介绍
FastText是Facebook于2016年开源的一个词向量计算和文本分类工具,在学术上并没有太大创新。但是它的优点也非常明显,在文本分类任务中,fastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。在标准的多核CPU上, 能够训练10亿词级别语料库的词向量在10分钟之内,能够分类有着30万多类别的50多万句子在1分钟之内。
Fasttext主要有两个功能,一个是训练词向量,另一个是文本分类。词向量的训练,相对于word2vec来说,增加了subwords特性。
fastText的核心思想是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。这中间涉及到两个技巧:字符级n-gram特征的引入以及分层Softmax分类。
字符级别的n-gram
大多数现有的方法用一个唯一的向量表示,且参数不共享,忽略了词语内部的结构,这对那些多种形态的语言有很大限制。
word2vec把语料库中的每个单词当成原子的,它会为每个单词生成一个向量。这忽略了单词内部的形态特征,比如:“apple” 和“apples”,两个单词都有较多公共字符,即它们的内部形态类似,但是在传统的word2vec中,这种单词内部形态信息因为它们被转换成不同的id丢失了。
为了克服这个问题,fastText使用了字符级别的n-grams来表示一个单词。对于单词“apple”,假设n的取值为3,则它的trigram有
“
ap”, “app”, “ppl”, “ple”, “le
”
其中,<表示前缀,>表示后缀。于是,我们可以用这些trigram来表示“apple”这个单词,进一步,我们可以用这5个trigram的向量叠加来表示“apple”的词向量。
这带来两点好处:
对于低频词生成的词向量效果会更好。因为它们的n-gram可以和其它词共享。
对于训练词库之外的单词,仍然可以构建它们的词向量。我们可以叠加它们的字符级n-gram向量。
模型架构
之前提到过,fastText模型架构和word2vec的CBOW模型架构非常相似。下面是fastText模型架构图:
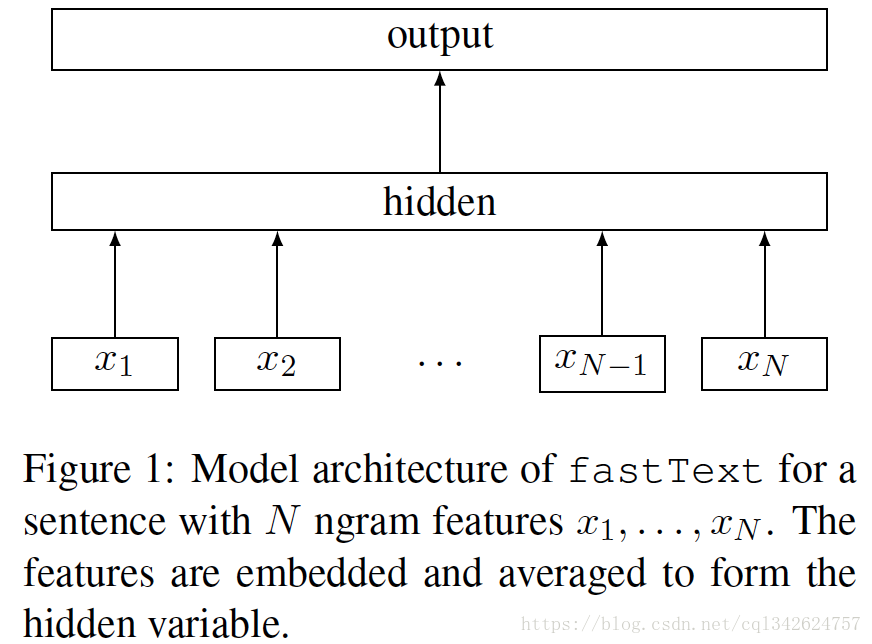
注意:此架构图没有展示词向量的训练过程。可以看到,和CBOW一样,fastText模型也只有三层:输入层、隐含层、输出层(Hierarchical Softmax),输入都是多个经向量表示的单词,输出都是一个特定的target,隐含层都是对多个词向量的叠加平均。
不同的是:
CBOW的输入是目标单词的上下文,fastText的输入是多个单词及其n-gram特征,这些特征用来表示单个文档;
CBOW的输入单词被onehot编码过,fastText的输入特征是被embedding过;CBOW的输出是目标词汇,fastText的输出是文档对应的类标。
值得注意的是,fastText在输入时,将单词的字符级别的n-gram向量作为额外的特征;在输出时,fastText采用了分层Softmax,大大降低了模型训练时间。
分层softmax分类
当类别数量很大时,线性分类器在计算上很耗时,复杂度为 。为了优化运行速度,模型使用了基于哈夫曼树的层次sofamax, 计算复杂度降低到 .
它的基本思想是使用树的层级结构替代扁平化的标准Softmax,使得在计算 P(y=j) 时,只需计算一条路径上的所有节点的概率值,无需在意其它的节点。
层次softmax 在搜索最可能类别的时候非常快。每个节点的概率是从根节点到那个节点的概率。使用深度优先查找并在叶子节点中跟踪最大概率允许我们抛弃一些概率低的分支。
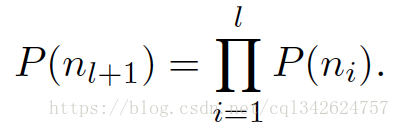
例子
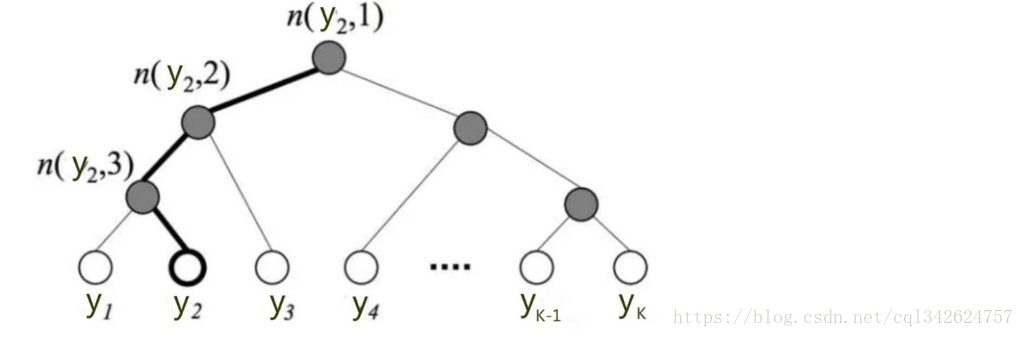
树的结构是根据类标的频数构造的霍夫曼树。K个不同的类标组成所有的叶子节点,K-1个内部节点作为内部参数,从根节点到某个叶子节点经过的节点和边形成一条路径,路径长度被表示为
。于是,
就可以被写成:
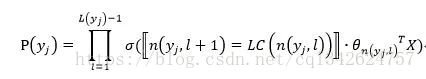
高亮的节点和边是从根节点到
, 可以表示为:
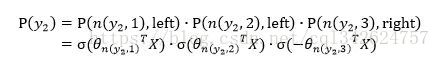
实际上是在做了3次二分类的逻辑回归。
Hashing Tricks
由于n-gram的量远比word大的多,完全存下所有的n-gram也不现实。Fasttext采用了Hash桶的方式,把所有的n-gram都哈希到buckets个桶中,哈希到同一个桶的所有n-gram共享一个embedding vector
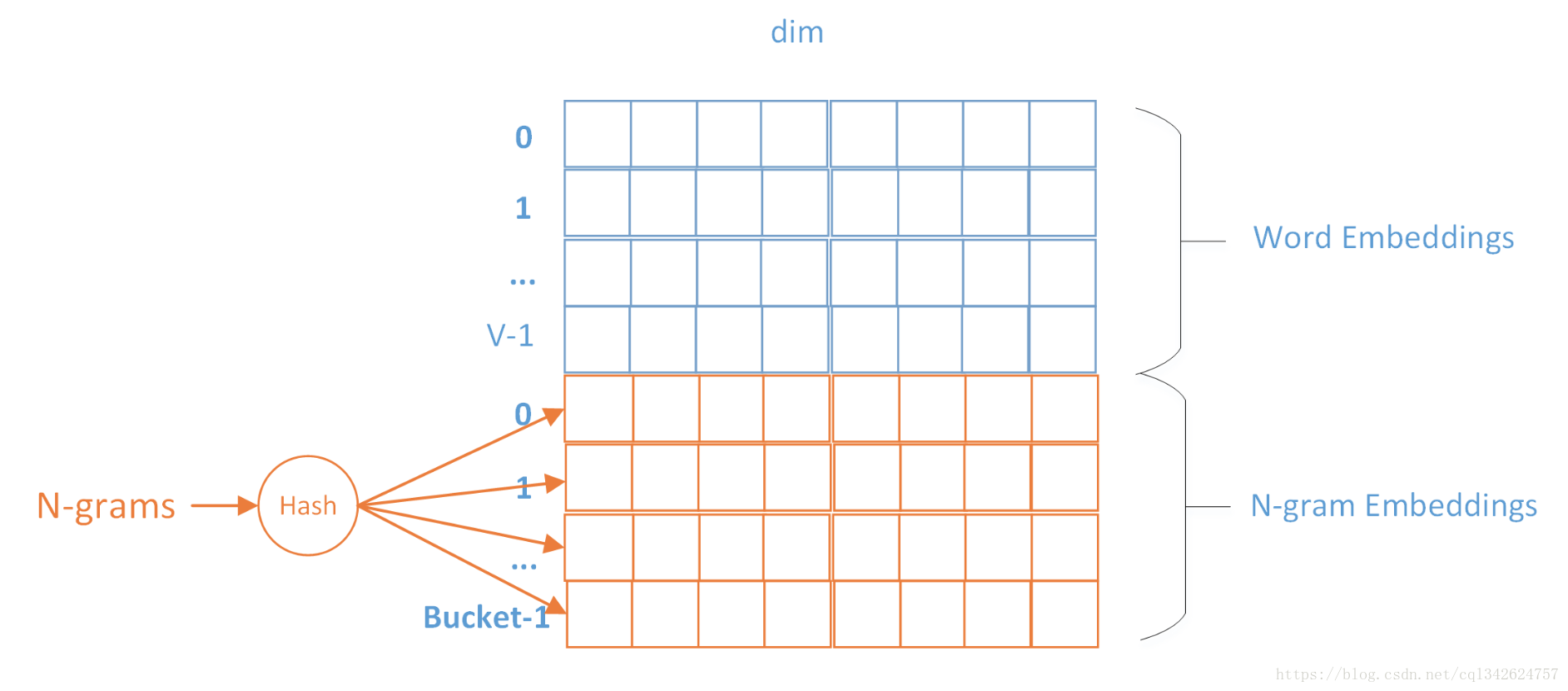
图中是Embedding矩阵,每行代表一个word或N-gram的embeddings向量,其中前V行是word embeddings,后Buckets行是n-grams embeddings。每个n-gram经哈希函数哈希到0-bucket-1的位置,得到对应的embedding向量。用哈希的方式既能保证查找时O(1)的效率,又可能把内存消耗控制在O(bucket×dim)范围内。不过这种方法潜在的问题是存在哈希冲突,不同的n-gram可能会共享同一个embedding。如果桶大小取的足够大,这种影响会很小。
结论和思考
工业界的角度来看,Fasttext因为其优秀的性能,不错的分类效果,使用起来也非常简单,因此非常适合大规模的文本分类问题。
理论或者学术的角度看,首先,对于文本分类等偏线性的数据集,复杂的深层网络对于浅层网络来说,优势并不明显,深度学习可能容易过拟合,而浅层的简单网络反而泛化能力更好。其次,除了数据本身,数据量的大小很大程度上也决定了方法的选择。对于小规模的数据集,可能简单的浅层模型就可以了,深度学习因为参数很多,模型复杂,反而训练不充分。
参考
Joulin A, Grave E, Bojanowski P, et al. Bag of tricks for efficient text classification[J]. arXiv preprint arXiv:1607.01759, 2016.
Bojanowski P, Grave E, Joulin A, et al. Enriching word vectors with subword information[J]. arXiv preprint arXiv:1607.04606, 2016.
