TF-IDF简介
TF-IDF(Term Frequency-InversDocument Frequency)是一种常用于信息处理和数据挖掘的加权技术。该技术采用一种统计方法,根据字词的在文本中出现的次数和在整个语料中出现的文档频率来计算一个字词在整个语料中的重要程度。它的优点是能过滤掉一些常见的却无关紧要本的词语,同时保留影响整个文本的重要字词。
- TF(Term Frequency)表示某个关键词在整篇文章中出现的频率
- IDF(InversDocument Frequency)表示计算倒文本频率。文本频率是指某个关键词在整个语料所有文章中出现的次数。倒文档频率又称为逆文档频率,它是文档频率的倒数,主要用于降低所有文档中一些常见却对文档影响不大的词语的作用。
计算方法
通过将局部分量(词频TF)与全局分量(逆文档频率)相乘来计算tf-idf,并将所得文档标准化为单位长度。
-
计算词频(某个词在文章中的出现次数,文章有长短之分,为了便于不同文章的比较,做"词频"标准化)
词频(TF) = 某个词在文章中的出现次数 / 文章总词数
或者
词频(TF) = 某个词在文章中的出现次数 / 拥有最高词频的词的次数 -
计算逆文档频率(IDF)
逆文档频率(IDF) = log(词料库的文档总数/包含该词的文档数+1) -
计算TF-IDF
TF-IDF = 词频(TF) * 逆文档频率(IDF)
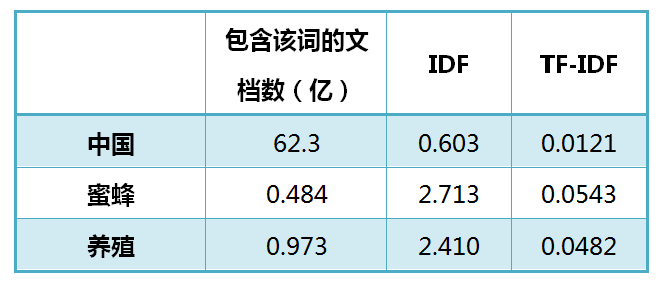
以《中国的蜜蜂养殖》为例,假定该文长度为1000个词,”中国”、”蜜蜂”、”养殖”各出现20次,则这三个词的”词频”(TF)都为0.02。然后,搜索Google发现,包含”的”字的网页共有250亿张,假定这就是中文网页总数。包含”中国”的网页共有62.3亿张,包含”蜜蜂”的网页为0.484亿张,包含”养殖”的网页为0.973亿张。则它们的逆文档频率(IDF)和TF-IDF如下:
基于Scikit-Learn库实现TF-IDF计算
Scikit-Learn简介
Scikit-learn是一个用于数据挖掘和数据分析的简单且有效的工具,它是基于Python的机器学习模块,基于BSD开源许可证。Scikit-learn的基本功能主要被分为六个部分:分类(Classification)、回归(Regression)、聚类(Clustering)、数据降维(Dimensionality reduction)、模型选择(Model selection)、数据预处理(Preprocessing)。
Scikit-Learn中的机器学习模型非常丰富,包括SVM,决策树,GBDT,KNN等等。
Scikit-Learn环境安装
- 使用conda安装:
conda install scikit-learn - 使用pip安装:
pip install scikit-learn
代码实现
Scikit-Learn中TF-IDF权重计算方法主要用到两个类:CountVectorizer和TfidfTransformer。
- CountVectorizer:将文本中的词语转换为词频矩阵;
- TfidfTransformer:统计vectorizer中每个词语的TF-IDF值;
# 导入包
from sklearn.feature_extraction.text import CountVectorizer
# 实例化CountVectorizer
vector = CountVectorizer()
# 调用fit_transform输入并转换数据
res = vector.fit_transform(["life is short,i like python","life is too long,i dislike python"])
# 打印结果
print(vector.get_feature_names())
print(res.toarray())
*************************************打印的结果**************************************
['dislike', 'is', 'life', 'like', 'long', 'python', 'short', 'too']
[[0 1 1 1 0 1 1 0]
[1 1 1 0 1 1 0 1]]
打印说明:‘dislike’, ‘is’, ‘life’, ‘like’, ‘long’, ‘python’, ‘short’, ‘too’ 列出在文章中不重复的字段,
[0 1 1 1 0 1 1 0]:在第一段中,分别出现以上对应字段的数量
#导入包
from sklearn.feature_extraction.text import TfidfTransformer
#类调用
transformer = TfidfTransformer()
print(transformer)
#将词频矩阵X统计成TF-IDF值
tfidf = transformer.fit_transform(res)
#查看数据结构 tfidf[i][j]表示i类文本中的tf-idf权重
print(tfidf.toarray())
*************************************打印的结果**************************************
TfidfTransformer(norm='l2', smooth_idf=True, sublinear_tf=False, use_idf=True)
[[0. 0.37930349 0.37930349 0.53309782 0. 0.37930349
0.53309782 0. ]
[0.47042643 0.33471228 0.33471228 0. 0.47042643 0.33471228
0. 0.47042643]]
TF-IDF优缺点
- 优点:简单快速,结果比较符合实际情况。
- 缺点:单纯以"词频"衡量一个词的重要性,不够全面,不够精确,有时重要的词可能出现次数并不多。