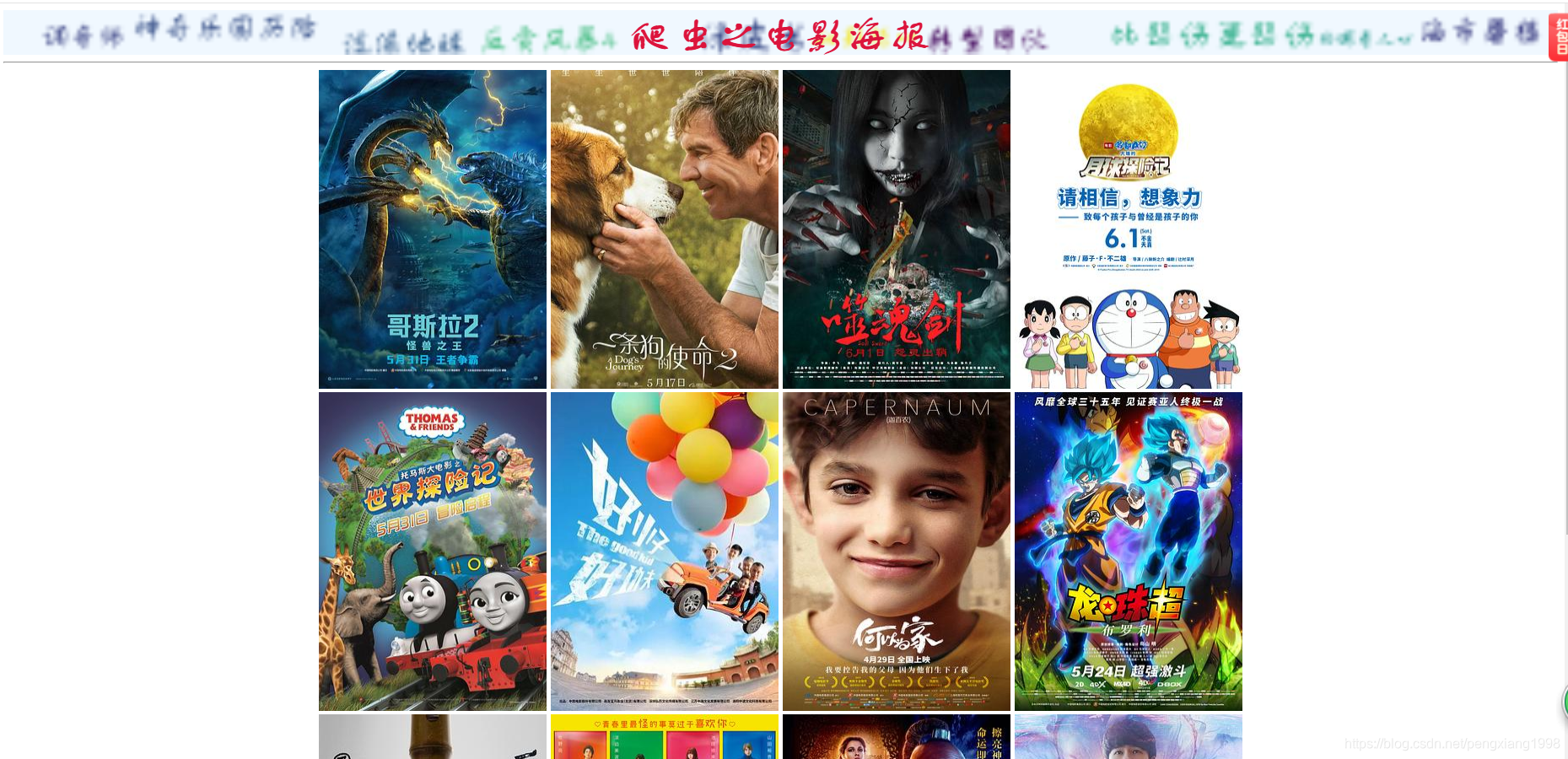
近期博主在开发项目时接触到了Python,并使用Python语言写了一个爬取豆瓣网站热门电影的小程序,在这里给大家分享一下:
需要的小伙伴可以去下载:
麻醉不易,小伙伴们给个赞吧
import os
import requests
from requests.exceptions import RequestException
import re
import time
# 根据路径获取网页内容
def get_one_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
# 提取网页内容
def parse_one_page(html):
print("-----------begin-------------")
pattern = '<li class="ui-slide-item" data-title="(.*?)" data-release.*?>.*?<ul class="">.*?<img src="(.*?)" alt=.*?/>.*?<li class="title">.*?<a onclick=.*?href="(.*?)".*?<span class="subject-rate">(.*?)</span>.*?</ul>'
items = re.findall(pattern, html, re.S)
print("----------end---------------")
l = []
for item in items:
d = {
'href': item[0],
'img': item[1],
'name': item[2],
'score': item[3]
}
l.append(d)
print(l)
return l
# 保存图片到本地
def write_img(index, src):
folder_path = os.getcwd() + '\\app\\static\\img\\'
img_name = folder_path + str(index + 1) + '.jpg'
with open(img_name, 'wb') as file:
html = requests.get(src)
file.write(html.content)
file.flush()
file.close()
# 获得电影海报图像名称列表
def get_film_list():
# 获得当前服务器路径
path = os.getcwd()
# 获得img文件夹下的所有图像名称
fl = os.listdir(str(path) + '\\app\\static\\img')
# 将图片路径修改为url路径
fls = ['/static/img/'+filename for filename in fl]
return fls
# 获得电影海报图像名称列表
def get_film_lists():
url = 'https://movie.douban.com/'
html = get_one_page(url)
fls = parse_one_page(html)
# 保存图片到本地
for index, item in enumerate(fls):
write_img(index, item['img'])
time.sleep(1)
item['img'] = '/static/img/' + str(index+1) + '.jpg'
print(item)
return fls
# 执行爬虫程序
def my_crawler():
url = 'https://movie.douban.com/'
html = get_one_page(url)
filenames = ""
for index, item in enumerate(parse_one_page(html)):
print(item)
write_img(index, item['img'])
filenames = filenames + " " + item['name']
time.sleep(1)
# 生成热门电影词云
my_film_word(filenames, 400, 15, os.getcwd() + "\\app\\static\\rmcw.png")
# 生成热映电影词云图片
def my_film_word(string, width, height, wordname):
# 使用‘方正舒体’显示汉字
font = r'C:\Windows\Fonts\FZSTK.TTF'
# 创建词云
wc = WordCloud(font_path=font,
background_color='AliceBlue',
width=width,
height=height,).generate(string)
# 保存创建好的词云图片
wc.to_file(wordname)