概念
词频-逆文档频度(Term Frequency - Inverse Document Frequency,TF-IDF)技术,是一种用于资讯检索与文本挖掘的常用加权技术,可以用来评估一个词对于一个文档集或语料库中某个文档的重要程度。字词的重要性随着它在文件中出现的次数成正比增加 ,但同时会 随着它在语料库中出现的频率成反比下降 。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
原理
以统计一篇文档的关键词为例,最简单的方法就是计算每个词的词频。
词频 (term frequency, TF)指的是某一个给定的词语在该文件中出现的次数。

出现频率最高的词就是这篇文档的关键词。但是一篇文章中出现频率最高的词肯定是“的”、‘是’、‘也’……这样的词,这些词显然不能反应文章的意思,此时就需要对每个词加一个权重,最常见的词(“的”、“是”、“在”)给予最小的权重,较少见的但能反应这篇文章意思的词给予较大的权重,这个权重叫做逆文档频率。
**逆文档频率(nverse Document Frequency,IDF) **是一个词语普遍重要性的度量,它的大小与一个词的常见程度成反比,计算方法是语料库的文档总数除以语料库中包含该词语的文档数量,再将得到的商取对数。
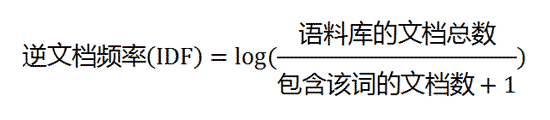
知道了TF和IDF以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。

可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
