VGG16是一个16层的卷积神经网络模型,输入数据的维度为224*224*3,即长宽均为224像素的RGB彩色图片,VGG16模型的权重由ImageNet训练而来。由于其具有简单实用的优点,因此,在图像分类和目标检测任务中得到了较为广泛的应用。
1.卷积神经网络的基本概念
1.1卷积
简单的将其理解为一种数学运算,具体的计算过程如下图所示:
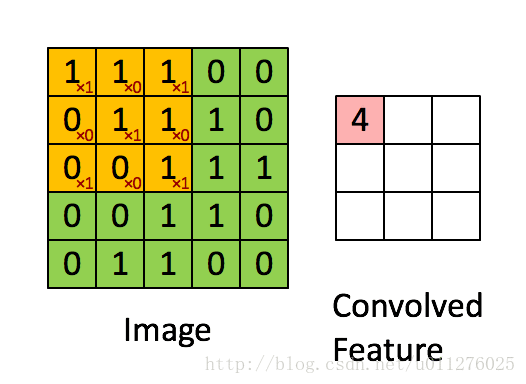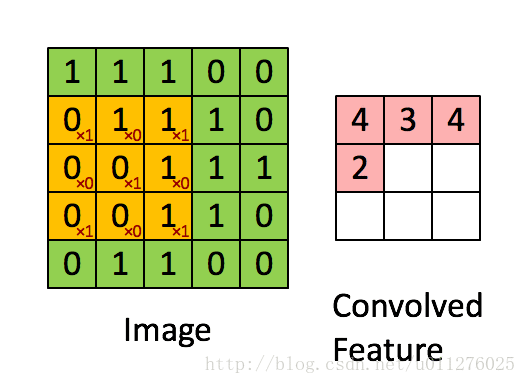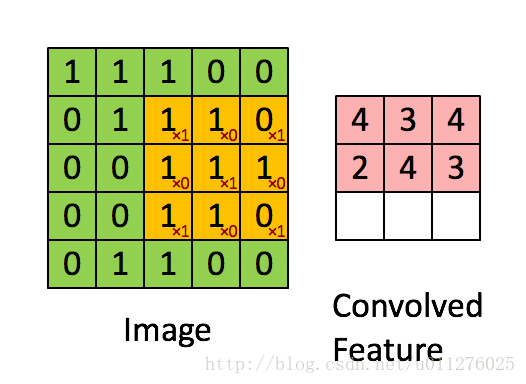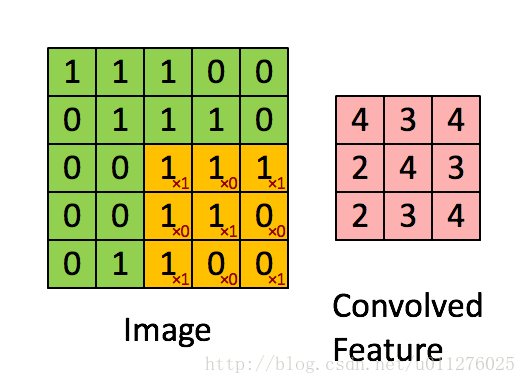
更多关于卷积的相关概念,请移步:神经网络之卷积理解
1.2池化
同样,池化也可以简单地理解为一种数学运算,常用的池化方法有最大池化(max-pooling)和均值池化(mean-pooling)。根据相关理论,特征提取的误差主要来自两个方面:
(1)邻域大小受限造成的估计值方差增大;
(2)卷积层参数误差造成估计均值的偏移。
一般来说,mean-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差,更多的保留纹理信息。与mean-pooling近似,在局部意义上,则服从max-pooling的准则。
max-pooling卷积核的大小一般是2×2。 非常大的输入量可能需要4x4。 但是,选择较大的形状会显着降低信号的尺寸,并可能导致信息过度丢失。 通常,不重叠的池化窗口表现最好。
卷积操作后我们提取了很多特征信息,相邻区域有相似特征信息,可以相互替代的,如果全部保留这些特征信息就会有信息冗余,增加了计算难度,这时候池化就相当于降维操作。池化是在一个小矩阵区域内,取该区域的最大值或平均值来代替该区域,该小矩阵的大小可以在搭建网络的时候自己设置。
2.VGG16卷积神经网络
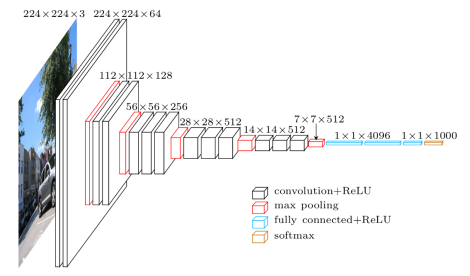
Keras的applications模块还提供很多带有预训练权重的Keras模型,这些模型可以直接用来进行预测、特征提取、微调和迁移学习。VGG16网络结构如下图所示,从左至右,一张彩色图片输入到网络,白色框是卷积层,红色是池化,蓝色是全连接层,棕色框是预测层。预测层的作用是将全连接层输出的信息转化为相应的类别概率,而起到分类作用。全连接层里有4096 个神经元,其实这里4096只是个经验值,其他数当然可以,只要不要小于要预测的类别数,这里要预测的类别有1000种,所以最后预测的全连接有1000个神经元。如果你想用VGG16 给自己的数据作分类任务,这里就需要改成你预测的类别数。即对于VGG16卷积神经网络而言,其13层卷积层和5层池化层负责进行特征的提取,最后的3层全连接层负责完成分类任务。
关于VGG16的详细信息请移步:VGG16学习笔记和如何从零使用 Keras + TensorFlow 开发一个复杂深度学习模型
利用keras的API该如何创建一个VGG16卷积神经网络呢?具体代码如下所示:
from keras import Sequential
from keras.layers import Dense, Activation, Conv2D, MaxPooling2D, Flatten, Dropout
from keras.layers import Input
from keras.optimizers import SGD
model = Sequential()
# BLOCK 1
model.add(Conv2D(filters = 64, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block1_conv1', input_shape = (224, 224, 3)))
model.add(Conv2D(filters = 64, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block1_conv2'))
model.add(MaxPooling2D(pool_size = (2, 2), strides = (2, 2), name = 'block1_pool'))
# BLOCK2
model.add(Conv2D(filters = 128, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block2_conv1'))
model.add(Conv2D(filters = 128, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block2_conv2'))
model.add(MaxPooling2D(pool_size = (2, 2), strides = (2, 2), name = 'block2_pool'))
# BLOCK3
model.add(Conv2D(filters = 256, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block3_conv1'))
model.add(Conv2D(filters = 256, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block3_conv2'))
model.add(Conv2D(filters = 256, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block3_conv3'))
model.add(MaxPooling2D(pool_size = (2, 2), strides = (2, 2), name = 'block3_pool'))
# BLOCK4
model.add(Conv2D(filters = 512, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block4_conv1'))
model.add(Conv2D(filters = 512, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block4_conv2'))
model.add(Conv2D(filters = 512, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block4_conv3'))
model.add(MaxPooling2D(pool_size = (2, 2), strides = (2, 2), name = 'block4_pool'))
# BLOCK5
model.add(Conv2D(filters = 512, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block5_conv1'))
model.add(Conv2D(filters = 512, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block5_conv2'))
model.add(Conv2D(filters = 512, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block5_conv3'))
model.add(MaxPooling2D(pool_size = (2, 2), strides = (2, 2), name = 'block5_pool'))
model.add(Flatten())
model.add(Dense(4096, activation = 'relu', name = 'fc1'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation = 'relu', name = 'fc2'))
model.add(Dropout(0.5))
model.add(Dense(1000, activation = 'softmax', name = 'prediction'))
VGG16卷积神经网络的网络结构可视化如下图所示:

1.首先输入(3,224,224)的图像数据,即一张宽224,高244的彩色RGB图片。
2.接着是卷积层,有64个(3,3)的卷积核,激活函数是relu 。
model.add(Convolution2D(64, 3, 3, activation='relu'))一个卷积核扫完图片,生成一个新的矩阵,64个就生成64 层。
3.接着再来一次卷积。此时图像数据是64*224*224。
model.add(Convolution2D(64, 3, 3, activation='relu'))4.接着是池化,小矩阵是(2,2) ,步长(2,2):横向每次移动2格,纵向每次移动2格。
model.add(MaxPooling2D((2,2), strides=(2,2)))按照这样池化之后,数据变成了64*112*112,矩阵的宽高由原来的224减半,变成了112。
5.再往下,同理,只不过是卷积核个数依次变成128,256,512,而每次按照这样池化之后,矩阵都要缩小一半。
13层卷积和5层池化之后,数据变成了 512*7*7。
6.然后Flatten(),将数据拉平成向量,变成一维512*7*7=25088。
7.接着是3个全连接层。
8.其中,为了防止过拟合的发生,加入Dropout层,在训练过程中每次更新参数时随机断开一定百分比(p)的输入神
经元连接。
model.add(Dropout(0.5))更多细节,可移步:卷积神经网络VGG16这么简单,为什么没人能说清?
VGG16参数解释:
- include_top:是否保留顶层的3个全连接网络;
- weights:None代表随机初始化,即不加载预训练权重。'imagenet'代表加载预训练权重。
include_top设置为false时,此时,多用于进行图像的特征提取,其网络的结构如下图所示:

如图所示,相对于第一个模型图,第二个模型图中少了3个全连接层,以及一个Flatten层。这里,Flatten层所做的工作只是将多维的矩阵拉开,变成一维向量来表示而已。
3.利用VGG16卷积神经网络识别狗
'''
Created on 2019年2月18日
@author: Administrator
'''
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import decode_predictions
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input
from keras.utils.vis_utils import plot_model
import numpy as np
model = VGG16(weights='imagenet',include_top=True);
image_path = 'E:/dog.jpg';
img = image.load_img(image_path,target_size=(224,224));
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
features = model.predict(x)
result = decode_predictions(features,top=3)
plot_model(model,'E:/model.png',show_shapes=True)
print(result)给定下述图片:

运行结果:
[[('n02109961', 'Eskimo_dog', 0.6355274),
('n02110185', 'Siberian_husky', 0.15040249),
('n02114367', 'timber_wolf', 0.05106628)]]注意,因为我们这里需要做的工作是分类,而非特征提取,因此,3个全连接层是需要的,include_top需要设置为True,即:
model = VGG16(weights='imagenet',include_top=True);更多keras的API请移步:keras中文文档