背景
fastText是Facebook2016年提出的文本分类工具,是一种高效的浅层网络。
1 基本知识
1.1 softmax回归
有m个样本
,
.假设,
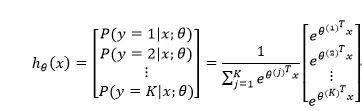
1.2 分层Softmax
y很多是,归一化很耗时,分层Softmax用树的层级结构来代替扁平化的标准Softmax,计算
时,只需计算一条路径上所有节点的概率值。
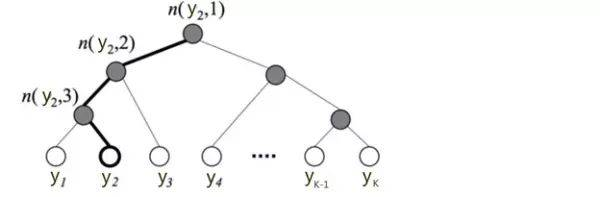
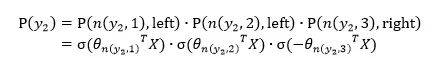
关于分层Softmax,可以看刘建平的博客.
1.3 n-gram特征
将文本内容按照字节顺序进行大小为N的滑动窗操作。
eg.
The weather is nice today.
2-gram:
The weather, weather is,…
当然,除了字粒度n-gram,还有词粒度的n-gram。
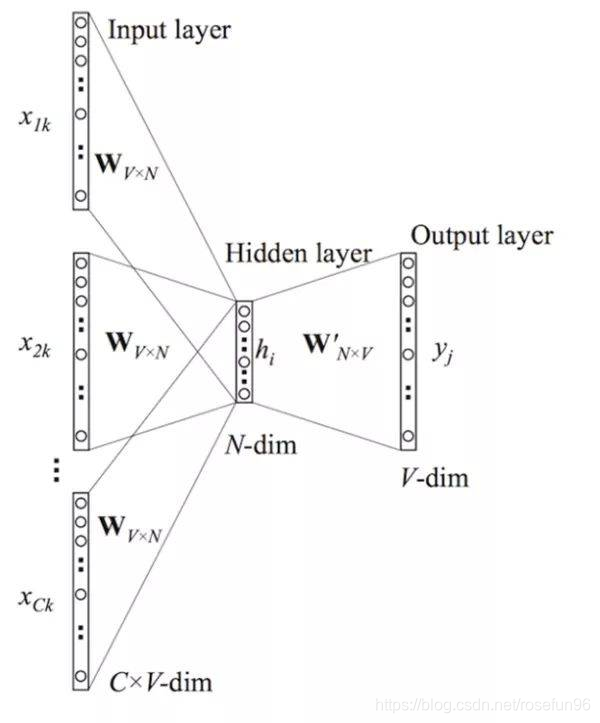
1.4 Word2Vec
CBOW模型是,利用上下文预测目标词汇。
2 fastText模型
fastText模型生成词的Embedding。
2.1 字符的n-gram
2.2 模型结构
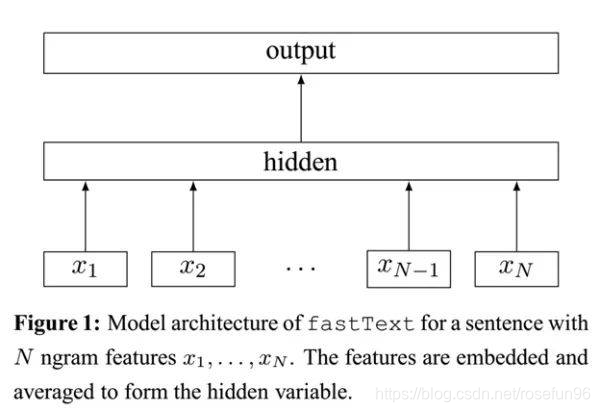
fastText架构和Word2Vec的CBOW模型相似,fastText模型只有3层:输入层,隐含层,输出层(Hierarchical Softmax),输入都是多个经向量表示的单词,输出都是一个特定的target,隐含层都是多个词向量的叠加平均。
不同的是,CBOW的输入是目标单词的上下文,fastText的输入是多个单词及其n-gram特征,这些特征用来表示单个文档;CBOW的输入单词被onehot编码过,fastText的输入特征是被embedding过;CBOW的输出是目标词汇,fastText的输出是文档对应的类标。
fastText的核心思想就是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。这中间涉及到两个技巧:字符级n-gram特征的引入以及分层Softmax分类。
模型前半部分,叠加构成文档的所有词及n-gram的词向量,取平均,生成用来表征文档的词向量。
模型的后半部分,用Softmax分类器来输出每个词向量的类别。
3 总结
fastText效果好的原因:使用词Embedding和字符级n-gram,使得,轻量级的网络取得较好的结果。
reference:
1.机器之心文章;
2.原论文;
3.fasttext code;
4.刘建平的博客;