为了使前馈神经网络更加具体,通过解决一个简单的任务:学习XOR函数来加深理解。
XOR函数(异或)是两个二进制值x1和x2的运算。当x1和x2中恰有一个为1时,函数返回1,否则返回0。我们想要学习的目标函数y=f*(x),模型给出了一个函数y=f(x;θ),学习算法通过不断调整参数θ来使得f尽可能接近f*。
在该示例中,我们不关心模型的泛化能力。给定4个训练数据点X={[0,0]T,[0,1]T,[1,0]T,[1,1]T},我们希望模型能在数据集上正确拟合。
我们可以把这个问题当作时回归问题,并使用均方误差损失函数,这里使用该损失只是为了简化数学问题,在二进制数据建模中,MSE通常并不是一个合适的损失函数。那么,在整个训练数据集上,MSE损失函数为:
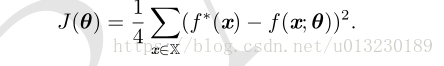
然后,选择模型f(x;θ)的表现形式,假设选择一个线性模型,θ包含w和b,那么模型定义如下:
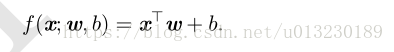
通过最小化损失函数J(θ),得到w=0,b=1/2。由此可知,该线性模型在任意一点都输出0.5。为什么会这样呢?见下图:

通过上述可知,线性模型无法表示XOR函数,我们需要使用一个模型来学习一个不同的特征空间,在这个特征空间上线性模型能够表示这个解。具体来说,我们引入一个简单的前馈神经网络,该网络包含一个隐藏层,隐藏层包含两个神经元(见下图)。
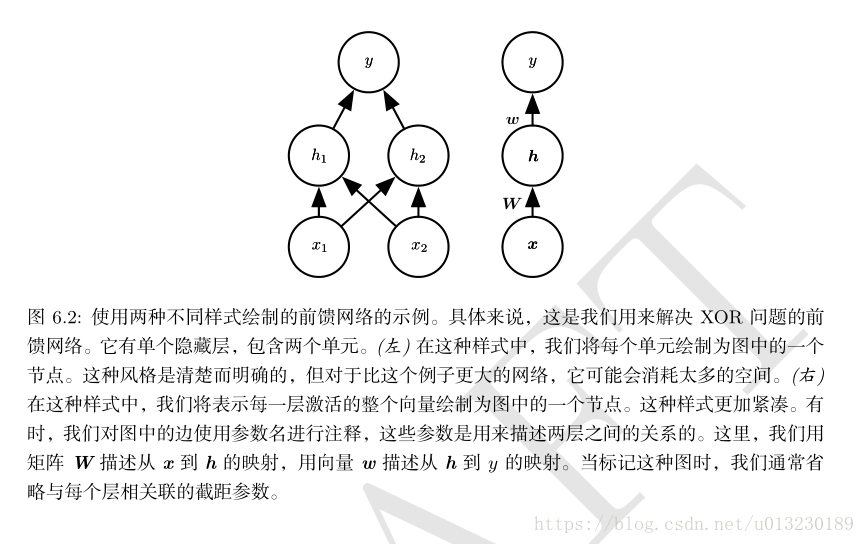
该前馈神经网络通过函数f(1)(x;W,c)计算得到隐藏层神经元的向量h,向量h随后被用作第二层的输入。第二层及该网络的输出层。输出层也是一个线性回归函数,只不过它现在作用于h而不是x。现在,网络包含两个函数:f(1)(x;W,c)和y=f(2)(h;w,b),统一表示即:f(x;W,c,w,b)=f(2)(f(1)(x))。
那么f(1)是那种函数呢?线性函数吗?如果f(1)是线性的,那么前馈网络作为一个整体对于输出仍然是线性的。假设f(1)(x)=WTx并且f(2)(h)=hTw,那么f(x)=wTWTx。令w’=Ww,则f(x)=xTw’。
显然,我们不能用线性函数而要使用非线性函数来描述这些特征。大多神经网络通过仿射变换之后紧接着一个激活函数来实现,其中仿射变换由学习到的参数控制。定义h=g(WTx+c),W是线性变换的权重,c是偏置。此前,为了描述线性回归模型,我们使用权重向量和一个标量的偏置参数来描述从输入向量到输出标量的仿射变换。现在,因为我们描述的是向量 x 到向量 h 的仿射变换,所以我们需要一整个向量的偏置参数。激活函数g 通常选择对每个元素分别起作用的函数,有hi=g(xTW;,i+ci)。
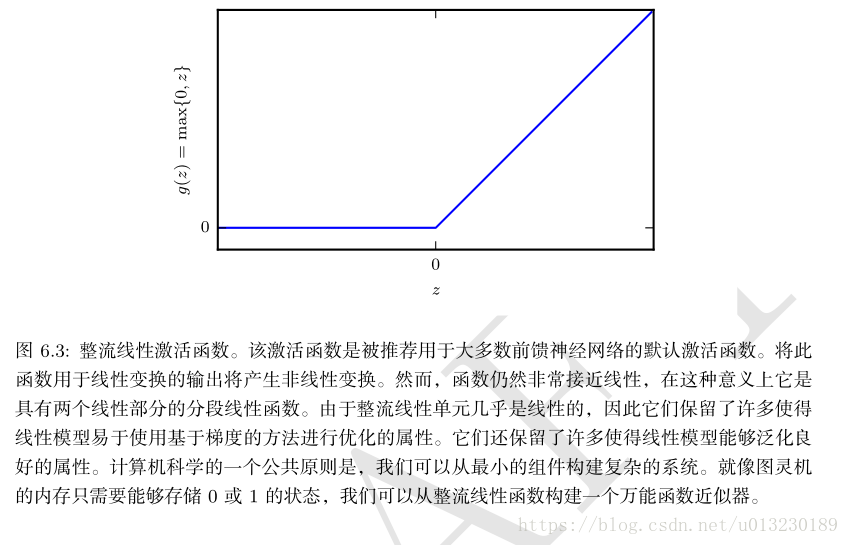
默认的激活函数是g(z)=max{0,z},称为整流线性单元(rectified linear unit)或者ReLU(见下图)。
现在,我们整个网络可以表示为:
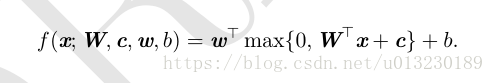
给出XOR问题的一个解,令:
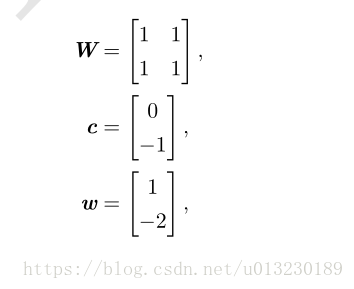
以及b=0。现在可以知道该模型如何处理一批输入了。令X表示训练数据,
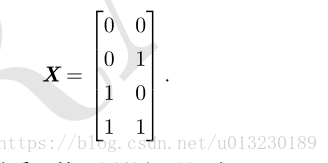
神经网络的第一层是将输入矩阵乘以第一层的权重矩阵:
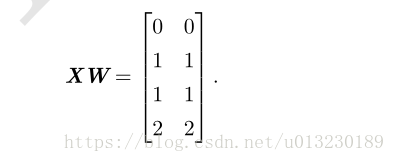
再加上偏置向量c,得到:
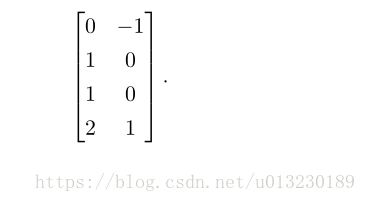
在这个空间中,所有的样本都处在一条斜率为 1 的直线上。当我们沿着这条直线移
动时,输出需要从 0 升到 1,然后再降回 0。线性模型不能实现这样一种函数。为了
用 h 对每个样本求值,我们使用整流线性变换
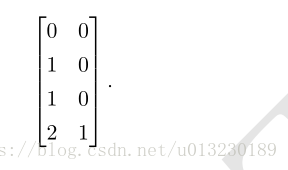
这个变换改变了样本间的关系,他们不再处于同一条直线上了。他们现在处于一个可以用线性模型解决的空间上。
最后乘以一个权重向量w:
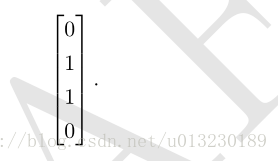
神经网络对训练数据都给出了正确的结果。
实际情况中,可能会有数十亿的模型参数和样本,通常使用基于梯度的优化算法来求解。