以下链接是个人关于Liquid Warping GAN(Impersonator)-姿态迁移,所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:a944284742相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。
风格迁移1-00:Liquid Warping GAN(Impersonator)-目录-史上最新无死角讲解
前言
我们对train.py的代码,从main函数开始追踪,可以追踪到 def _train_epoch(self, i_epoch)函数,可以看到如下:
# train model,设置模型输入的
self._model.set_input(train_batch)
trainable = ((i_train_batch+1) % self._opt.train_G_every_n_iterations == 0) or do_visuals
# 对参数进行进行优化,也就是反向传播,do_visuals表示指定该次是否进行可视化
self._model.optimize_parameters(keep_data_for_visuals=do_visuals, trainable=trainable)
上面的代码,都是比较核心的,其中self._model实现在models/impersonator_trainer.py中,我们先来看看其中的def set_input(self, input)函数,如下:
def set_input(self, input):
with torch.no_grad():
images = input['images']
smpls = input['smpls']
src_img = images[:, 0, ...].cuda()
src_smpl = smpls[:, 0, ...].cuda()
tsf_img = images[:, 1, ...].cuda()
tsf_smpl = smpls[:, 1, ...].cuda()
# input_G_src_bg为论文中的Ibg,
# input_G_src为论文中的Ift
# input_G_tsf为论文中的Isyn
# src_crop_mask为source图像的掩码,即人体部分像素为0,其余为1
# tsf_crop_mask为reference图像的掩码,即人体部分像素为0,其余为1
# T 和论文的T对应
# head_bbox = 头部的bbox坐标
# body_bbox = 身体的bbox坐标
input_G_src_bg, input_G_tsf_bg, input_G_src, input_G_tsf, T, src_crop_mask, \
tsf_crop_mask, head_bbox, body_bbox = self._bdr(src_img, tsf_img, src_smpl, tsf_smpl)
# 把输入两个姿态的图片像素进行赋值
self._real_src = src_img
self._real_tsf = tsf_img
# 把两个mask掩码连接起来
self._bg_mask = torch.cat((src_crop_mask, tsf_crop_mask), dim=0)
# 根据bg_both参数确定是否把两张输入图像的背景图连接起来
# _input_G_bg为论文中的Ibg
if self._opt.bg_both:
self._input_G_bg = torch.cat([input_G_src_bg, input_G_tsf_bg], dim=0)
# 如果没有连接起来,这输入_input_G_bg赋值为source的背景图
else:
self._input_G_bg = input_G_src_bg
self._input_G_src = input_G_src # 论文中的Ift
self._input_G_tsf = input_G_tsf # 论文中的Isyn
self._T = T # 论文中的T
self._head_bbox = head_bbox # 头部的坐标
self._body_bbox = body_bbox # 身体的坐标
这个过程主要对应论文中的如下图示绿色框出部分:
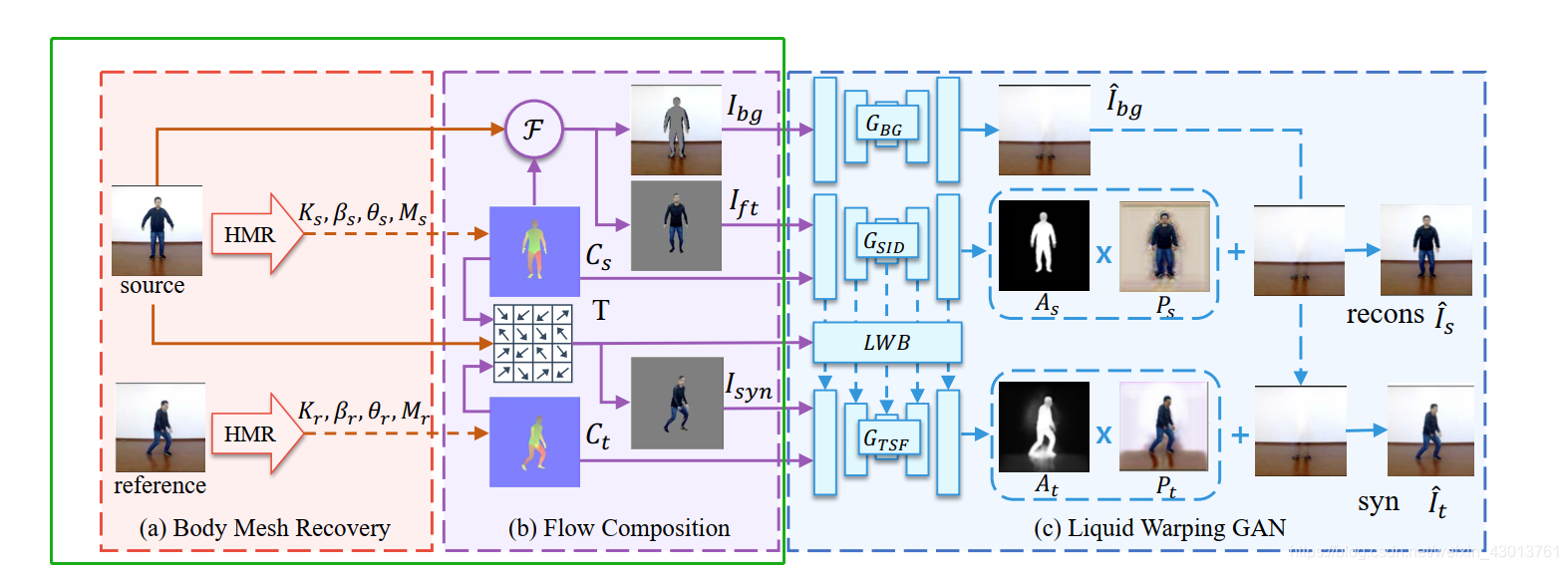
大家肯定注意到了其中的HMR网络,这网络,在源码中是又实现的,主要是获得输入照片的
参数,根据这些参数,我们就能得到图像对应的 M(3D body model),然后根据 T 转换之后,再进行渲染,又兴趣的朋友可以去看看这个网络,这里就不做详细的介绍了,还有要注意的一点是,再训练的时候,我们使用的是数据集总的smpls文件总的
参数,再测试的时候,我们才使用HMR网络计算出来的参数,我估计smpls文件总的参数,或许也是通过HMR网络估算出来的。得到下部分的网络之后,就到了核心部分了,我们来看看impersonator_trainer.py中class Impersonator(BaseModel)的前向传播。
主干网络前向传播
def forward(self, keep_data_for_visuals=False, return_estimates=False):
# generate fake images
# 输入: _input_G_bg 论文中的Ibg, _input_G_src 论文中的Ift, _input_G_tsf论文中的
# 输出:fake_bg = ~Ibg, fake_src_color = Ps, fake_src_mask = As
# fake_tsf_color = Pt, fake_tsf_mask = At
fake_bg, fake_src_color, fake_src_mask, fake_tsf_color, fake_tsf_mask = \
self._G.forward(self._input_G_bg, self._input_G_src, self._input_G_tsf, T=self._T)
# 获得batch_size
bs = fake_src_color.shape[0]
# 主要是看bg_both参数是否设置,如果被设置fake_bg形状为[2b,3,255,255]
fake_src_bg = fake_bg[0:bs]
if self._opt.bg_both:
fake_tsf_bg = fake_bg[bs:]
fake_src_imgs = fake_src_mask * fake_src_bg + (1 - fake_src_mask) * fake_src_color
fake_tsf_imgs = fake_tsf_mask * fake_tsf_bg + (1 - fake_tsf_mask) * fake_tsf_color
# 默认是没有被设置的,即fake_bg为[b,3,255,255],执行如下代码
else:
# ~Is = As * ~Ibg + (1 - As) * Ps
fake_src_imgs = fake_src_mask * fake_src_bg + (1 - fake_src_mask) * fake_src_color
# ~It = At * ~Ibg + (1 - At) * Pt
fake_tsf_imgs = fake_tsf_mask * fake_src_bg + (1 - fake_tsf_mask) * fake_tsf_color
# 把 As 与 At 连接起来
fake_masks = torch.cat([fake_src_mask, fake_tsf_mask], dim=0)
# keep data for visualization
# 让fake_bg, fake_src_imgs, fake_tsf_imgs, fake_masks进行可视化
if keep_data_for_visuals:
self.visual_imgs(fake_bg, fake_src_imgs, fake_tsf_imgs, fake_masks)
# 返回~Ibg, ~Is, ~It, As以及At 计算loss
return fake_bg, fake_src_imgs, fake_tsf_imgs, fake_masks
可以看到完全和论文对应了起来,也就是如下绿框部分:
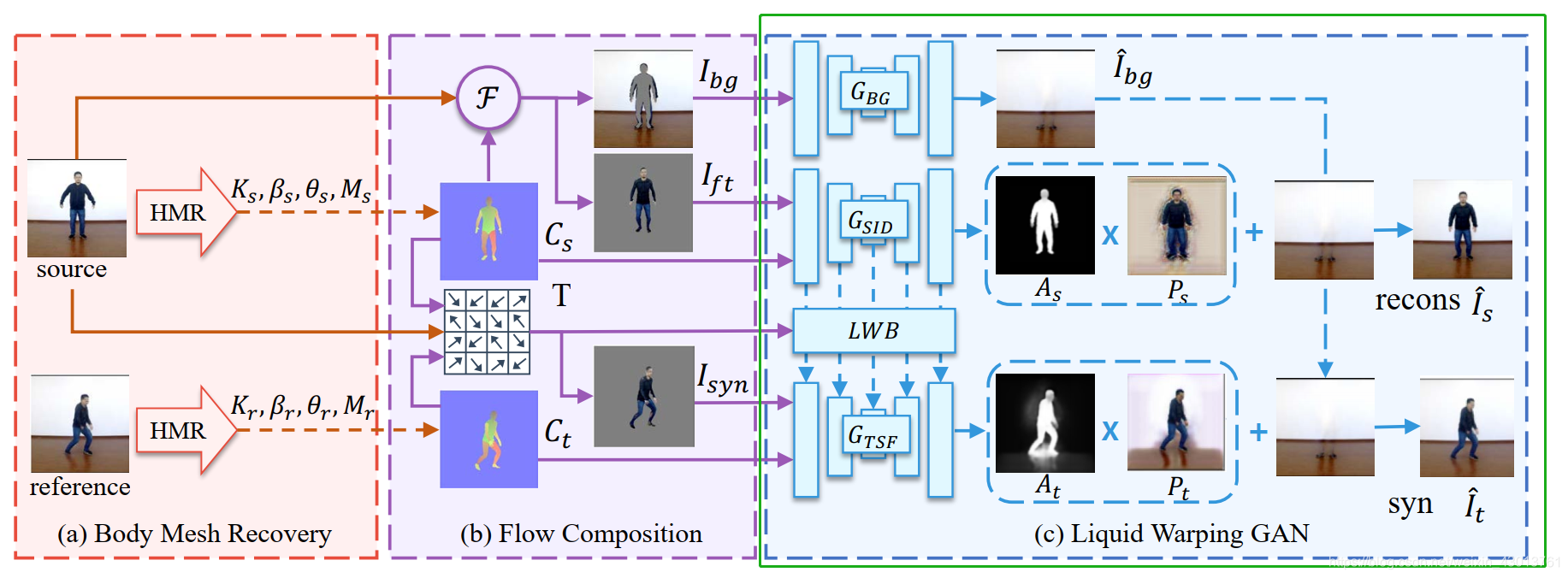
既然拿到了模型推断出来的结果,下一步当然就是进行loss的计算。
