参考:https://blog.csdn.net/lxiaoxiaot/article/details/6779936
一、SLAM知识树
SLAM需要具备三维空间刚体变换(四元数、旋转矩阵)、相机成像模型、特征点提取与匹配、多视角几何、非线性优化等内容。

注释:
a.泰勒公式是将一个在x=x0处具有n阶导数的函数f(x)利用关于(x-x0)的n次多项式来逼近函数的方法。
若函数f(x)在包含x0的某个闭区间[a,b]上具有n阶导数,且在开区间(a,b)上具有(n+1)阶导数,则对闭区间[a,b]上任意一点x,成立下式:
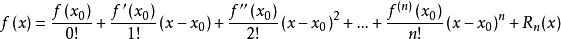
其中,
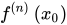
表示f(x)的n阶导数,等号后的多项式称为函数f(x)在x0处的泰勒展开式,剩余的Rn(x)是泰勒公式的余项,是(x-x0)n的高阶无穷小。
 泰勒公式
泰勒公式
b.LSD-SLAM跟踪了所有梯度明显的像素。
(一)在项目代码方面,当前典型的一些开源SLAM方案:
稀疏法(Sparse SLAM) :
1、ORB-SLAM2(Mono、Stero、RGB-D)
半稠密法(Semi-Dense SLAM):
1、LSD-SLM(Mono、Stero、RGB-D)
2、DSO(Mono)
稠密法(Dense SLAM):
1、lastic Fusion (RGB-D)
2、Bundle Fusion(RGB-D)
3、Mask Fusion
4、Kinect Fusion
5、InfiniTAM
6、RGB-D-SLAM V2(RGB-D)
多传感器融合(Multisensor fusion):
1、VINS(Mono+IMU)
2、OKVIS(Mono、Stero、四目MU)
(二)开发SLAM常用到的工具库:
1、OpenNI:用于与视觉传感器的交互操作;
2、OpenCV:用于图像处理;
3、PCL:用于点云处理;
4、Eigen:用于矩阵运算;是一个高层次的c++库,有效支持线性代数,矩阵和矢量运算,数值分析及其相关的算法。
5、Sophus:用于李群李代数计算;
6、Ceres Solver:是谷歌的后端优化库,用于非线性优化;
7、g2o:用于图优化;
8、DBoW:用于处理词袋模型;
9、OpenGL:用于模型渲染;
10、CUDA toolkit:用于并行计算,等等。
BA的本质是一个优化模型,其目的是最小化重投影误差。
二、视觉里程计(Visual Odometry)http://en.wikipedia.org/wiki/Visual_odometry
在机器人学与计算机视觉领域,视觉里程计是一个通过分析相关图像序列,来确定机器人位置和朝向的过程。
在导航系统中,里程计(odometry)是一种利用致动器的移动数据来估算机器人位置随时间改变量的方法。例如,测量轮子转动的旋转编码器设备。里程计总是会遇到精度问题,例如轮子的打滑就会导致产生机器人移动的距离与轮子的旋转圈数不一致的问题。当机器人在不光滑的表面运动时,误差是由多种因素混合产生的。由于误差随时间的累积,导致了里程计的读数随着时间的增加,而变得越来越不可靠。视觉里程计是一种利用连续的图像序列来估计机器人移动距离的方法。视觉里程计增强了机器人在任何表面以任何方式移动时的导航精度。
视觉里程计算法:
大多数现有的视觉里程计算法都是基于以下几个步骤:
1、图像获取:单目照相机、双目照相机或者全向照相机;
2、图像校正:使用一些图像处理技术来去除透镜畸变;
3、特征检测:确定感兴趣的描述符,在帧与帧之间匹配特征并构建光流场;直接法是视觉里程计另一主要分支,它与特征点法有很大不同。包括稀疏、半稠密和稠密直接法。
(1)使用相关性来度量两幅图像间的一致性,并不进行长时间的特征跟踪;
(2)特征提取、匹配(Lucas–Kanade method);
(3)构建光流场;
4、检查光流场向量是否存在潜在的跟踪误差,移除外点;
5、由光流场估计照相机的运动;
(1)可选方法1:使用卡尔曼滤波进行状态估计;
(2)可选方法2:查找特征的几何与3D属性,以最小化基于相邻两帧之间的重投影误差的罚函数值。这可以通过数学上的最小化方法或随机采样方法来完成;
6、周期性的重定位跟踪点;

三、SVO(semi-direct monocular visual odometr)是苏黎世大学感知组于
2014年在ICAR会上发布,已开源。
2016年扩展成多目相机+IMU,称SVO2.0,Christion Forster发布于IEEE ON ROBOTICS。
1、SVO的实现中,混合实现了特征点(ORB-SLAM)与直接法(DSO):它跟踪了一些关键点(角点,没有描述子,由FAST实现),然后像直接法那样,根据关键点周围的信息,估计相机运动以及它们的位置。SVO跟踪的“关键点”可以称为梯度明显的像素,和LSD-SLAM相近,LSD-SLAM跟踪了所有梯度明显的像素,形成半稠密地图而SVO只跟踪稀疏的关键点。
2、SVO另一个特点是实现了一种特有的Depth Filter, 是一种基于均匀-高斯混合分布的Depth Filter,由弗吉尼亚大学于2011年提出并推导。SVO将这种滤波器用于关键点的深度估计,并使用逆深度作为参数化形式使之能够更好的计算特征点位置。
初学者可以SVO或ORB开始读取,开源版的SVO代码清晰易读。
SVO整体框架:Motion Estimation Thread运动估计线程和Mapping Thraed建图线程。
整个过程分为两大模块:追踪和建图(与PTAM类似)
上半部分为追踪部分,主要任务是估计当前帧的位姿。分两步:
(1)先把当前帧和上一追踪成功的一帧进行比较,获取粗略位姿。
(2)后根据粗略的位姿,将它和地图之间的特征点进行比较,得到精确位姿并优化见到的地图点。后判断是否为关键帧。是则提取特征点,把这些点作为地图种子点,放入优化线程。否则,用此帧的信息更新地图中种子点的深度估计值。—此步骤是为了减少较大的累积误差。
下半部分位建图部分,主要任务是**估计特征点的深度。**因为在单目SLAM中刚提的特征点是没有深度的,所以必须用新来的帧的信息去更新这些特征点的深度信息,也就是所谓的深度滤波器。
当某个点的深度收敛时,用它生成新的地图点,放进地图中,在被追踪部分使用。
整个SVO架构要比ORB简单一些(ORB有三个线程,而且要处理关键帧的共视关系和回环检测),故SVO效率高。
优点:速度快,关键点分布比较均匀。
缺点:(1)它是VO而非SLAM,无闭环。意味着丢失后无法重新定位一丢就挂。
(2)追踪部分:SVO有直接法的所有缺点。怕模糊(需要全局曝光相机)、怕大运动(图像非凸性)、怕光照变化(灰度不变假设)。
(3)地图部分:深度滤波器收敛较慢,很依赖于准确的位姿估计。如统计收敛的种子点的比例,比例不高,很多计算浪费在不收敛的点上。
相比较于高斯的逆深度,SVO的深度滤波器主要特点是能通过Beta分布中的两个参数a和b来判断一个种子点是否为outlier。然而在特征点法中我们也能够通过描述来判断outlier,所以并不具明显优势。
小结:SVO是基于稀疏直接法的VO,速度快。
代码清晰易读,研究SVO会有不少启发。
开源代码是部分开源,论文效果非开源代码可实现。
