版权声明:本文为博主原创文章,如需转载,请注明出处: https://blog.csdn.net/MASILEJFOAISEGJIAE/article/details/89294005
笔记目录:
【Spark实战】慕课网日志分析(一):数据初步清洗
【Spark实战】慕课网日志分析(二):数据二次清洗之日志解析
【Spark实战】慕课网日志分析(三):清理后数据的存储、统计和入库
【Spark实战】慕课网日志分析(四):将数据清洗的作业提交到YARN上运行
【Spark实战】慕课网日志分析(五):将数据统计和入库的作业提交到YARN上运行
本节目标
输入:原始数据10000_access.log,点击下载
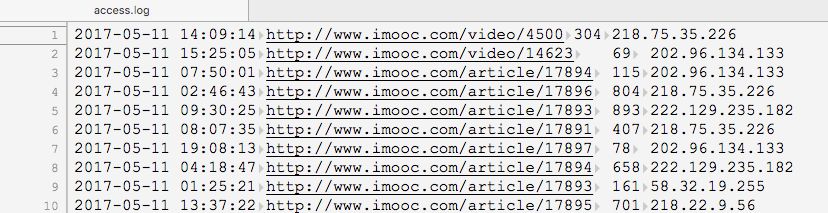
输出:初步清洗后的数据(访问时间、访问url、耗费的流量、访问ip)
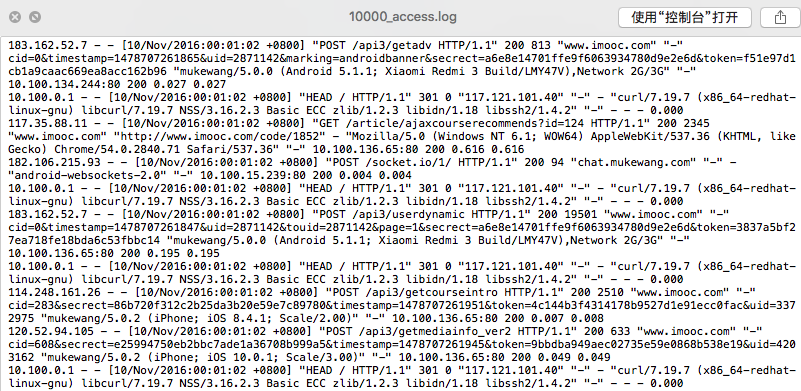
第一步:查看原始数据
object SparkStatFormatJob {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("SparkStatFormatJob")
.master("local[2]").getOrCreate()
val acccess = spark.sparkContext.textFile("D://10000_access.log")
acccess.take(10).foreach(println)
spark.stop()
}
}
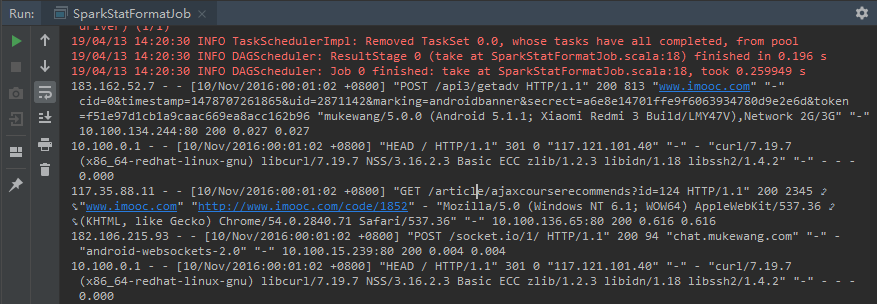
运行结果:
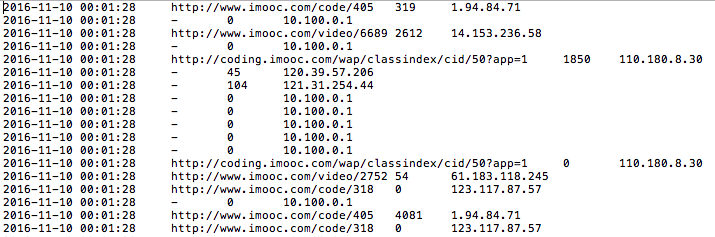
第二步:获取ip地址:
object SparkStatFormatJob {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("SparkStatFormatJob")
.master("local[2]").getOrCreate()
val acccess = spark.sparkContext.textFile("D://10000_access.log")
acccess.take(10).foreach(println)
acccess.map(line => {
val splits = line.split(" ")
splits(0)
}).take(10).foreach(println)
spark.stop()
}
}
运行结果:
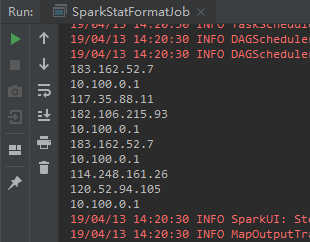
第三步: 获取时间日期,并转换格式
...
acccess.map(line => {
val splits = line.split(" ")
val ip = splits(0)
val time = splits(3) + " " + splits(4)
(ip, DateUtils.parse(time))
}).take(10).foreach(println)
...
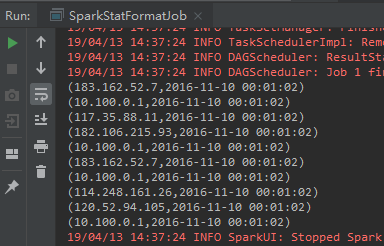
第四步:获取url和流量
...
acccess.map(line => {
val splits = line.split(" ")
val ip = splits(0)
val time = splits(3) + " " + splits(4)
val url = splits(11).replaceAll("\"","")
val traffic = splits(9)
DateUtils.parse(time) + "\t" + url + "\t" + traffic + "\t" + ip
}).take(10).foreach(println)
...
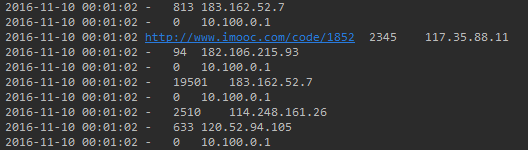
第五步:输出保存到本地文件
acccess.map(line => {
val splits = line.split(" ")
val ip = splits(0)
val time = splits(3) + " " + splits(4)
val url = splits(11).replaceAll("\"","")
val traffic = splits(9)
DateUtils.parse(time) + "\t" + url + "\t" + traffic + "\t" + ip
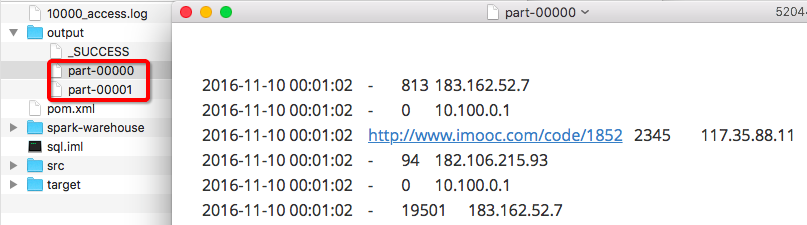
}).saveAsTextFile(".//output")
之前,为了在Windows系统上使用IDEA基于maven运行Spark程序,下载了Hadoop的winutils,也设置了环境变量,解决了NullPointerException的报错,具体排错方法记录在了这篇文章。
刚刚上面第四步的直接打印输出是正常的,但调用saveAsTextFile()保存到本地文件会报错:java.lang.ArrayIndexOutOfBoundsException。
然后,参考了这篇文章在dependency里面增加了一项的方法,然而并没有用。
于是换成Mac环境中使用IDEA,发现问题直接粗暴地解决了。
文件输出结果:
不过,输出不出来也没关系,之后直接使用另外一个清洗出来的文件:access.log,里面的数据是2017年5月份的日志: