1、概述
FastText 文本分类算法是有Facebook AI Research 提出的一种简单的模型。实验表明一般情况下,FastText 算法能获得和深度模型相同的精度,但是计算时间却要远远小于深度学习模型。fastText 可以作为一个文本分类的 baseline 模型。
2、模型架构
fastText 的模型架构和 word2vec 中的 CBOW 模型的结构很相似。CBOW 模型是利用上下文来预测中间词,而fastText 是利用上下文来预测文本的类别。而且从本质上来说,word2vec是属于无监督学习,fastText 是有监督学习。但两者都是三层的网络(输入层、单层隐藏层、输出层),具体的模型结构如下:
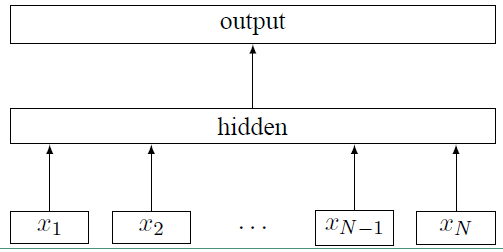
上面图中 $x_i$ 表示的是文本中第 $i$ 个词的特征向量,该模型的负对数似然函数如下:

上面式子中的矩阵 A 是词查找表,整个模型是查找出所有的词表示之后取平均值,用该平均值来代表文本表示,然后将这个文本表示输入到线性分类器中,也就是输出层的 softmax 函数。式子中的 B 是函数 $ f $ 的权重系数。
3、分层 softmax(Hierarchical softmax)
首先来看看softmax 函数的表达式如下:
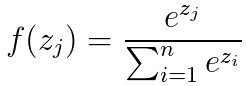
然而在类别非常多的时候,利用softmax 计算的代价是非常大的,时间复杂度为 $O(kh)$ ,其中 $k$ 是类别的数量,$h$ 是文本表示的维度。而基于霍夫曼树否建的层次 softmax 的时间复杂度为 $O(h;log_2(k))$ (二叉树的时间复杂度是 $O(log_2(k))$ )。霍夫曼树是从根节点开始寻找,而且在霍夫曼树中权重越大的节点越靠近根节点,这也进一步加快了搜索的速度。
4、N-grams 特征
传统的词袋模型不能保存上下文的语义,例如“我爱你”和“你爱我”在传统的词袋模型中表达的意思是一样的,N-grams 模型能很好的保存上下文的语义,能将上面两个短语给区分开。而且在这里使用了 hash trick 进行特征向量降维。hash trick 的降维思想是讲原始特征空间通过 hash 函数映射到低维空间。