前向神经网络
实验环境
keras 2.1.5
tensorflow 1.4.0
实验工具
Jupyter Notebook
实验一:手写数字分类
实验目的
将手写数字的灰度图像(28像素×28像素)分类为10个类别(0到9)。
数据集
MNIST数据集:
MNIST数据集,它是机器学习领域中的一个经典数据集。这是一套60000个训练图像,外加10,000个测试图像,由国家标准与技术研究院(NIST在MNIST)在20世纪80年代制定而成。你可以将“解决”MNIST分类问题认为深度学习的“Hello World” -
实验过程
1.处理数据集:
MNIST数据集在Keras中预先压缩为为一个四维Numpy数组。
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
#如果datasets中没有数据集,则会自动下载mnist数据集
'''
A local file was found, but it seems to be incomplete or outdated because the auto file hash does not match the original value of 8a61469f7ea1b51cbae51d4f78837e45 so we will re-download the data.
Downloading data from https://s3.amazonaws.com/img-datasets/mnist.npz
11493376/11490434 [==============================] - 25s 2us/step
'''
2.训练集与测试集:
train_images和train_labels构成了“训练集”,即模型将学习的数据。 然后模型将在“测试集”,test_images和test_labels上进行测试。
我们的图像被编码为Numpy数组,标签(标签)只是一个数字数组,范围从0到9.图像和标签之间存在一一对应的关系。
#训练集数据:
train_images.shape
'''
(60000, 28, 28)
'''
len(train_labels)
'''
60000
'''
train_labels
'''
array([5, 0, 4, ..., 5, 6, 8], dtype=uint8)
'''
#测试集数据:
test_images.shape
'''
(10000, 28, 28)
'''
len(test_labels)
'''
10000
'''
test_labels
'''
array([7, 2, 1, ..., 4, 5, 6], dtype=uint8)
'''
3.建立网络:
向神经网络输入训练数据train_images和train_labels。
#建立网络
from keras import models
from keras import layers
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
network.add(layers.Dense(10, activation='softmax'))
神经网络层:
神经网络的核心构建块是“层”,这是一个数据处理模块,网络层从提供给它们的数据中提取特征。
在这里,我们的网络由一系列两个“全连接”层组成,是密集连接(也称为“完全连接”)的神经层。第二层是10个输出的“softmax”层,每个分数将是当前数字图像属于我们的10位数类别之一的概率。
4.准备:
损失函数:网络将如何衡量其在训练数据上的工作性能,以及如何能够在正确的方向上引导自己。
优化器:这是网络根据其看到的数据及其损失函数自行更新的机制。
训练和测试过程中的监督矩阵。
network.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
5.缩放数据:
训练之前,我们将通过将数据重塑为网络预期的形状来预处理数据,并对其进行缩放,以使所有值都处于[0,1]区间。
之前,我们的训练图像例如存储在类型为uint8的形状数组(60000, 28,28)中,值为[0,255]间隔。 我们将它转换为一个形状为float32的数组(60000,28 * 28)(值在0到1之间)。

train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype('float32') / 255
6.对标签分类编码:
from keras.utils import to_categorical
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
7.拟合:
在Keras中通过调用网络的“fit”方法完成,将该模型“拟合”到其训练数据中。
network.fit(train_images, train_labels, epochs=5, batch_size=128)
#训练期间显示两个参数:网络训练目标的损失函数的值以及对训练数据分类的精确度。
'''
Epoch 1/5
60000/60000 [==============================] - 10s 161us/step - loss: 0.2564 - acc: 0.9254
Epoch 2/5
60000/60000 [==============================] - 10s 163us/step - loss: 0.1029 - acc: 0.9697
Epoch 3/5
60000/60000 [==============================] - 9s 146us/step - loss: 0.0677 - acc: 0.9796
Epoch 4/5
60000/60000 [==============================] - 9s 145us/step - loss: 0.0494 - acc: 0.9850
Epoch 5/5
60000/60000 [==============================] - 9s 149us/step - loss: 0.0363 - acc: 0.9895
<keras.callbacks.History at 0x1b19a7beb00>
'''
8.测试:
看一下模型在测试集上的表现。
test_loss, test_acc = network.evaluate(test_images, test_labels)
'''
10000/10000 [==============================] - ETA: - 1s 112us/step
'''
print('test_acc:', test_acc)
'''
test_acc: 0.9776
'''
#我们的测试集精度为97.8%-这比训练集精度要低很多。
#培训准确性和测试准确性之间的差距是“过度拟合”的一个例子,机器学习模型往往在新数据上比在训练数据上更差。
代码整合
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
from keras import models
from keras import layers
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
network.add(layers.Dense(10, activation='softmax'))
network.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype('float32') / 255
from keras.utils import to_categorical
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
network.fit(train_images, train_labels, epochs=5, batch_size=128)
test_loss, test_acc = network.evaluate(test_images, test_labels)
print('test_acc:', test_acc)
实验二:新闻分类
实验目的
建立一个网络将路透新闻报道分为46个不同类别。
数据集
路透社数据集:
Reuters数据集,它包含路透社于1986年出版的短篇新闻及其对应主题,它是一个简单且被广泛使用的文本分类数据集。数据集中有46个不同的主题;其中一些主题出现的次数较多,但每个主题在训练集中至少有10个示例。
实验过程
1.处理数据集:
Reuters数据集在Keras中预先压缩为为一个四维Numpy数组。
from keras.datasets import reuters
#num_words=10000表示从数据集中找到的10,000个最常出现的单词。
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
2.数据量:
有8,982个训练样本和2,246个测试样本。
len(train_data)
'''
8982
'''
len(test_data)
'''
2246
'''
#每个样本都是一个整数列表(整数代表单词索引)。
train_data[10]
'''
[1,
245,
273,
207,
156,
53,
74,
160,
26,
14,
46,
296,
26,
39,
74,
2979,
3554,
14,
46,
4689,
4329,
86,
61,
3499,
4795,
14,
61,
451,
4329,
17,
12]
'''
3.如何将整数列表映射为单词:
word_index = reuters.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
# Note that our indices were offset by 3
# because 0, 1 and 2 are reserved indices for "padding", "start of sequence", and "unknown".
decoded_newswire = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
decoded_newswire
'''
'? ? ? said as a result of its december acquisition of space co it expects earnings per share in 1987 of 1 15 to 1 30 dlrs per
share up from 70 cts in 1986 the company said pretax net should rise to nine to 10 mln dlrs from six mln dlrs in 1986 and rental
operation revenues to 19 to 22 mln dlrs from 12 5 mln dlrs it said cash flow per share this year should be 2 50 to three dlrs
reuter 3'
'''
3.标签:
标签是0到45之间的整数,表示主题索引。
train_labels[10]
'''
3
'''
4.对数据进行矢量化处理:
mport numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
# Our vectorized training data
x_train = vectorize_sequences(train_data)
# Our vectorized test data
x_test = vectorize_sequences(test_data)
矢量化
标签的矢量化有两种方法:一种是将标签列表整合成整数张量,另一种是使用“独热”编码。 独热编码是广泛使用的分类数据格式,也称为“分类编码”。
在我们的情况中,我们标签的独热编码后的向量中,标签索引对应的分类为1,其余分类为0,如下。
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
# Our vectorized training labels
one_hot_train_labels = to_one_hot(train_labels)
# Our vectorized test labels
one_hot_test_labels = to_one_hot(test_labels)
#keras有内置方法:
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
5.建立网络:
全连接层网络的每层只能访问前一层输出中存在的信息。如果其中的一层丢弃了与分类问题相关的部分信息,则该信息永远不会被后面的网络层恢复:每个层都有可能成为“信息瓶颈”。
我们将使用64个单元的中间层。
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
注意:
我们用一个大小为46的输出向量。这意味着对于每个输入样本,网络将输出一个46维向量。此向量中的每个维度对应不同的输出类。
最后一层使用softmax激活。这意味着网络将输出46个不同输出类别的概率分布,即对于每个输入样本,网络将产生46维输出向量,其中输出[i]是样本属于类别i的概率。 46维得分的和为1。
5.准备:
在这种情况下使用的损失函数是categorical_crossentropy。该函数能测量两个概率分布之间的距离:在本例中,我们网络输出的概率分布与标签的真实分布之间的距离。通过最小化这两个分布之间的距离,我们训练我们的网络输出尽可能接近真实标签。
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
6.验证网络性能:
在训练数据中设置1000个样本作为验证集,采用20次迭代训练我们的网络。
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
'''
Train on 7982 samples, validate on 1000 samples
Epoch 1/20
7982/7982 [==============================] - 3s 425us/step - loss: 2.5322 - acc: 0.4955 - val_loss: 1.7208 - val_acc: 0.6120
Epoch 2/20
7982/7982 [==============================] - 2s 301us/step - loss: 1.4452 - acc: 0.6877 - val_loss: 1.3459 - val_acc: 0.7060
Epoch 3/20
7982/7982 [==============================] - 2s 294us/step - loss: 1.0956 - acc: 0.7655 - val_loss: 1.1715 - val_acc: 0.7430
Epoch 4/20
7982/7982 [==============================] - 2s 294us/step - loss: 0.8700 - acc: 0.8160 - val_loss: 1.0795 - val_acc: 0.7590
Epoch 5/20
7982/7982 [==============================] - 2s 299us/step - loss: 0.7035 - acc: 0.8474 - val_loss: 0.9845 - val_acc: 0.7820
Epoch 6/20
7982/7982 [==============================] - 2s 300us/step - loss: 0.5666 - acc: 0.8797 - val_loss: 0.9409 - val_acc: 0.8030
Epoch 7/20
7982/7982 [==============================] - 2s 295us/step - loss: 0.4582 - acc: 0.9048 - val_loss: 0.9082 - val_acc: 0.8020
Epoch 8/20
7982/7982 [==============================] - 2s 300us/step - loss: 0.3696 - acc: 0.9227 - val_loss: 0.9359 - val_acc: 0.7880
Epoch 9/20
7982/7982 [==============================] - 2s 300us/step - loss: 0.3034 - acc: 0.9310 - val_loss: 0.8928 - val_acc: 0.8070
Epoch 10/20
7982/7982 [==============================] - 2s 298us/step - loss: 0.2539 - acc: 0.9414 - val_loss: 0.9060 - val_acc: 0.8120
Epoch 11/20
7982/7982 [==============================] - 2s 299us/step - loss: 0.2188 - acc: 0.9465 - val_loss: 0.9170 - val_acc: 0.8140
Epoch 12/20
7982/7982 [==============================] - 2s 296us/step - loss: 0.1874 - acc: 0.9514 - val_loss: 0.9048 - val_acc: 0.8140
Epoch 13/20
7982/7982 [==============================] - 2s 298us/step - loss: 0.1704 - acc: 0.9524 - val_loss: 0.9339 - val_acc: 0.8100
Epoch 14/20
7982/7982 [==============================] - 2s 298us/step - loss: 0.1536 - acc: 0.9551 - val_loss: 0.9684 - val_acc: 0.8060
Epoch 15/20
7982/7982 [==============================] - 2s 296us/step - loss: 0.1390 - acc: 0.9558 - val_loss: 0.9706 - val_acc: 0.8160
Epoch 16/20
7982/7982 [==============================] - 2s 300us/step - loss: 0.1317 - acc: 0.9559 - val_loss: 1.0247 - val_acc: 0.8040
Epoch 17/20
7982/7982 [==============================] - 2s 297us/step - loss: 0.1218 - acc: 0.9579 - val_loss: 1.0240 - val_acc: 0.7970
Epoch 18/20
7982/7982 [==============================] - 2s 300us/step - loss: 0.1199 - acc: 0.9577 - val_loss: 1.0433 - val_acc: 0.8070
Epoch 19/20
7982/7982 [==============================] - 2s 296us/step - loss: 0.1136 - acc: 0.9597 - val_loss: 1.1016 - val_acc: 0.7950
Epoch 20/20
7982/7982 [==============================] - 2s 295us/step - loss: 0.1110 - acc: 0.9595 - val_loss: 1.0725 - val_acc: 0.8010
'''
7.显示训练过程中损失和准确度曲线:
import matplotlib.pyplot as plt
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
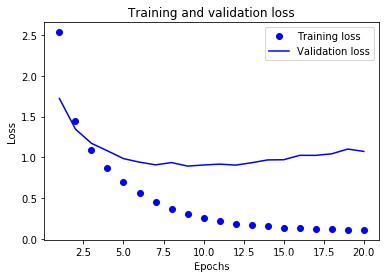
plt.clf() # clear figure
acc = history.history['acc']
val_acc = history.history['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()

8.调整:
看起来网络在8次迭代后开始过拟合。现在头开始训练一个网络,仅仅进行8次迭代,然后在测试集上评估它。
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=8,
batch_size=512,
validation_data=(x_val, y_val))
results = model.evaluate(x_test, one_hot_test_labels)
'''
Train on 7982 samples, validate on 1000 samples
Epoch 1/8
7982/7982 [==============================] - 3s 372us/step - loss: 2.5398 - acc: 0.5226 - val_loss: 1.6733 - val_acc: 0.6570
Epoch 2/8
7982/7982 [==============================] - 2s 298us/step - loss: 1.3712 - acc: 0.7121 - val_loss: 1.2758 - val_acc: 0.7210
Epoch 3/8
7982/7982 [==============================] - 2s 301us/step - loss: 1.0136 - acc: 0.7781 - val_loss: 1.1303 - val_acc: 0.7530
Epoch 4/8
7982/7982 [==============================] - 2s 301us/step - loss: 0.7976 - acc: 0.8251 - val_loss: 1.0539 - val_acc: 0.7590
Epoch 5/8
7982/7982 [==============================] - 2s 299us/step - loss: 0.6393 - acc: 0.8624 - val_loss: 0.9754 - val_acc: 0.7920
Epoch 6/8
7982/7982 [==============================] - 2s 299us/step - loss: 0.5124 - acc: 0.8923 - val_loss: 0.9102 - val_acc: 0.8140
Epoch 7/8
7982/7982 [==============================] - 2s 301us/step - loss: 0.4123 - acc: 0.9137 - val_loss: 0.8932 - val_acc: 0.8210
Epoch 8/8
7982/7982 [==============================] - 2s 296us/step - loss: 0.3354 - acc: 0.9288 - val_loss: 0.8732 - val_acc: 0.8260
2246/2246 [==============================] - 1s 417us/step
'''
results
'''
[0.98474704720351913, 0.7845057880676759]
'''
#纯随机分类器达到的精度:
import copy
test_labels_copy = copy.copy(test_labels)
np.random.shuffle(test_labels_copy)
float(np.sum(np.array(test_labels) == np.array(test_labels_copy))) / len(test_labels)
'''
0.19145146927871773
'''
9.对未知数据进行预测
#让我们为所有测试数据生成主题预测:
predictions = model.predict(x_test)
#每个预测结构都是长度为46的矢量:
predictions[0].shape
'''
(46,)
'''
#该向量中分量总和为1:
np.sum(predictions[0])
'''
1.0000001
'''
#最大概率的分量收对应的类别即是预测的类别:
np.argmax(predictions[0])
'''
3
'''
10.处理标签和损失的不同方式:
将标签转换为整数张量,损失函数为sparse_categorical_crossentropy。
y_train = np.array(train_labels)
y_test = np.array(test_labels)
model.compile(optimizer='rmsprop',
loss='sparse_categorical_crossentropy',
metrics=['acc'])
11.论足够大中间层的重要性:
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(4, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=128,
validation_data=(x_val, y_val))
'''
Train on 7982 samples, validate on 1000 samples
Epoch 1/20
7982/7982 [==============================] - 2s 312us/step - loss: 3.4774 - acc: 0.0499 - val_loss: 3.0745 - val_acc: 0.0890
Epoch 2/20
7982/7982 [==============================] - 2s 266us/step - loss: 2.4183 - acc: 0.4193 - val_loss: 1.8660 - val_acc: 0.6210
Epoch 3/20
7982/7982 [==============================] - 2s 269us/step - loss: 1.4443 - acc: 0.6463 - val_loss: 1.4424 - val_acc: 0.6470
Epoch 4/20
7982/7982 [==============================] - 2s 247us/step - loss: 1.1830 - acc: 0.6941 - val_loss: 1.3433 - val_acc: 0.6830
Epoch 5/20
7982/7982 [==============================] - 2s 238us/step - loss: 1.0399 - acc: 0.7310 - val_loss: 1.3071 - val_acc: 0.6850
Epoch 6/20
7982/7982 [==============================] - 2s 235us/step - loss: 0.9338 - acc: 0.7607 - val_loss: 1.3111 - val_acc: 0.7040
Epoch 7/20
7982/7982 [==============================] - 2s 216us/step - loss: 0.8492 - acc: 0.7823 - val_loss: 1.2657 - val_acc: 0.7140
Epoch 8/20
7982/7982 [==============================] - 2s 229us/step - loss: 0.7799 - acc: 0.8037 - val_loss: 1.2918 - val_acc: 0.7180
Epoch 9/20
7982/7982 [==============================] - 2s 228us/step - loss: 0.7208 - acc: 0.8158 - val_loss: 1.2940 - val_acc: 0.7190
Epoch 10/20
7982/7982 [==============================] - 2s 226us/step - loss: 0.6717 - acc: 0.8287 - val_loss: 1.2902 - val_acc: 0.7170
Epoch 11/20
7982/7982 [==============================] - 2s 234us/step - loss: 0.6279 - acc: 0.8400 - val_loss: 1.3324 - val_acc: 0.7250
Epoch 12/20
7982/7982 [==============================] - 2s 302us/step - loss: 0.5894 - acc: 0.8478 - val_loss: 1.3408 - val_acc: 0.7270
Epoch 13/20
7982/7982 [==============================] - 2s 249us/step - loss: 0.5571 - acc: 0.8535 - val_loss: 1.3743 - val_acc: 0.7220
Epoch 14/20
7982/7982 [==============================] - 2s 237us/step - loss: 0.5286 - acc: 0.8611 - val_loss: 1.4452 - val_acc: 0.7230
Epoch 15/20
7982/7982 [==============================] - 2s 230us/step - loss: 0.5023 - acc: 0.8643 - val_loss: 1.4747 - val_acc: 0.7240
Epoch 16/20
7982/7982 [==============================] - 2s 230us/step - loss: 0.4828 - acc: 0.8666 - val_loss: 1.5216 - val_acc: 0.7220
Epoch 17/20
7982/7982 [==============================] - 2s 237us/step - loss: 0.4611 - acc: 0.8682 - val_loss: 1.5521 - val_acc: 0.7190
Epoch 18/20
7982/7982 [==============================] - 2s 236us/step - loss: 0.4466 - acc: 0.8696 - val_loss: 1.5910 - val_acc: 0.7130
Epoch 19/20
7982/7982 [==============================] - 2s 240us/step - loss: 0.4302 - acc: 0.8731 - val_loss: 1.6180 - val_acc: 0.7130
Epoch 20/20
7982/7982 [==============================] - 2s 238us/step - loss: 0.4138 - acc: 0.8782 - val_loss: 1.7089 - val_acc: 0.7150
<keras.callbacks.History at 0x2205381ee48>
#现在我们的网络只达到了71%的准确度,绝对下降了8%。这个下降主要是由于我们现在试图压缩大量信息到维度太低的中间层中。网络能够将大部分必要的信息
塞进这些低维表示中,但不是全部。
'''
11.进一步的实验:
- 32维中间层
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=128,
validation_data=(x_val, y_val))
'''
Train on 7982 samples, validate on 1000 samples
Epoch 1/20
7982/7982 [==============================] - 2s 279us/step - loss: 1.9490 - acc: 0.6077 - val_loss: 1.2621 - val_acc: 0.7150
Epoch 2/20
7982/7982 [==============================] - 2s 247us/step - loss: 1.0032 - acc: 0.7839 - val_loss: 1.0204 - val_acc: 0.7870
Epoch 3/20
7982/7982 [==============================] - 2s 239us/step - loss: 0.6965 - acc: 0.8500 - val_loss: 0.9087 - val_acc: 0.8140
Epoch 4/20
7982/7982 [==============================] - 2s 246us/step - loss: 0.4976 - acc: 0.8934 - val_loss: 0.8688 - val_acc: 0.8230
Epoch 5/20
7982/7982 [==============================] - 2s 235us/step - loss: 0.3696 - acc: 0.9194 - val_loss: 0.8703 - val_acc: 0.8330
Epoch 6/20
7982/7982 [==============================] - 2s 243us/step - loss: 0.2872 - acc: 0.9367 - val_loss: 0.8947 - val_acc: 0.8210
Epoch 7/20
7982/7982 [==============================] - 2s 247us/step - loss: 0.2340 - acc: 0.9456 - val_loss: 0.9012 - val_acc: 0.8230
Epoch 8/20
7982/7982 [==============================] - 3s 314us/step - loss: 0.1963 - acc: 0.9514 - val_loss: 0.9432 - val_acc: 0.8170
Epoch 9/20
7982/7982 [==============================] - 2s 246us/step - loss: 0.1750 - acc: 0.9531 - val_loss: 0.9921 - val_acc: 0.8080
Epoch 10/20
7982/7982 [==============================] - 2s 246us/step - loss: 0.1577 - acc: 0.9526 - val_loss: 1.0008 - val_acc: 0.8130
Epoch 11/20
7982/7982 [==============================] - 2s 243us/step - loss: 0.1487 - acc: 0.9562 - val_loss: 1.0730 - val_acc: 0.8000
Epoch 12/20
7982/7982 [==============================] - 2s 258us/step - loss: 0.1400 - acc: 0.9553 - val_loss: 1.0220 - val_acc: 0.8090
Epoch 13/20
7982/7982 [==============================] - 2s 248us/step - loss: 0.1397 - acc: 0.9536 - val_loss: 1.0877 - val_acc: 0.8080
Epoch 14/20
7982/7982 [==============================] - 2s 275us/step - loss: 0.1289 - acc: 0.9582 - val_loss: 1.1081 - val_acc: 0.8080
Epoch 15/20
7982/7982 [==============================] - 2s 239us/step - loss: 0.1231 - acc: 0.9570 - val_loss: 1.1342 - val_acc: 0.8070
Epoch 16/20
7982/7982 [==============================] - 2s 239us/step - loss: 0.1228 - acc: 0.9558 - val_loss: 1.2031 - val_acc: 0.7910
Epoch 17/20
7982/7982 [==============================] - 2s 241us/step - loss: 0.1214 - acc: 0.9559 - val_loss: 1.2118 - val_acc: 0.7990
Epoch 18/20
7982/7982 [==============================] - 2s 238us/step - loss: 0.1123 - acc: 0.9584 - val_loss: 1.1572 - val_acc: 0.8060
Epoch 19/20
7982/7982 [==============================] - 2s 235us/step - loss: 0.1150 - acc: 0.9573 - val_loss: 1.2337 - val_acc: 0.7870
Epoch 20/20
7982/7982 [==============================] - 2s 235us/step - loss: 0.1131 - acc: 0.9573 - val_loss: 1.2595 - val_acc: 0.7960
<keras.callbacks.History at 0x22051e5d358>
'''
- 128维中间层
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=128,
validation_data=(x_val, y_val))
'''
Train on 7982 samples, validate on 1000 samples
Epoch 1/20
7982/7982 [==============================] - 2s 292us/step - loss: 1.7568 - acc: 0.6374 - val_loss: 1.2359 - val_acc: 0.7120
Epoch 2/20
7982/7982 [==============================] - 3s 335us/step - loss: 0.9146 - acc: 0.7987 - val_loss: 0.9709 - val_acc: 0.8040
Epoch 3/20
7982/7982 [==============================] - 2s 243us/step - loss: 0.5959 - acc: 0.8726 - val_loss: 0.8788 - val_acc: 0.8200
Epoch 4/20
7982/7982 [==============================] - 2s 216us/step - loss: 0.4066 - acc: 0.9129 - val_loss: 0.8853 - val_acc: 0.8070
Epoch 5/20
7982/7982 [==============================] - 2s 229us/step - loss: 0.2910 - acc: 0.9366 - val_loss: 0.9215 - val_acc: 0.8180
Epoch 6/20
7982/7982 [==============================] - 2s 223us/step - loss: 0.2332 - acc: 0.9445 - val_loss: 0.9758 - val_acc: 0.8090
Epoch 7/20
7982/7982 [==============================] - 2s 214us/step - loss: 0.1953 - acc: 0.9494 - val_loss: 0.9520 - val_acc: 0.8190
Epoch 8/20
7982/7982 [==============================] - 2s 224us/step - loss: 0.1693 - acc: 0.9518 - val_loss: 0.9733 - val_acc: 0.8110
Epoch 9/20
7982/7982 [==============================] - 2s 233us/step - loss: 0.1521 - acc: 0.9554 - val_loss: 0.9764 - val_acc: 0.8000
Epoch 10/20
7982/7982 [==============================] - 2s 240us/step - loss: 0.1441 - acc: 0.9549 - val_loss: 1.0458 - val_acc: 0.7960
Epoch 11/20
7982/7982 [==============================] - 2s 243us/step - loss: 0.1349 - acc: 0.9557 - val_loss: 1.0131 - val_acc: 0.8120
Epoch 12/20
7982/7982 [==============================] - 2s 290us/step - loss: 0.1280 - acc: 0.9560 - val_loss: 1.0672 - val_acc: 0.8020
Epoch 13/20
7982/7982 [==============================] - 2s 220us/step - loss: 0.1199 - acc: 0.9574 - val_loss: 1.0996 - val_acc: 0.7890
Epoch 14/20
7982/7982 [==============================] - 2s 224us/step - loss: 0.1190 - acc: 0.9555 - val_loss: 1.1101 - val_acc: 0.8030
Epoch 15/20
7982/7982 [==============================] - 2s 229us/step - loss: 0.1115 - acc: 0.9565 - val_loss: 1.1388 - val_acc: 0.7970
Epoch 16/20
7982/7982 [==============================] - 2s 236us/step - loss: 0.1094 - acc: 0.9553 - val_loss: 1.1762 - val_acc: 0.7990
Epoch 17/20
7982/7982 [==============================] - 2s 230us/step - loss: 0.1053 - acc: 0.9562 - val_loss: 1.2746 - val_acc: 0.7810
Epoch 18/20
7982/7982 [==============================] - 2s 225us/step - loss: 0.1005 - acc: 0.9558 - val_loss: 1.2091 - val_acc: 0.8020
Epoch 19/20
7982/7982 [==============================] - 2s 230us/step - loss: 0.0973 - acc: 0.9587 - val_loss: 1.2041 - val_acc: 0.7910
Epoch 20/20
7982/7982 [==============================] - 2s 228us/step - loss: 0.0933 - acc: 0.9564 - val_loss: 1.2951 - val_acc: 0.7840
<keras.callbacks.History at 0x22053cec588>
'''
- 1024维中间层
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(1024, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=128,
validation_data=(x_val, y_val))
'''
Train on 7982 samples, validate on 1000 samples
Epoch 1/20
7982/7982 [==============================] - 3s 319us/step - loss: 1.5945 - acc: 0.6374 - val_loss: 1.1893 - val_acc: 0.7210
Epoch 2/20
7982/7982 [==============================] - 2s 269us/step - loss: 0.8817 - acc: 0.7954 - val_loss: 1.0023 - val_acc: 0.7620
Epoch 3/20
7982/7982 [==============================] - 2s 270us/step - loss: 0.5688 - acc: 0.8617 - val_loss: 0.9446 - val_acc: 0.8020
Epoch 4/20
7982/7982 [==============================] - 2s 239us/step - loss: 0.3759 - acc: 0.9084 - val_loss: 0.9414 - val_acc: 0.8100
Epoch 5/20
7982/7982 [==============================] - 3s 336us/step - loss: 0.2629 - acc: 0.9347 - val_loss: 1.0359 - val_acc: 0.8010
Epoch 6/20
7982/7982 [==============================] - 2s 288us/step - loss: 0.2051 - acc: 0.9483 - val_loss: 1.0159 - val_acc: 0.8100
Epoch 7/20
7982/7982 [==============================] - 2s 256us/step - loss: 0.1732 - acc: 0.9524 - val_loss: 1.0248 - val_acc: 0.8020
Epoch 8/20
7982/7982 [==============================] - 2s 229us/step - loss: 0.1523 - acc: 0.9546 - val_loss: 1.0986 - val_acc: 0.8010
Epoch 9/20
7982/7982 [==============================] - 2s 224us/step - loss: 0.1374 - acc: 0.9549 - val_loss: 1.0798 - val_acc: 0.7990
Epoch 10/20
7982/7982 [==============================] - 2s 227us/step - loss: 0.1310 - acc: 0.9551 - val_loss: 1.1086 - val_acc: 0.8090
Epoch 11/20
7982/7982 [==============================] - 2s 232us/step - loss: 0.1196 - acc: 0.9544 - val_loss: 1.1469 - val_acc: 0.7990
Epoch 12/20
7982/7982 [==============================] - 2s 228us/step - loss: 0.1120 - acc: 0.9558 - val_loss: 1.2700 - val_acc: 0.7870
Epoch 13/20
7982/7982 [==============================] - 2s 260us/step - loss: 0.1059 - acc: 0.9582 - val_loss: 1.2970 - val_acc: 0.7920
Epoch 14/20
7982/7982 [==============================] - 2s 282us/step - loss: 0.1008 - acc: 0.9564 - val_loss: 1.3453 - val_acc: 0.7930
Epoch 15/20
7982/7982 [==============================] - 2s 228us/step - loss: 0.0920 - acc: 0.9568 - val_loss: 1.3905 - val_acc: 0.7890
Epoch 16/20
7982/7982 [==============================] - 2s 286us/step - loss: 0.0885 - acc: 0.9587 - val_loss: 1.4205 - val_acc: 0.8060
Epoch 17/20
7982/7982 [==============================] - 2s 227us/step - loss: 0.0863 - acc: 0.9574 - val_loss: 1.5548 - val_acc: 0.7970
Epoch 18/20
7982/7982 [==============================] - 2s 222us/step - loss: 0.0817 - acc: 0.9584 - val_loss: 1.5518 - val_acc: 0.7980
Epoch 19/20
7982/7982 [==============================] - 2s 275us/step - loss: 0.0792 - acc: 0.9587 - val_loss: 1.5787 - val_acc: 0.7900
Epoch 20/20
7982/7982 [==============================] - 2s 229us/step - loss: 0.0774 - acc: 0.9603 - val_loss: 1.7190 - val_acc: 0.7890
<keras.callbacks.History at 0x22016da5ac8>
'''
- 三个中间层
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=128,
validation_data=(x_val, y_val))
'''
Train on 7982 samples, validate on 1000 samples
Epoch 1/20
7982/7982 [==============================] - 2s 313us/step - loss: 1.7158 - acc: 0.6262 - val_loss: 1.2002 - val_acc: 0.7260
Epoch 2/20
7982/7982 [==============================] - 2s 249us/step - loss: 0.9211 - acc: 0.7909 - val_loss: 0.9639 - val_acc: 0.7930
Epoch 3/20
7982/7982 [==============================] - 2s 265us/step - loss: 0.6014 - acc: 0.8618 - val_loss: 0.8961 - val_acc: 0.8050
Epoch 4/20
7982/7982 [==============================] - 2s 254us/step - loss: 0.4071 - acc: 0.9084 - val_loss: 0.9229 - val_acc: 0.8060
Epoch 5/20
7982/7982 [==============================] - 2s 242us/step - loss: 0.2887 - acc: 0.9332 - val_loss: 1.1620 - val_acc: 0.7560
Epoch 6/20
7982/7982 [==============================] - 2s 265us/step - loss: 0.2263 - acc: 0.9448 - val_loss: 1.0262 - val_acc: 0.8010
Epoch 7/20
7982/7982 [==============================] - 2s 267us/step - loss: 0.1977 - acc: 0.9495 - val_loss: 0.9751 - val_acc: 0.8080
Epoch 8/20
7982/7982 [==============================] - 2s 305us/step - loss: 0.1705 - acc: 0.9515 - val_loss: 1.0764 - val_acc: 0.8060
Epoch 9/20
7982/7982 [==============================] - 2s 235us/step - loss: 0.1505 - acc: 0.9545 - val_loss: 1.0835 - val_acc: 0.8140
Epoch 10/20
7982/7982 [==============================] - 2s 252us/step - loss: 0.1409 - acc: 0.9569 - val_loss: 1.1360 - val_acc: 0.8050
Epoch 11/20
7982/7982 [==============================] - 2s 227us/step - loss: 0.1336 - acc: 0.9539 - val_loss: 1.2339 - val_acc: 0.7940
Epoch 12/20
7982/7982 [==============================] - 2s 255us/step - loss: 0.1213 - acc: 0.9567 - val_loss: 1.2267 - val_acc: 0.7930
Epoch 13/20
7982/7982 [==============================] - 2s 238us/step - loss: 0.1187 - acc: 0.9568 - val_loss: 1.2552 - val_acc: 0.7750
Epoch 14/20
7982/7982 [==============================] - 2s 229us/step - loss: 0.1087 - acc: 0.9565 - val_loss: 1.2623 - val_acc: 0.7830
Epoch 15/20
7982/7982 [==============================] - 2s 233us/step - loss: 0.1057 - acc: 0.9564 - val_loss: 1.2429 - val_acc: 0.7910
Epoch 16/20
7982/7982 [==============================] - 2s 227us/step - loss: 0.1013 - acc: 0.9584 - val_loss: 1.2710 - val_acc: 0.8020
Epoch 17/20
7982/7982 [==============================] - 2s 226us/step - loss: 0.0975 - acc: 0.9550 - val_loss: 1.3431 - val_acc: 0.8010
Epoch 18/20
7982/7982 [==============================] - 2s 241us/step - loss: 0.0944 - acc: 0.9569 - val_loss: 1.3768 - val_acc: 0.7880
Epoch 19/20
7982/7982 [==============================] - 2s 244us/step - loss: 0.0902 - acc: 0.9592 - val_loss: 1.4834 - val_acc: 0.7890
Epoch 20/20
7982/7982 [==============================] - 2s 257us/step - loss: 0.0871 - acc: 0.9582 - val_loss: 1.4948 - val_acc: 0.7890
<keras.callbacks.History at 0x220187cc9b0>
'''
结论:中间层层数和维数足够大即可,太小会降低精确度。
小结
- 如果分类类别数量为N,那么网络输出全连接层的维数为N
- 在“单标签多类分类”问题中,网络应以softmax激活结束,输出N个类别的概率分布。
- 这种问题的损失函数crossentropy(交叉熵)。它将网络输出的概率分布与目标的真实分布之间的距离最小化。
- 有两种方法可以处理多分类中的矢量量化问题
1.对类别进行编码(常用“独热编码”)并将categorical_crossentropy用作损失函数
2.将标签编码为整数向量并使用sparse_categorical_crossentropy作为损失函数 - 如果您需要将数据分类到大量类别中,应该保证中间层维数足够大。
