Python爬取豆瓣电影top250
下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析。
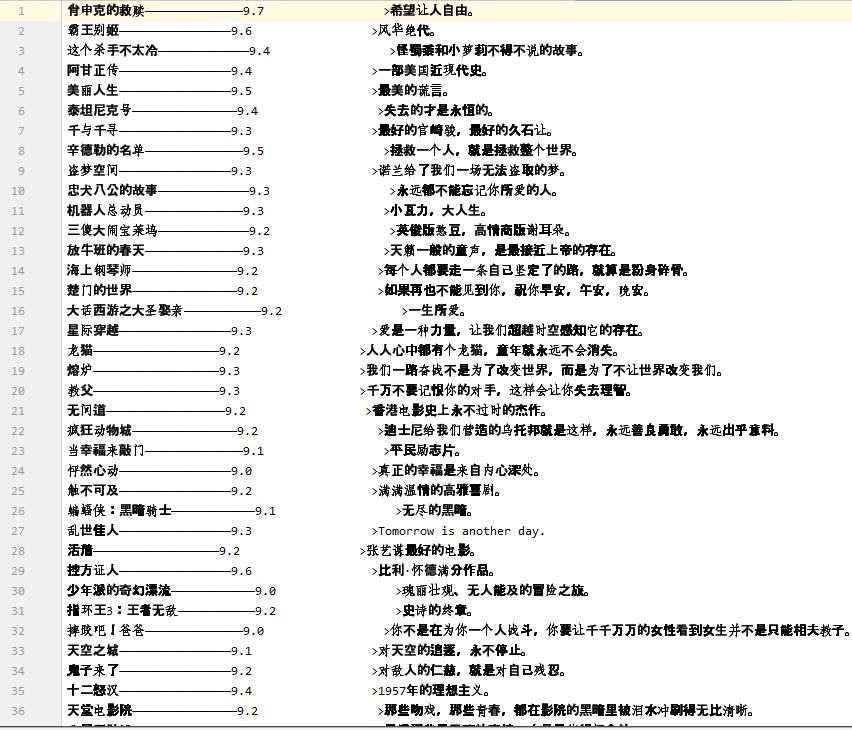
爬取信息:名称 评分 小评

结果显示
使用xpath解析数据


#python 使用xpath解析数据 #查询豆瓣top250电影 #获取信息:名称 评分 短语 #关于xpath语法:https://www.w3school.com.cn/xpath/xpath_syntax.asp from lxml import etree import time import requests import os #创建文件 t = time.strftime('%Y-%m-%d', time.localtime()) # 将指定格式的当前时间以字符串输出 suffix = ".txt" newfile ="./log/xpath_"+ t + suffix if not os.path.exists(newfile): f = open(newfile, 'w',encoding="utf-8") f.close() #打开文件,准备写入信息 f = open(newfile, 'w',encoding="utf-8") start=0 while start<250: # 查询top250电影,第页25条,取10页 r=requests.get("https://movie.douban.com/top250?start="+str(start) +"&filter=") el=etree.HTML(r.content) r.close() #解析内容 el_items=el.xpath('//div[@class="item"]') for item in el_items: #当获取子项信息时,xpath开头不能以“/”或“//”开头,“//”是查询整个html。开始一定要指当前子项,后面可以使用“/”或“//”来搜索 title=item.xpath('div//span[@class="title"][1]/text()')[0] #标题 rating_num=item.xpath('div//span[@class="rating_num"][1]/text()')[0]#评分 # 小评可能不存在,在此加判断 inq=item.xpath('div//span[@class="inq"][1]/text()')#小评 inq_str="" if len(inq)>0: inq_str=inq[0] #写入文件 f.write(str(title).strip().ljust(20,'—')+str(rating_num).strip().ljust(20,' ')+">"+str(inq_str).strip().ljust(50,' ')+"\n") start+=25 #最后关闭文件 f.close() print("the end")
使用pyquery解析数据
#python 使用pyquery解析数据 #查询豆瓣top250电影 #获取信息:名称 评分 短语 #关于pyquery语法:https://pyquery.readthedocs.io/en/latest/pseudo_classes.html from pyquery import PyQuery as pq import time import requests import os #创建文件 t = time.strftime('%Y-%m-%d', time.localtime()) # 将指定格式的当前时间以字符串输出 suffix = ".txt" newfile ="./log/pyquery_"+ t + suffix if not os.path.exists(newfile): f = open(newfile, 'w',encoding="utf-8") f.close() #打开文件,准备写入信息 f = open(newfile, 'w',encoding="utf-8") start=0 while start<250: #查询top250电影,第页25条,取10页 r = requests.get("https://movie.douban.com/top250?start=" + str(start) + "&filter=") d=pq(r.content) r.close() items=d('.item') for item in items: item_d=pq(item)#重新加载每一项html,为下面取出信息 title= item_d.find(".title:eq(0)").text()#名称 rating_num =item_d.find(".rating_num:eq(0)").text()# 评分 inq_str = item_d.find('.inq:eq(0)').text() # 小评 # 写入文件 f.write(str(title).strip().ljust(20,'—')+str(rating_num).strip().ljust(20,' ')+">"+str(inq_str).strip().ljust(50,' ')+"\n") start+=25 #最后关闭文件 f.close() print("the end")
使用BeaufifulSoup解析数据
#python 使用BeaufifulSoup解析数据 #查询豆瓣top250电影 #获取信息:名称 评分 短语 #关于语法:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ from bs4 import BeautifulSoup import time import requests import os #创建文件 t = time.strftime('%Y-%m-%d', time.localtime()) # 将指定格式的当前时间以字符串输出 suffix = ".txt" newfile ="./log/BeaufifulSoup_"+ t + suffix if not os.path.exists(newfile): f = open(newfile, 'w',encoding="utf-8") f.close() #打开文件,准备写入信息 f = open(newfile, 'w',encoding="utf-8") start=0 while start<250: #查询top250电影,第页25条,取10页 r=requests.get("https://movie.douban.com/top250?start="+str(start) +"&filter=") el=BeautifulSoup(r.content,"xml") r.close() items=el.find_all("div", class_="item")#获取一项电影信息 for item in items: title=item.find_all(class_="title",limit=1)[0].get_text()#名称 rating_num=item.find_all('span',class_="rating_num",limit=1)[0].get_text() # 评分 # 小评可能不存在,在此加判断 inq = item.find_all('span',class_="inq",limit=1) # 小评 inq_str = "" if len(inq) > 0: inq_str = inq[0].get_text() f.write(str(title).strip().ljust(20,'—')+str(rating_num).strip().ljust(20,' ')+">"+str(inq_str).strip().ljust(50,' ')+"\n") #print(str(title).strip().ljust(20,'—')+str(rating_num).strip().ljust(20,' ')+">"+str(inq_str).strip().ljust(50,' ')+"\n") start+=25 #最后关闭文件 f.close() print("the end")
使用re正则匹配
#python 使用re正则匹配 #查询豆瓣top250电影 #获取信息:名称 评分 短语 import re import time import requests import os reg_items=re.compile('<li>[\r\n\s]+<div\s+class="item">[.\r\n\s\S]*?</li>')#每个电影 reg_title=re.compile('(?<=title">)[^<]+')#电影名称 reg_rating_num=re.compile('(?<=property="v:average">)[^<]+')#评分 reg_inq=re.compile('(?<=class="inq">)[^<]+')#小评 #创建文件 t = time.strftime('%Y-%m-%d', time.localtime()) # 将指定格式的当前时间以字符串输出 suffix = ".txt" newfile ="./log/re_"+ t + suffix if not os.path.exists(newfile): f = open(newfile, 'w',encoding="utf-8") f.close() #打开文件,准备写入信息 f = open(newfile, 'w',encoding="utf-8") start=0 while start<250: #查询top250电影,第页25条,取10页 r = requests.get("https://movie.douban.com/top250?start=" + str(start) + "&filter=") html=str(r.content,encoding = "utf-8") r.close() maths= reg_items.findall(html) for item in maths: re_title=reg_title.search(item) title=re_title.group(0) re_rating_num=reg_rating_num.search(item) rating_num=re_rating_num.group(0) inq_str="" #小评可能不存在,在此加判断 re_inq=reg_inq.search(item) if re_inq!=None: inq_str=re_inq.group(0) f.write(str(title).strip().ljust(20, '—') + str(rating_num).strip().ljust(20, ' ') + ">" + str( inq_str).strip().ljust(50, ' ') + "\n") #print(str(title).strip().ljust(20,'—')+str(rating_num).strip().ljust(20,' ')+">"+str(inq_str).strip().ljust(50,' ')+"\n") start+=25 #最后关闭文件 f.close() print("the end")
为毛要这么方法去解析?从众多方式做一个比较,那种方式有优势,解析起来更方便。以后需要解析的时候,从中选择最优的。
来源:https://www.cnblogs.com/cai-niao/p/11372087.html 黑白记忆
扫描二维码关注公众号,回复:
7056459 查看本文章
