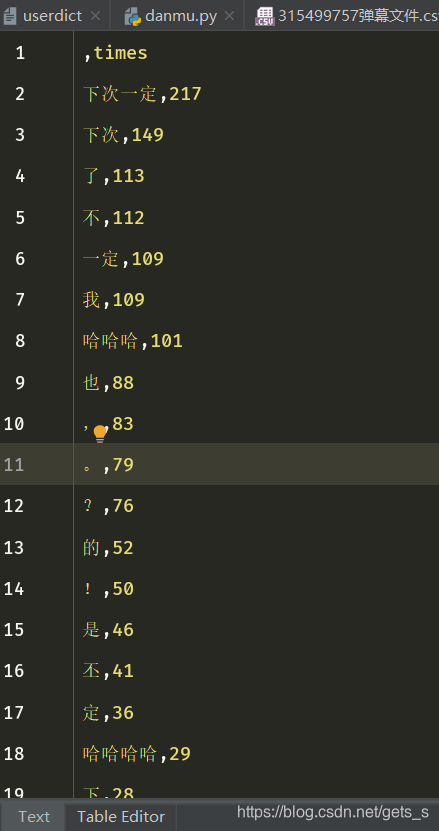
一、B站弹幕分析
B站弹幕数据存放在https://comment.bilibili.com/cid.xml中,其中cid是视频的cid号,获取需要爬取的视频的cid号的方法如下:
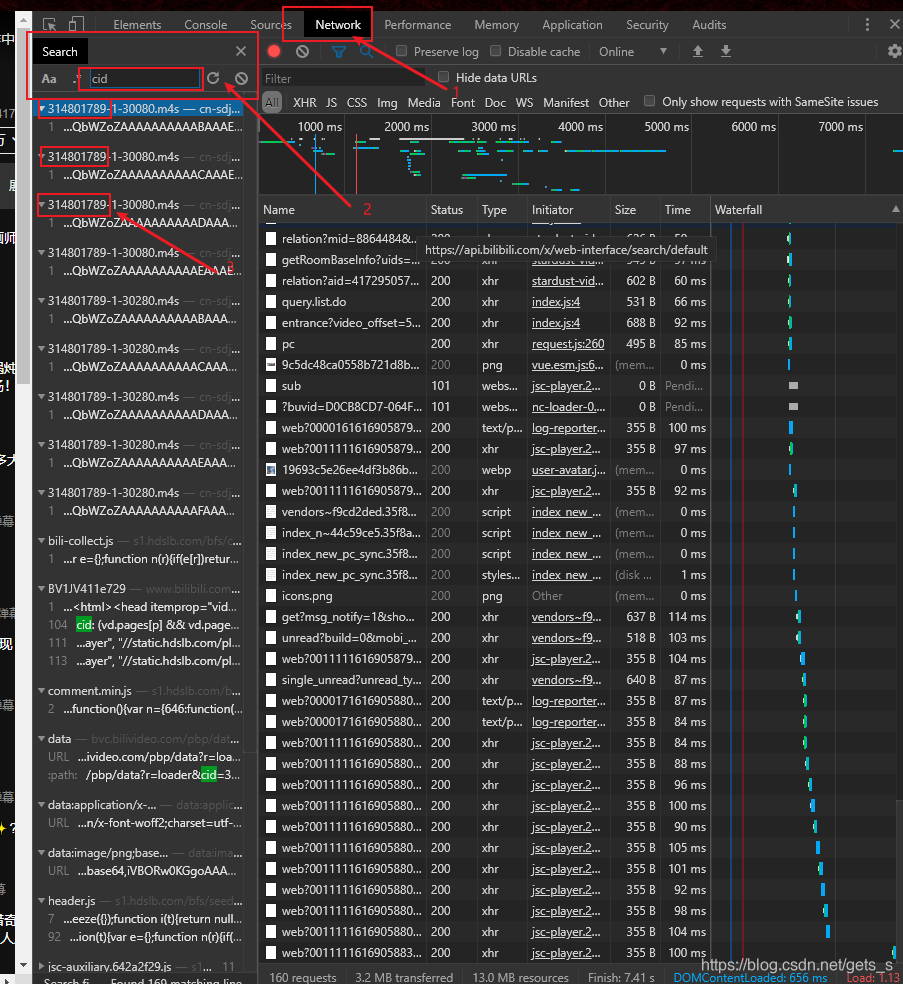
二、页面源代码
# -!- coding: utf-8 -!-
import requests
import re
import pandas as pd
import string
import jieba
def get_data(cid):
# 分析网页,并获取网页文件
url = 'https://comment.bilibili.com/{}.xml'.format(cid)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/80.0.3987.163Safari/537.36"
}
response = requests.get(url,headers = headers).content.decode('utf-8')
return response
def parse_html(response):
# 解读网页文件,获取关键信息
# soup = bs4.BeautifulSoup(response)
# lst = [soup.find_all(name='d')]
# danmuku = [i.text for i in lst]
pattern = re.compile(r'<d p=".*?">(.*?)</d>')
danmuku = re.findall(pattern,response)
return danmuku
def save_data(danmuku,cid):
# 保存数据
Dict = {
'danmuku' : danmuku
}
pd_data = pd.DataFrame(Dict)
cid = str(cid)
name = cid + '弹幕文件.csv'
path = 'D:\PyCharm\Program\pachong\Day03\弹幕数据\{}'.format(name)
pd_data.to_csv(path,index = False,header=False,mode='w',encoding='utf-8-sig')
def data_preprocess(danmuku,cid):
cid = str(cid)
name = cid + '弹幕文件.csv'
path = 'D:\PyCharm\Program\pachong\Day03\弹幕数据\{}'.format(name)
with open(path ,mode='r',encoding='utf-8') as f:
# 加载用户自定义字典
jieba.load_userdict (r'D:\PyCharm\Program\pachong\Day03\userdict')
reader = f.read().replace('\n','')
# 加载停用词词表
stopwords = [line.strip() for line in open(r'D:\PyCharm\Program\pachong\Day03\stop_wordslst',encoding ='gbk').readlines()]
# 去标点,去数字,去空白
pun_num = string.punctuation + string.digits
table = str.maketrans('','',pun_num)
reader = reader.translate(table)
seg_list = jieba.cut(reader,cut_all=False)
sentence = ''
for word in seg_list:
if word not in stopwords and word.isspace() == False:
sentence += word
sentence += ','
sentence = sentence[:-1]
return sentence
def count_words(txt,cid):
cid = str(cid)
name = cid + '弹幕词汇数统计.csv'
path = 'D:\PyCharm\Program\pachong\Day03\弹幕数据\{}'.format(name)
aDict = {
}
words = txt.split(',')
for word in words:
aDict[word] = aDict.get(word,0) + 1
pd_count = pd.DataFrame(aDict,index=['times']).T.sort_values('times',ascending=False)
pd_count.to_csv(path)
if __name__ == "__main__":
cid = int(input('请输入你想查询的视频CID号:'))
response = get_data(cid)
danmuku = parse_html(response)
save_data(danmuku,cid)
sentence = data_preprocess(danmuku,cid)
count_words(sentence,cid)
三、运行结果
1、控制台输入视频cid号,进行爬取。
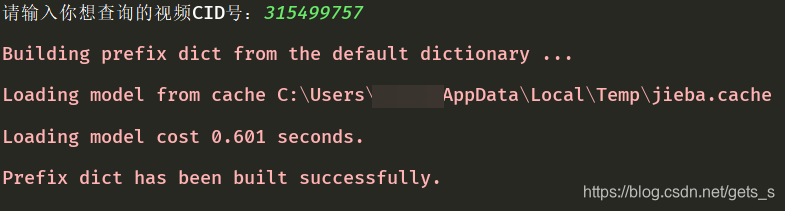
2、爬取数据存储路径
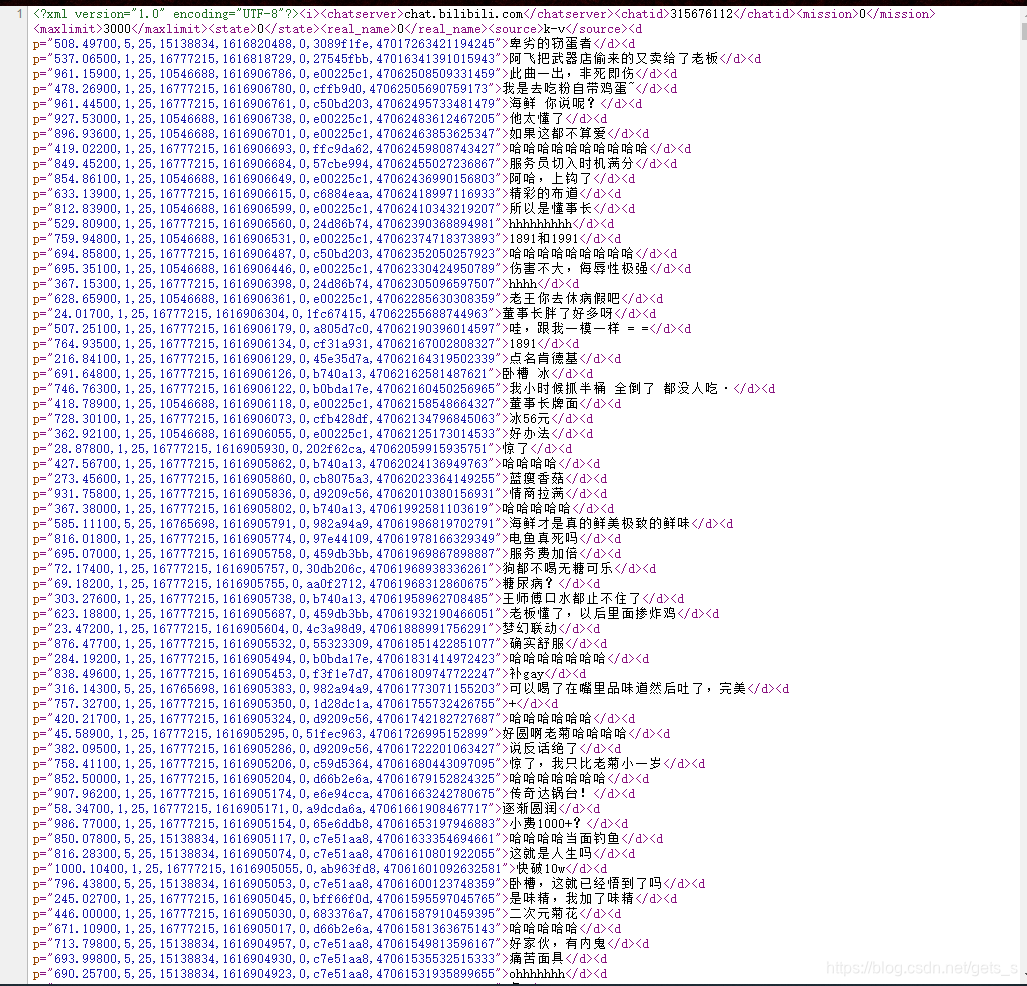
3、弹幕数据
4、弹幕词汇统计