卷积神经网络实现艺术风格化
基于卷积神经网络实现图片风格的迁移,可以用于大学生毕业设计基于python,深度学习,tensorflow卷积神经网络, 通过Vgg16实现,一幅图片内容特征的基础上添加另一幅图片的风格特征从而生成一幅新的图片。在卷积模型训练中,通过输入固定的图片来调整网络的参数从而达到利用图片训练网络的目的。而在生成特定风格图片时,固定已有的网络参数不变,调整图片从而使图片向目标风格转化。在内容风格转换时,调整图像的像素值,使其向目标图片在卷积网络输出的内容特征靠拢。在风格特征计算时,通过多个神经元的输出两两之间作内积求和得到Gram矩阵,然后对G矩阵做差求均值得到风格的损失函数。
示例代码:
import time
import numpy as np
import tensorflow as tf
from PIL import Image
from keras import backend
from keras.models import Model
from keras.applications.vgg16 import VGG16
from scipy.optimize import fmin_l_bfgs_b
from scipy.misc import imsave
加载和预处理内容和样式图像
加载内容和样式图像,注意,我们正在处理的内容图像质量不是特别高,但是在这个过程结束时我们将得到的输出看起来仍然非常好。
height = 512
width = 512
content_image_path = 'images/elephant.jpg'
content_image = Image.open(content_image_path)
content_image = content_image.resize((height, width))
content_image

style_image_path = 'images/styles/wave.jpg'
style_image = Image.open(style_image_path)
style_image = style_image.resize((height, width))
style_image

然后,我们将这些图像转换成适合于数值处理的形式。
特别注意,我们添加了另一个维度(高度x宽度x 3维度)
以便我们可以稍后将这两个图像的表示连接到一个公共数据结构中。
content_array = np.asarray(content_image, dtype='float32')
content_array = np.expand_dims(content_array, axis=0)
print(content_array.shape)
style_array = np.asarray(style_image, dtype='float32')
style_array = np.expand_dims(style_array, axis=0)
print(style_array.shape)
(1, 512, 512, 3)
(1, 512, 512, 3)
我们需要执行两个转换:
1.从每个像素中减去平均RGB值 (具体原因可查论文此处原因暂时省略)
2.将多维数组的顺序从RGB翻转到BGR(本文中使用的顺序)。
content_array[:, :, :, 0] -= 103.939
content_array[:, :, :, 1] -= 116.779
content_array[:, :, :, 2] -= 123.68
content_array = content_array[:, :, :, ::-1]
style_array[:, :, :, 0] -= 103.939
style_array[:, :, :, 1] -= 116.779
style_array[:, :, :, 2] -= 123.68
style_array = style_array[:, :, :, ::-1]
现在我们可以使用这些数组在Keras的后端(TensorFlow图)中定义变量了。
我们还引入了一个占位符变量来存储组合图像,
该图像在合并样式图像的样式时保留了内容图像的内容。
content_image = backend.variable(content_array)
style_image = backend.variable(style_array)
combination_image = backend.placeholder((1, height, width, 3))
NOISE_RATIO = 0.6
def generate_noise_image(content_image, noise_ratio = NOISE_RATIO):
"""
Returns a noise image intermixed with the content image at a certain ratio.
"""
noise_image = np.random.uniform(
-20, 20,
(1, height, width, 3)).astype('float32')
# White noise image from the content representation. Take a weighted average
# of the values
input_image = noise_image * noise_ratio + content_image * (1 - noise_ratio)
return input_image
content_image = tf.Variable(content_array,dtype=tf.float32)
style_image = tf.Variable(style_array,dtype=tf.float32)
# combination_image = tf.placeholder(dtype=tf.float32,shape = (1,height,width,3))
combination_image = tf.Variable(initial_value=generate_noise_image(content_image))
最后,我们将所有这些图像数据连接到一个张量中,
该张量适合用Keras’VGG16模型进行处理。
input_tensor = backend.concatenate([content_image,
style_image,
combination_image], axis=0)
#作用 将两个变量和占位符数据集成
input_tensor = tf.concat([content_image,style_image,combination_image],axis = 0)
input_tensor
重新使用预先训练的图像分类模型来定义损失函数
由于我们对分类问题不感兴趣,因此不需要完全连接的层或最终的softmax分类器。我们只需要下表中用绿色标记的那部分型号。
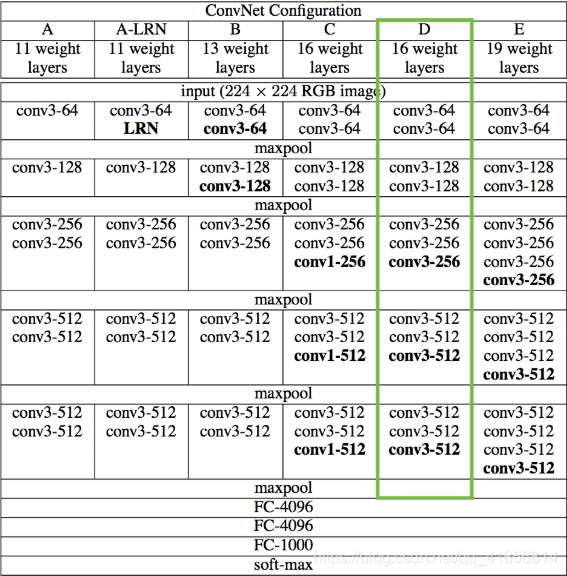
对于我们来说,访问这个被截断的模型是很简单的,因为Keras附带了一组预先训练的模型,包括我们感兴趣的VGG16模型。注意,通过在下面的代码中设置“include_top=False”,我们不包括任何完全连接的层。
model = VGG16(input_tensor=input_tensor, weights='imagenet',
include_top=False)
<keras.engine.training.Model at 0x267f261f208>
从上表可以看出,我们使用的模型有很多层。对于这些层,Keras有自己的名称。让我们列出这些名称,以便以后可以方便地引用各个层。
layers = dict([(layer.name, layer.output) for layer in model.layers])
layers
读取本地模型
import scipy as scipy
def load_vgg_model(path):
"""
Returns a model for the purpose of 'painting' the picture.
Takes only the convolution layer weights and wrap using the TensorFlow
Conv2d, Relu and AveragePooling layer. VGG actually uses maxpool but
the paper indicates that using AveragePooling yields better results.
The last few fully connected layers are not used.
Here is the detailed configuration of the VGG model:
0 is conv1_1 (3, 3, 3, 64)
1 is relu
2 is conv1_2 (3, 3, 64, 64)
3 is relu
4 is maxpool
5 is conv2_1 (3, 3, 64, 128)
6 is relu
7 is conv2_2 (3, 3, 128, 128)
8 is relu
9 is maxpool
10 is conv3_1 (3, 3, 128, 256)
11 is relu
12 is conv3_2 (3, 3, 256, 256)
13 is relu
14 is conv3_3 (3, 3, 256, 256)
15 is relu
16 is maxpool
17 is conv4_1 (3, 3, 256, 512)
18 is relu
19 is conv4_2 (3, 3, 512, 512)
20 is relu
21 is conv4_3 (3, 3, 512, 512)
22 is relu
23 is maxpool
24 is conv5_1 (3, 3, 512, 512)
25 is relu
26 is conv5_2 (3, 3, 512, 512)
27 is relu
28 is conv5_3 (3, 3, 512, 512)
29 is relu
30 is maxpool
31 is fullyconnected (7, 7, 512, 4096)
32 is relu
33 is fullyconnected (1, 1, 4096, 4096)
34 is relu
35 is fullyconnected (1, 1, 4096, 1000)
36 is softmax
"""
vgg = scipy.io.loadmat(path)
vgg_layers = vgg['layers']
def _weights(layer, expected_layer_name):
"""
Return the weights and bias from the VGG model for a given layer.
layers[0][0][0][0][2][0][0]
"""
W = vgg_layers[0][layer][0][0][2][0][0]
b = vgg_layers[0][layer][0][0][2][0][1]
layer_name = vgg_layers[0][layer][0][0][0]
assert layer_name == expected_layer_name
return W, b
def _relu(conv2d_layer):
"""
Return the RELU function wrapped over a TensorFlow layer. Expects a
Conv2d layer input.
"""
return tf.nn.relu(conv2d_layer)
def _conv2d(prev_layer, layer, layer_name):
"""
Return the Conv2D layer using the weights, biases from the VGG
model at 'layer'.
"""
W, b = _weights(layer, layer_name)
W = tf.constant(W)
b = tf.constant(np.reshape(b, (b.size)))
return tf.nn.conv2d(prev_layer, filter=W, strides=[1, 1, 1, 1], padding='SAME') + b
def _conv2d_relu(prev_layer, layer, layer_name):
"""
Return the Conv2D + RELU layer using the weights, biases from the VGG
model at 'layer'.
"""
return _relu(_conv2d(prev_layer, layer, layer_name))
# def _avgpool(prev_layer):
# """
# Return the AveragePooling layer.
# return tf.nn.avg_pool(prev_layer, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
def _avgpool(prev_layer):
return tf.nn.max_pool(prev_layer,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
# Constructs the graph model.
graph = {}
graph['input'] = input_tensor
graph['conv1_1'] = _conv2d_relu(graph['input'], 0, 'conv1_1')
graph['conv1_2'] = _conv2d_relu(graph['conv1_1'], 2, 'conv1_2')
graph['_maxpool1'] = _avgpool(graph['conv1_2'])
graph['conv2_1'] = _conv2d_relu(graph['_maxpool1'], 5, 'conv2_1')
graph['conv2_2'] = _conv2d_relu(graph['conv2_1'], 7, 'conv2_2')
graph['_maxpool2'] = _avgpool(graph['conv2_2'])
graph['conv3_1'] = _conv2d_relu(graph['_maxpool2'], 10, 'conv3_1')
graph['conv3_2'] = _conv2d_relu(graph['conv3_1'], 12, 'conv3_2')
graph['conv3_3'] = _conv2d_relu(graph['conv3_2'], 14, 'conv3_3')
graph['_maxpool3'] = _avgpool(graph['conv3_3'])
graph['conv4_1'] = _conv2d_relu(graph['_maxpool3'], 17, 'conv4_1')
graph['conv4_2'] = _conv2d_relu(graph['conv4_1'], 19, 'conv4_2')
graph['conv4_3'] = _conv2d_relu(graph['conv4_2'], 21, 'conv4_3')
graph['_maxpool4'] = _avgpool(graph['conv4_3'])
graph['conv5_1'] = _conv2d_relu(graph['_maxpool4'], 24, 'conv5_1')
graph['conv5_2'] = _conv2d_relu(graph['conv5_1'], 26, 'conv5_2')
graph['conv5_3'] = _conv2d_relu(graph['conv5_2'], 28, 'conv5_3')
graph['_maxpool5'] = _avgpool(graph['conv5_3'])
return graph
from scipy import io
import tensorflow as tf
model = load_vgg_model('./imagenet-vgg-verydeep-16.mat')
如果你盯着上面的单子看,你会相信我们已经把所有我们想要的东西都放在桌子上了(绿色的单元格)。还要注意,因为我们为Keras提供了一个具体的输入张量,所以各种张量流张量得到了定义良好的形状。
风格转换问题可以作为一个优化问题
其中我们希望最小化的损失函数可以分解为三个不同的部分:内容损失、风格损失和总变化损失。
这些项的相对重要性由一组标量权重决定。这些都是任意的,但是在经过相当多的实验之后选择了下面的集合,以找到一个生成对我来说美观的输出的集合。
content_weight = 0.025
style_weight = 5.0
total_variation_weight = 1.0
我们现在将使用模型的特定层提供的特征空间来定义这三个损失函数。我们首先将总损失初始化为0,然后分阶段将其相加。
loss = tf.Variable(0.)
loss
content_loss
content_loss 是内容的特征表示与组合图像之间的(缩放,平方)欧氏距离。
def content_loss(content, combination):
return tf.reduce_sum(tf.square(combination - content))
layer_features = model['conv2_2']
content_image_features = layer_features[0, :, :, :]
combination_features = layer_features[2, :, :, :]
loss += content_weight * content_loss(content_image_features,
combination_features)
风格损失
这就是事情开始变得有点复杂的地方。
对于样式丢失,我们首先定义一个称为Gram matrix的东西。该矩阵的项与对应特征集的协方差成正比,从而捕获关于哪些特征倾向于一起激活的信息。通过只捕获图像中的这些聚合统计信息,它们对图像中对象的特定排列是盲目的。这使他们能够捕获与内容无关的样式信息。(这根本不是微不足道的,我指的是[试图解释这个想法的论文] 。
通过对特征空间进行适当的重构并取外积,可以有效地计算出Gram矩阵。
def gram_matrix(x):
features = backend.batch_flatten(backend.permute_dimensions(x, (2, 0, 1)))
gram = backend.dot(features, backend.transpose(features))
return gram
#也可用tf的方法 不使用kears的后端
# def gram_matrix(x):
# ret = tf.transpose(x, (2, 0, 1))
# features = tf.reshape(ret,[ret.shape[0],-1])
# gram = tf.matmul(features,tf.transpose(features))
# return gram
样式损失是样式和组合图像的Gram矩阵之间的差的(缩放,平方)Frobenius范数。
同样,在下面的代码中,我选择使用Johnson等人定义的图层中的样式特性。(2016)而不是盖蒂等人。(2015)因为我觉得最终的结果更美观。我鼓励你尝试这些选择,以看到不同的结果。
def style_loss(style, combination):
S = gram_matrix(style)
C = gram_matrix(combination)
channels = 3
size = height * width
return tf.reduce_sum(tf.square(S - C)) / (4. * (channels ** 2) * (size ** 2))
feature_layers = ['conv1_2', 'conv2_2',
'conv3_3', 'conv4_3',
'conv5_3']
for layer_name in feature_layers:
layer_features = model[layer_name]
style_features = layer_features[1, :, :, :]
combination_features = layer_features[2, :, :, :]
sl = style_loss(style_features, combination_features)
loss += (style_weight / len(feature_layers)) * sl
总变化损失
现在我们回到了更简单的基础上。
如果您只使用我们目前介绍的两个损失项(样式和内容)来解决优化问题,您会发现输出非常嘈杂。因此,我们增加了另一个术语,称为[总变化损失](一个正则化项),它鼓励空间平滑。
您可以尝试减少“总变化”权重,并播放生成图像的噪声级别。
combination_image
def total_variation_loss(x):
a = tf.square(x[:, :height-1, :width-1, :] - x[:, 1:, :width-1, :])
b = tf.square(x[:, :height-1, :width-1, :] - x[:, :height-1, 1:, :])
return tf.reduce_sum(tf.pow(a + b, 1.25))
loss += total_variation_weight * total_variation_loss(combination_image)
optimizer = tf.train.AdamOptimizer(0.001).minimize(loss)
optimizer
定义所需的梯度并解决优化问题
现在,我们已经对输入图像进行了处理,并定义了了损失函数 calculators,
剩下的工作就是定义相对于组合图像的总损失的梯度,
并使用这些梯度对组合图像进行迭代改进,以最小化损失。
grads = backend.gradients(loss, combination_image)
grads
然后,我们需要定义一个“Evaluator”类,
它通过两个单独的函数“loss”和“grads”检索丢失和渐变。
之所以这样做,是因为“scipy.optimize”需要单独的函数来处理损失和梯度,但是单独计算它们将是低效的。
outputs = [loss]
outputs += grads
f_outputs = backend.function([combination_image], outputs)
def eval_loss_and_grads(x):
x = x.reshape((1, height, width, 3))
outs = f_outputs([x])
loss_value = outs[0]
grad_values = outs[1].flatten().astype('float64')
return loss_value, grad_values
class Evaluator(object):
def __init__(self):
self.loss_value = None
self.grads_values = None
def loss(self, x):
assert self.loss_value is None
loss_value, grad_values = eval_loss_and_grads(x)
self.loss_value = loss_value
self.grad_values = grad_values
return self.loss_value
def grads(self, x):
assert self.loss_value is not None
grad_values = np.copy(self.grad_values)
self.loss_value = None
self.grad_values = None
return grad_values
evaluator = Evaluator()
现在我们终于可以解决我们的优化问题了。这个组合图像的生命开始于一个随机的(有效的)像素集合,我们使用[L-BFGS]算法(一个比标准梯度下降更快收敛的准牛顿算法)迭代改进它。
我在2次迭代之后就停止了,因为时间问题,可以定义十次左右,效果较好损失可以自己观察。
evaluator.grads
x = np.random.uniform(0, 255, (1, height, width, 3)) - 128.
iterations = 2
for i in range(iterations):
print('Start of iteration', i)
start_time = time.time()
x, min_val, info = fmin_l_bfgs_b(evaluator.loss, x.flatten(),
fprime=evaluator.grads, maxfun=20)
print('Current loss value:', min_val)
end_time = time.time()
print('Iteration %d completed in %ds' % (i, end_time - start_time))
Start of iteration 0
Current loss value: 73757336000.0
Iteration 0 completed in 217s
Start of iteration 1
Current loss value: 36524343000.0
Iteration 1 completed in 196s
效果图
总结
尽管这段代码的输出非常漂亮,但用来生成它的过程非常缓慢。
不管你如何加速这个算法(使用gpu和创造性的黑客),
它仍然是一个相对昂贵的问题来解决。
这是因为我们每次想要生成图像时都在解决一个完整的优化问题。
