使用 VGG16 实现图像识别分类及VGG 19 实现艺术风格转移
一、VGG 简介
1.1 网络架构
- 训练输入: 固定尺寸224*224的RGB图像。
- 预处理:每个像素值减去训练集上的RGB均值。
- 卷积核:一系列3*3卷积核堆叠, 步长为1, 采用padding保持卷积后图像空
间分辨率不变。 - 空间池化:紧随卷积“堆”的最大池化,为2*2滑动窗口, 步长为2。
- 全连接层: 特征提取完成后,接三个全连接层, 前两个为4096通道, 第三个
为1000通道, 最后是一个soft-max层, 输出概率。 - 所有隐藏层都用非线性修正ReLu
- 下图是论文中提到的一些网络的架构
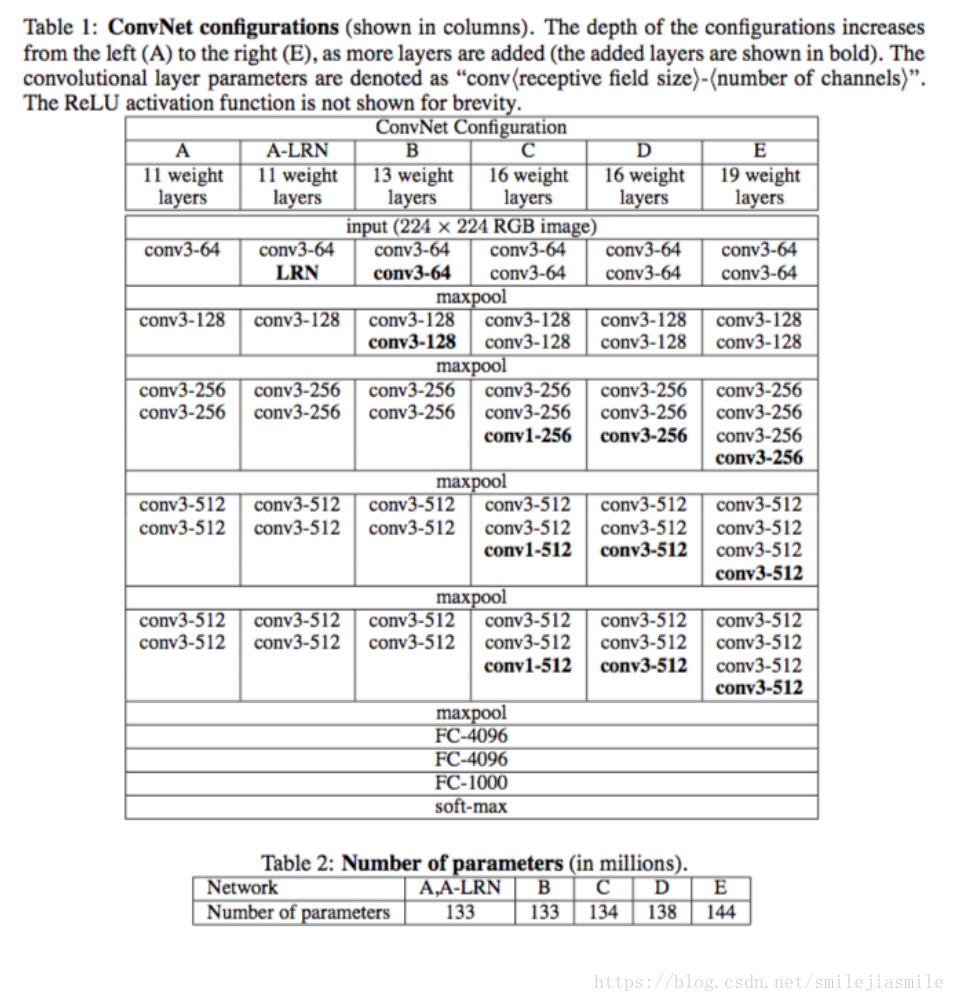
- 关于,本文实验代码,以及训练好的 VGG 参数均可以在此处下载:
链接:https://pan.baidu.com/s/1KfVDmiNwMPAIAfTLlLIXTw 密码:oh5f
1.2 VGG 代码上使用到的一些函数讲解
- 在 vgg 的喂入的 x 的 shape 是 [BATCH_SIZE,IMAGE_PIXELS],例如[ 50,28,28,3] 则说明一次喂入50张,像素为 28 x 28 的三通道的图像。
- np.load np.save:将数组以二进制格式保存到磁盘,扩展名为.npy 。
- 对于字典,我们可以采用字典 class 的 item()函数方法进行遍历(键值对)
- tf.shape(a)和 a.get_shape() 比较
相同点:都可以得到 tensor a 的尺寸
不同点: tf.shape()中 a 的数据类型可以是 tensor, list, array;而
a.get_shape()中 a 的数据类型只能是 tensor,且返回的是一个元组(tuple)import tensorflow as tf
import numpy as np
x=tf.constant([[1,2,3],[4,5,6]]
y = [[1,2,3],[4,5,6]]
z=np.arange(24).reshape([2,3,4]))
sess=tf.Session()
# tf.shape()
x_shape=tf.shape(x) # x_shape 是一个 tensor
y_shape=tf.shape(y) # <tf.Tensor 'Shape_2:0' shape=(2,) dtype=int32>
z_shape=tf.shape(z) # <tf.Tensor 'Shape_5:0' shape=(3,) dtype=int32>
print sess.run(x_shape) # 结果:[2 3]
print sess.run(y_shape) # 结果:[2 3]
print sess.run(z_shape) # 结果:[2 3 4]
#a.get_shape()
x_shape=x.get_shape() # 返回的是 TensorShape([Dimension(2),Dimension(3)]),
# 不能使用 sess.run(), 因为返回的不是 tensor 或 string,而是元组
x_shape=x.get_shape().as_list() # 可以使用 as_list()得到具体的尺寸, x_shape=[2 3]
y_shape=y.get_shape() # AttributeError: 'list' object has no attribute 'get_shape'
z_shape=z.get_shape() # AttributeError: 'numpy.ndarray' object has no attribute 'get_shape'- np.save:写数组到文件(未压缩二进制形式),文件默认的扩展名是.npy。
np.save(“名.npy”,某数组):将某数组写入“名.npy”文件。
某变量 = np.load(“名.npy”, encoding = ” “).item():将“名.npy”文件读出给某变量。 encoding = ” ” 可以不写‘latin1’ 、 ‘ASCII’ 、 ‘bytes’ ,默认为’ASCII’
>>> import numpy as np
A = np.arange(15).reshape(3,5)
>>> A
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
>>> np.save("A.npy",A) #如果文件路径末尾没有扩展名.npy,该扩展名会被
自动加上。
>>> B=np.load("A.npy")
>>> B
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])- tf.split(dimension, num_split, input):
dimension: 输入张量的哪一个维度,如果是 0 就表示对第 0 维度进行切割。
num_split: 切割的数量,如果是 2 就表示输入张量被切成 2 份,每一份是一个
列表。 - tf.concat(concat_dim, values)
- 还原 VGG 网络结果,实现特定应用的示意图,如下:
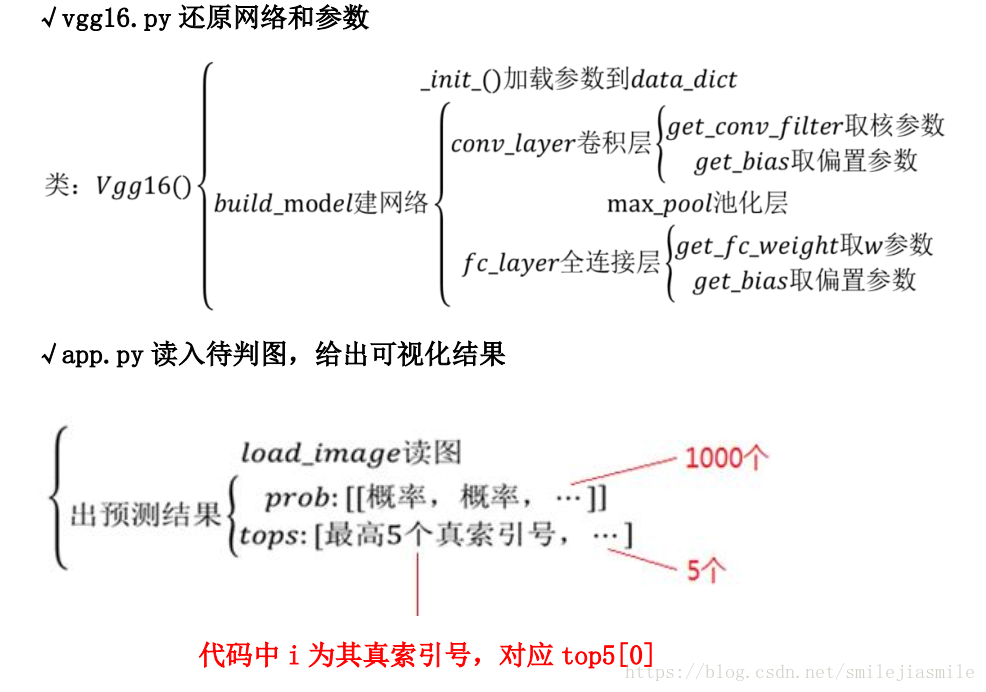
二、基于 VGG16 实现图像识别和分类TensorFlow 实现
# This is the VGG.py 最为主要的文件,实现了 VGG 的对象化管理,通过类成员函数的方法实现了前向传播,以及网络的构建
# coding: utf-8
import os
import time
import inspect
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
# 样本 BGR 的平均值
VGG_MEAN = [103.939, 116.779, 123.68]
# 将 VGG 按照对象的方式进行管理
class Vgg16():
def __init__(self, vgg16_path=None):
# 如果 vgg16_path 为 None 则说明使用默认的路径,当前路径拼接 vgg16.npy
if vgg16_path is None:
vgg16_path = os.path.join(os.getcwd(),'vgg16.npy')
# 然后,遍历模型参数 npy 文件,使用字典的 item()函数访问字典的每个元素,并且导入参数到 data_dict
self.data_dict = np.load(vgg16_path,encoding='latin1').item()
# 在初始化函数里面,答应 data_dict 里面的参数,以便观察其形状
for x in self.data_dict:
print x
# 定义前向传播
def forward(self,images):
print "Build model started"
start_time = time.time() # 获取前向传播的开始时间
rgb_scaled = images * 255.0 # 逐像素乘以 255.0(根据原论文所述的初始化步骤)
# 从 GRB 转换色彩通道到 BGR,也可使用 cv 中的 GRBtoBGR,并且为了减去均值操作而拆分
red, green, blue = tf.split(rgb_scaled,3,3)
# 以下 assert 都是加入断言,用来判断每个操作后的维度变化是否和预期一致,image 的第 0 个维度是 batch 数,后面的维度才是图像的描述
assert red.get_shape().as_list()[1:] == [224, 224, 1]
assert green.get_shape().as_list()[1:] == [224, 224, 1]
assert blue.get_shape().as_list()[1:] == [224, 224, 1]
# 逐样本减去每个通道的像素平均值,这种操作可以移除图像的平均亮度值,该方法常用在灰度图像上
bgr = tf.concat([
blue - VGG_MEAN[0],
green - VGG_MEAN[1],
red - VGG_MEAN[2]],3)
assert bgr.get_shape().as_list()[1:] == [224,224,3]
# 接下来构建 VGG 的 16 层网络(包含 5 段卷积, 3 层全连接),并逐层根据命名空间读取网络参数
# 第一段卷积,含有两个卷积层,后面接最大池化层,用来缩小图片尺寸
self.conv1_1 = self.conv_layer(bgr,'conv1_1')
self.conv1_2 = self.conv_layer(self.conv1_1,'conv1_2')
self.pool1 = self.max_pool_2x2(self.conv1_2,'pool1')
# 第二段卷积
self.conv2_1 = self.conv_layer(self.pool1,'conv2_1')
self.conv2_2 = self.conv_layer(self.conv2_1,'conv2_2')
self.pool2 = self.max_pool_2x2(self.conv2_2,'pool2')
# 第三段卷积,包含三个卷积层,一个最大池化层
self.conv3_1 = self.conv_layer(self.pool2,'conv3_1')
self.conv3_2 = self.conv_layer(self.conv3_1,'conv3_2')
self.conv3_3 = self.conv_layer(self.conv3_2,'conv3_3')
self.pool3 = self.max_pool_2x2(self.conv3_3,'pool3')
# 第四段卷积,包含三个卷积层,一个最大池化层
self.conv4_1 = self.conv_layer(self.pool3,'conv4_1')
self.conv4_2 = self.conv_layer(self.conv4_1,'conv4_2')
self.conv4_3 = self.conv_layer(self.conv4_2,'conv4_3')
self.pool4 = self.max_pool_2x2(self.conv4_3,'pool4')
# 第五段卷积,包含三个卷积层,一个最大池化层
self.conv5_1 = self.conv_layer(self.pool4,'conv5_1')
self.conv5_2 = self.conv_layer(self.conv5_1,'conv5_2')
self.conv5_3 = self.conv_layer(self.conv5_2,'conv5_3')
self.pool5 = self.max_pool_2x2(self.conv5_3,'pool5')
# 第六层全连接
self.fc6 = self.fc_layer(self.pool5,'fc6')
self.relu6 = tf.nn.relu(self.fc6)
# 第七层全连接,和上一层同理
self.fc7 = self.fc_layer(self.relu6,'fc7')
self.relu7 = tf.nn.relu(self.fc7)
# 第八层全连接
self.fc8 = self.fc_layer(self.relu7,'fc8')
# 经过最后一层的全连接后,再做 softmax 分类,得到属于各类别的概率
self.prob = tf.nn.softmax(self.fc8,name='prob')
end_time = time.time()
print 'time consuming: %f'% (end_time - start_time)
self.data_dict = None # 清空本次读取到的模型参数字典
def conv_layer(self, x, name):
with tf.variable_scope(name): # 根据命名空间找到对应卷积层的网络参数
w = self.get_conv_filter(name) # 得到该层的卷积核
conv = tf.nn.conv2d(x, w, [1, 1, 1, 1],padding='SAME') # 卷积计算
conv_biases = self.get_bias(name) # 读取偏置项
result = tf.nn.relu(tf.nn.bias_add(conv,conv_biases))
return result
# 定义获取卷积核的函数
def get_conv_filter(self,name):
return tf.constant(self.data_dict[name][0],name='filter')
# 定义获取偏置项的函数
def get_bias(self,name):
return tf.constant(self.data_dict[name][1],name='biases')
# 定义最大池化操作
def max_pool_2x2(self,x,name):
return tf.nn.max_pool(x,ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1],padding='SAME',name=name)
# 定义全连接层的前向传播计算
def fc_layer(self, x, name):
with tf.variable_scope(name): # 根据命名空间 name 做全连接层的计算
shape = x.get_shape().as_list() # 获取该层的维度信息列表
dim = 1 # 记录维度乘积
for i in shape[1:]:
dim *= i # 将每层的维度相乘
# 改变特征图的形状,也就是将得到的多维特征做拉伸操作,只在进入第六层全连接层做该操作
x = tf.reshape(x,[-1,dim])
w = self.get_fc_weight(name) # 读到权重值
b = self.get_bias(name)
result = tf.nn.bias_add(tf.matmul(x,w),b) # 对该层输入做权值求和,再加上偏置
return result
def get_fc_weight(self,name): # 根据命名空间 name 从参数字典中取到对应的权重
return tf.constant(self.data_dict[name][0],name='weights')
# THis is the utils 主要是一些使用到的工具函数定义实现,辅助函数,包括图像的预处理等等
# coding: utf-8
from skimage import io, transform
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei'] # 正常显示中文标签
mpl.rcParams['axes.unicode_minus']=False # 正常显示正负号
def load_image(path):
fig = plt.figure('Centre and Resize')
img = io.imread(path) # 根据传入的路径读入图片
img = img / 255.0 # 将像素归一化到 [0,1]
# 将该画布分为一行三列
ax0 = fig.add_subplot(131) # 把下面的图像放在该画布的第一个位置
ax0.set_xlabel(u'Original Picture') # 添加子标签
ax0.imshow(img) # 添加展示该图像
# 找到该图像的最短边
short_edge = min(img.shape[:2])
# 把图像的 w 和 h 分别减去最短边,并求平均
y = (img.shape[0] - short_edge) / 2
x = (img.shape[1] - short_edge) / 2
crop_img = img[y:y+short_edge,x:x+short_edge] # 取出切分出的中心图像
# 把下面的图像放在该画布的第二个位置
ax1 = fig.add_subplot(132)
ax1.set_xlabel(u'Centre Picture') # 把下面的图像放在该画布的第二个位置
ax1.imshow(crop_img)
re_img = transform.resize(crop_img,(224,224)) # resize 成固定的 imag_szie
ax2 = fig.add_subplot(133) # 把下面的图像放在该画布的第三个位置
ax2.set_xlabel(u'Resize Picture')
ax2.imshow(re_img)
img_ready = re_img.reshape((1, 224, 224, 3))
return img_ready
# 定义百分比转换函数
def percent(value):
return '%.2f%%' %(value * 100)
# This is the app.py 这是实现特定应用的程序,我们使用落地的程序
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import time
# 导入自定义模块
import vgg16
import utils
from Nclasses import labels
image_path = raw_input('Input the path and image name:')
# 调用 load_image()函数,对待测试的图像做一些预处理操作
img_ready = utils.load_image(image_path)
#定义一个 figure 画图窗口,并指定窗口的名称,也可以设置窗口修的大小
fig = plt.figure(u'Top-5 预测结果')
with tf.Session() as sess:
# 定义一个维度为[1,224,224,3],类型为 float32 的 tensor 占位符
images = tf.placeholder(tf.float32,[1, 224, 224, 3])
vgg = vgg16.Vgg16()
# 调用类的成员方法 forward(),并传入待测试图像,这也就是网络前向传播的过程
vgg.forward(images)
start_time = time.time()
# 将一个 batch 的数据喂入网络,得到网络的预测输出
probability = sess.run(vgg.prob,feed_dict={images:img_ready})
end_time = time.time()
print 'Cumputer times: %f'% (end_time - start_time)
# np.argsort 函数返回预测值( probability 的数据结构[[各预测类别的概率值]])由小到大的索引值,
# 并取出预测概率最大的五个索引值
top5 = np.argsort(probability[0])[-1:-6:-1]
print 'Top5: ', top5
# 定义两个 list---对应的概率值和实际标签( zebra)
values = []
bar_label = []
for n, i in enumerate(top5):
# 枚举上面取出的五个索引值
print 'n: ', n
print 'i: ', i
values.append(probability[0][i]) # 将索引值对应的预测概率值取出并放入 values
bar_label.append(labels[i]) # 根据索引值取出对应的实际标签并放入 bar_label
print i, ":", labels[i], "----", utils.percent(probability[0][i]) # 打印属于某个类别的概率
ax = fig.add_subplot(111) # 将画布划分为一行一列,并把下图放入其中
# bar()函数绘制柱状图,参数 range(len(values)是柱子下标, values 表示柱高的列表(也就是五个预测概率值,
# tick_label 是每个柱子上显示的标签(实际对应的标签), width 是柱子的宽度, fc 是柱子的颜色)
ax.bar(range(len(values)),values,tick_label=bar_label,width=0.5,fc='g')
ax.set_ylabel(u'probabilityit') # 设置纵轴标签
ax.set_title(u'Top-5') # 添加标题
for a, b in zip(range(len(values)),values):
# 在每个柱子的顶端添加对应的预测概率值, a, b 表示坐标, b+0.0005 表示要把文本信息放置在高于每个柱子顶端0.0005 的位置,
# center 是表示文本位于柱子顶端水平方向上的的中间位置, bottom 是将文本水平放置在柱子顶端垂直方向上的底端位置, fontsize 是字号
ax.text(a,b+0.0005,utils.percent(b),ha='center',va='bottom',fontsize=7)
plt.show()
三、基于 VGG 19 实现艺术风格转移
- 这里,我们会基于 Leon Gatys 的论文《艺术风格的神经网络算法》,我们不会从新训练系数矩阵,因为我们只是想获得图片在VGGNet19模型中的某些隐藏层上的特征矩阵。所以我们这里使用已经训练好的VGGNet19模型的参数,故通过使用官方已经训练好了的系数矩阵,通过 Scipy 的 io.loadmat 进行加载,以实现特定应用,故这里先给出已经训练好了的 VGG19 的模型参数的下载地址,如下:
下载地址:http://www.vlfeat.org/matconvnet/models/beta16/imagenet-vgg-verydeep-19.mat
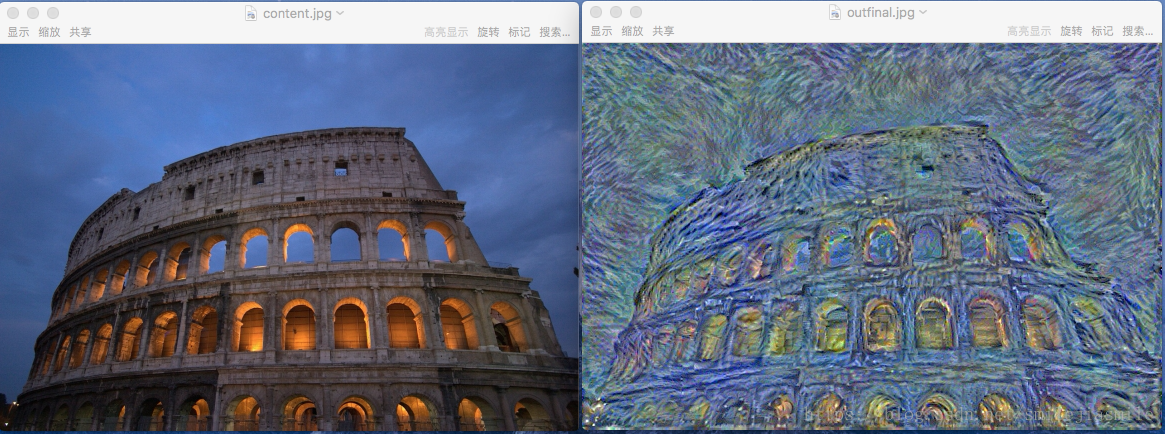
根据命令行参数提示,你可以在 shell 上执行如下命令行即可,开始训练,这里需要注意,我们需要两个图片作为输入,一个是希望艺术化的原始图片,第二个是具有 style 风格的的艺术图片本身。 –content 配置原图片参数,–style 配置想要转换成的艺术风格的图片参数,
content 图片

- style 风格图片

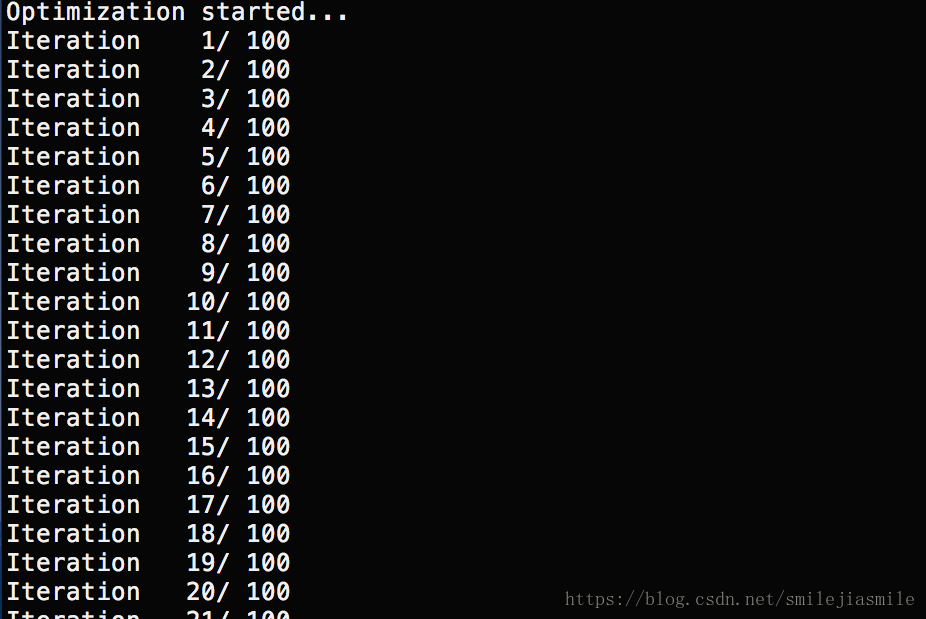
- 此外,我们这里考虑到时间因素,想快速得到结果,故只选择了迭代 100,当然如果可以迭代 1000 次,按理说图片转移风格会更加真实。这里,读者可以自行实验。
python neural_style.py --content content.jpg --styles style.jpg --checkpoint-iterations=10 --iterations=100 --checkpoint-output=out%s.jpg --output=outfinal.jpg下面是执行的过程图示
100 次迭代后,如果读者想得到更好的效果,可自行增加迭代次数:
源代码如下:
vgg.py
# Copyright (c) 2015-2017 Anish Athalye. Released under GPLv3.
import tensorflow as tf
import numpy as np
import scipy.io
VGG19_LAYERS = (
'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1',
'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3',
'relu3_3', 'conv3_4', 'relu3_4', 'pool3',
'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3',
'relu4_3', 'conv4_4', 'relu4_4', 'pool4',
'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3',
'relu5_3', 'conv5_4', 'relu5_4'
)
def load_net(data_path):
data = scipy.io.loadmat(data_path)
mean = data['normalization'][0][0][0]
mean_pixel = np.mean(mean, axis=(0, 1))
weights = data['layers'][0]
return weights, mean_pixel
def net_preloaded(weights, input_image, pooling):
net = {}
current = input_image
for i, name in enumerate(VGG19_LAYERS):
kind = name[:4]
if kind == 'conv':
kernels, bias = weights[i][0][0][0][0]
# matconvnet: weights are [width, height, in_channels, out_channels]
# tensorflow: weights are [height, width, in_channels, out_channels]
kernels = np.transpose(kernels, (1, 0, 2, 3))
bias = bias.reshape(-1)
current = _conv_layer(current, kernels, bias)
elif kind == 'relu':
current = tf.nn.relu(current)
elif kind == 'pool':
current = _pool_layer(current, pooling)
net[name] = current
assert len(net) == len(VGG19_LAYERS)
return net
def _conv_layer(input, weights, bias):
conv = tf.nn.conv2d(input, tf.constant(weights), strides=(1, 1, 1, 1),
padding='SAME')
return tf.nn.bias_add(conv, bias)
def _pool_layer(input, pooling):
if pooling == 'avg':
return tf.nn.avg_pool(input, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1),
padding='SAME')
else:
return tf.nn.max_pool(input, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1),
padding='SAME')
def preprocess(image, mean_pixel):
return image - mean_pixel
def unprocess(image, mean_pixel):
return image + mean_pixel
- stylize.py
# Copyright (c) 2015-2017 Anish Athalye. Released under GPLv3.
import vgg
import tensorflow as tf
import numpy as np
from sys import stderr
from PIL import Image
CONTENT_LAYERS = ('relu4_2', 'relu5_2')
STYLE_LAYERS = ('relu1_1', 'relu2_1', 'relu3_1', 'relu4_1', 'relu5_1')
try:
reduce
except NameError:
from functools import reduce
def stylize(network, initial, initial_noiseblend, content, styles, preserve_colors, iterations,
content_weight, content_weight_blend, style_weight, style_layer_weight_exp, style_blend_weights, tv_weight,
learning_rate, beta1, beta2, epsilon, pooling,
print_iterations=None, checkpoint_iterations=None):
"""
Stylize images.
This function yields tuples (iteration, image); `iteration` is None
if this is the final image (the last iteration). Other tuples are yielded
every `checkpoint_iterations` iterations.
:rtype: iterator[tuple[int|None,image]]
"""
shape = (1,) + content.shape
style_shapes = [(1,) + style.shape for style in styles]
content_features = {}
style_features = [{} for _ in styles]
vgg_weights, vgg_mean_pixel = vgg.load_net(network)
layer_weight = 1.0
style_layers_weights = {}
for style_layer in STYLE_LAYERS:
style_layers_weights[style_layer] = layer_weight
layer_weight *= style_layer_weight_exp
# normalize style layer weights
layer_weights_sum = 0
for style_layer in STYLE_LAYERS:
layer_weights_sum += style_layers_weights[style_layer]
for style_layer in STYLE_LAYERS:
style_layers_weights[style_layer] /= layer_weights_sum
# compute content features in feedforward mode
g = tf.Graph()
with g.as_default(), g.device('/cpu:0'), tf.Session() as sess:
image = tf.placeholder('float', shape=shape)
net = vgg.net_preloaded(vgg_weights, image, pooling)
content_pre = np.array([vgg.preprocess(content, vgg_mean_pixel)])
for layer in CONTENT_LAYERS:
content_features[layer] = net[layer].eval(feed_dict={image: content_pre})
# compute style features in feedforward mode
for i in range(len(styles)):
g = tf.Graph()
with g.as_default(), g.device('/cpu:0'), tf.Session() as sess:
image = tf.placeholder('float', shape=style_shapes[i])
net = vgg.net_preloaded(vgg_weights, image, pooling)
style_pre = np.array([vgg.preprocess(styles[i], vgg_mean_pixel)])
for layer in STYLE_LAYERS:
features = net[layer].eval(feed_dict={image: style_pre})
features = np.reshape(features, (-1, features.shape[3]))
gram = np.matmul(features.T, features) / features.size
style_features[i][layer] = gram
initial_content_noise_coeff = 1.0 - initial_noiseblend
# make stylized image using backpropogation
with tf.Graph().as_default():
if initial is None:
noise = np.random.normal(size=shape, scale=np.std(content) * 0.1)
initial = tf.random_normal(shape) * 0.256
else:
initial = np.array([vgg.preprocess(initial, vgg_mean_pixel)])
initial = initial.astype('float32')
noise = np.random.normal(size=shape, scale=np.std(content) * 0.1)
initial = (initial) * initial_content_noise_coeff + (tf.random_normal(shape) * 0.256) * (1.0 - initial_content_noise_coeff)
image = tf.Variable(initial)
net = vgg.net_preloaded(vgg_weights, image, pooling)
# content loss
content_layers_weights = {}
content_layers_weights['relu4_2'] = content_weight_blend
content_layers_weights['relu5_2'] = 1.0 - content_weight_blend
content_loss = 0
content_losses = []
for content_layer in CONTENT_LAYERS:
content_losses.append(content_layers_weights[content_layer] * content_weight * (2 * tf.nn.l2_loss(
net[content_layer] - content_features[content_layer]) /
content_features[content_layer].size))
content_loss += reduce(tf.add, content_losses)
# style loss
style_loss = 0
for i in range(len(styles)):
style_losses = []
for style_layer in STYLE_LAYERS:
layer = net[style_layer]
_, height, width, number = map(lambda i: i.value, layer.get_shape())
size = height * width * number
feats = tf.reshape(layer, (-1, number))
gram = tf.matmul(tf.transpose(feats), feats) / size
style_gram = style_features[i][style_layer]
style_losses.append(style_layers_weights[style_layer] * 2 * tf.nn.l2_loss(gram - style_gram) / style_gram.size)
style_loss += style_weight * style_blend_weights[i] * reduce(tf.add, style_losses)
# total variation denoising
tv_y_size = _tensor_size(image[:,1:,:,:])
tv_x_size = _tensor_size(image[:,:,1:,:])
tv_loss = tv_weight * 2 * (
(tf.nn.l2_loss(image[:,1:,:,:] - image[:,:shape[1]-1,:,:]) /
tv_y_size) +
(tf.nn.l2_loss(image[:,:,1:,:] - image[:,:,:shape[2]-1,:]) /
tv_x_size))
# overall loss
loss = content_loss + style_loss + tv_loss
# optimizer setup
train_step = tf.train.AdamOptimizer(learning_rate, beta1, beta2, epsilon).minimize(loss)
def print_progress():
stderr.write(' content loss: %g\n' % content_loss.eval())
stderr.write(' style loss: %g\n' % style_loss.eval())
stderr.write(' tv loss: %g\n' % tv_loss.eval())
stderr.write(' total loss: %g\n' % loss.eval())
# optimization
best_loss = float('inf')
best = None
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
stderr.write('Optimization started...\n')
if (print_iterations and print_iterations != 0):
print_progress()
for i in range(iterations):
stderr.write('Iteration %4d/%4d\n' % (i + 1, iterations))
train_step.run()
last_step = (i == iterations - 1)
if last_step or (print_iterations and i % print_iterations == 0):
print_progress()
if (checkpoint_iterations and i % checkpoint_iterations == 0) or last_step:
this_loss = loss.eval()
if this_loss < best_loss:
best_loss = this_loss
best = image.eval()
img_out = vgg.unprocess(best.reshape(shape[1:]), vgg_mean_pixel)
if preserve_colors and preserve_colors == True:
original_image = np.clip(content, 0, 255)
styled_image = np.clip(img_out, 0, 255)
# Luminosity transfer steps:
# 1. Convert stylized RGB->grayscale accoriding to Rec.601 luma (0.299, 0.587, 0.114)
# 2. Convert stylized grayscale into YUV (YCbCr)
# 3. Convert original image into YUV (YCbCr)
# 4. Recombine (stylizedYUV.Y, originalYUV.U, originalYUV.V)
# 5. Convert recombined image from YUV back to RGB
# 1
styled_grayscale = rgb2gray(styled_image)
styled_grayscale_rgb = gray2rgb(styled_grayscale)
# 2
styled_grayscale_yuv = np.array(Image.fromarray(styled_grayscale_rgb.astype(np.uint8)).convert('YCbCr'))
# 3
original_yuv = np.array(Image.fromarray(original_image.astype(np.uint8)).convert('YCbCr'))
# 4
w, h, _ = original_image.shape
combined_yuv = np.empty((w, h, 3), dtype=np.uint8)
combined_yuv[..., 0] = styled_grayscale_yuv[..., 0]
combined_yuv[..., 1] = original_yuv[..., 1]
combined_yuv[..., 2] = original_yuv[..., 2]
# 5
img_out = np.array(Image.fromarray(combined_yuv, 'YCbCr').convert('RGB'))
yield (
(None if last_step else i),
img_out
)
def _tensor_size(tensor):
from operator import mul
return reduce(mul, (d.value for d in tensor.get_shape()), 1)
def rgb2gray(rgb):
return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])
def gray2rgb(gray):
w, h = gray.shape
rgb = np.empty((w, h, 3), dtype=np.float32)
rgb[:, :, 2] = rgb[:, :, 1] = rgb[:, :, 0] = gray
return rgb
- neural_style.py
# Copyright (c) 2015-2017 Anish Athalye. Released under GPLv3.
import os
import numpy as np
import scipy.misc
from stylize import stylize
import math
from argparse import ArgumentParser
from PIL import Image
# default arguments
CONTENT_WEIGHT = 5e0
CONTENT_WEIGHT_BLEND = 1
STYLE_WEIGHT = 5e2
TV_WEIGHT = 1e2
STYLE_LAYER_WEIGHT_EXP = 1
LEARNING_RATE = 1e1
BETA1 = 0.9
BETA2 = 0.999
EPSILON = 1e-08
STYLE_SCALE = 1.0
ITERATIONS = 1000
VGG_PATH = 'imagenet-vgg-verydeep-19.mat'
POOLING = 'max'
def build_parser():
parser = ArgumentParser()
parser.add_argument('--content',
dest='content', help='content image',
metavar='CONTENT', required=True)
parser.add_argument('--styles',
dest='styles',
nargs='+', help='one or more style images',
metavar='STYLE', required=True)
parser.add_argument('--output',
dest='output', help='output path',
metavar='OUTPUT', required=True)
parser.add_argument('--iterations', type=int,
dest='iterations', help='iterations (default %(default)s)',
metavar='ITERATIONS', default=ITERATIONS)
parser.add_argument('--print-iterations', type=int,
dest='print_iterations', help='statistics printing frequency',
metavar='PRINT_ITERATIONS')
parser.add_argument('--checkpoint-output',
dest='checkpoint_output', help='checkpoint output format, e.g. output%%s.jpg',
metavar='OUTPUT')
parser.add_argument('--checkpoint-iterations', type=int,
dest='checkpoint_iterations', help='checkpoint frequency',
metavar='CHECKPOINT_ITERATIONS')
parser.add_argument('--width', type=int,
dest='width', help='output width',
metavar='WIDTH')
parser.add_argument('--style-scales', type=float,
dest='style_scales',
nargs='+', help='one or more style scales',
metavar='STYLE_SCALE')
parser.add_argument('--network',
dest='network', help='path to network parameters (default %(default)s)',
metavar='VGG_PATH', default=VGG_PATH)
parser.add_argument('--content-weight-blend', type=float,
dest='content_weight_blend', help='content weight blend, conv4_2 * blend + conv5_2 * (1-blend) (default %(default)s)',
metavar='CONTENT_WEIGHT_BLEND', default=CONTENT_WEIGHT_BLEND)
parser.add_argument('--content-weight', type=float,
dest='content_weight', help='content weight (default %(default)s)',
metavar='CONTENT_WEIGHT', default=CONTENT_WEIGHT)
parser.add_argument('--style-weight', type=float,
dest='style_weight', help='style weight (default %(default)s)',
metavar='STYLE_WEIGHT', default=STYLE_WEIGHT)
parser.add_argument('--style-layer-weight-exp', type=float,
dest='style_layer_weight_exp', help='style layer weight exponentional increase - weight(layer<n+1>) = weight_exp*weight(layer<n>) (default %(default)s)',
metavar='STYLE_LAYER_WEIGHT_EXP', default=STYLE_LAYER_WEIGHT_EXP)
parser.add_argument('--style-blend-weights', type=float,
dest='style_blend_weights', help='style blending weights',
nargs='+', metavar='STYLE_BLEND_WEIGHT')
parser.add_argument('--tv-weight', type=float,
dest='tv_weight', help='total variation regularization weight (default %(default)s)',
metavar='TV_WEIGHT', default=TV_WEIGHT)
parser.add_argument('--learning-rate', type=float,
dest='learning_rate', help='learning rate (default %(default)s)',
metavar='LEARNING_RATE', default=LEARNING_RATE)
parser.add_argument('--beta1', type=float,
dest='beta1', help='Adam: beta1 parameter (default %(default)s)',
metavar='BETA1', default=BETA1)
parser.add_argument('--beta2', type=float,
dest='beta2', help='Adam: beta2 parameter (default %(default)s)',
metavar='BETA2', default=BETA2)
parser.add_argument('--eps', type=float,
dest='epsilon', help='Adam: epsilon parameter (default %(default)s)',
metavar='EPSILON', default=EPSILON)
parser.add_argument('--initial',
dest='initial', help='initial image',
metavar='INITIAL')
parser.add_argument('--initial-noiseblend', type=float,
dest='initial_noiseblend', help='ratio of blending initial image with normalized noise (if no initial image specified, content image is used) (default %(default)s)',
metavar='INITIAL_NOISEBLEND')
parser.add_argument('--preserve-colors', action='store_true',
dest='preserve_colors', help='style-only transfer (preserving colors) - if color transfer is not needed')
parser.add_argument('--pooling',
dest='pooling', help='pooling layer configuration: max or avg (default %(default)s)',
metavar='POOLING', default=POOLING)
return parser
def main():
parser = build_parser()
options = parser.parse_args()
if not os.path.isfile(options.network):
parser.error("Network %s does not exist. (Did you forget to download it?)" % options.network)
content_image = imread(options.content)
style_images = [imread(style) for style in options.styles]
width = options.width
if width is not None:
new_shape = (int(math.floor(float(content_image.shape[0]) /
content_image.shape[1] * width)), width)
content_image = scipy.misc.imresize(content_image, new_shape)
target_shape = content_image.shape
for i in range(len(style_images)):
style_scale = STYLE_SCALE
if options.style_scales is not None:
style_scale = options.style_scales[i]
style_images[i] = scipy.misc.imresize(style_images[i], style_scale *
target_shape[1] / style_images[i].shape[1])
style_blend_weights = options.style_blend_weights
if style_blend_weights is None:
# default is equal weights
style_blend_weights = [1.0/len(style_images) for _ in style_images]
else:
total_blend_weight = sum(style_blend_weights)
style_blend_weights = [weight/total_blend_weight
for weight in style_blend_weights]
initial = options.initial
if initial is not None:
initial = scipy.misc.imresize(imread(initial), content_image.shape[:2])
# Initial guess is specified, but not noiseblend - no noise should be blended
if options.initial_noiseblend is None:
options.initial_noiseblend = 0.0
else:
# Neither inital, nor noiseblend is provided, falling back to random generated initial guess
if options.initial_noiseblend is None:
options.initial_noiseblend = 1.0
if options.initial_noiseblend < 1.0:
initial = content_image
if options.checkpoint_output and "%s" not in options.checkpoint_output:
parser.error("To save intermediate images, the checkpoint output "
"parameter must contain `%s` (e.g. `foo%s.jpg`)")
for iteration, image in stylize(
network=options.network,
initial=initial,
initial_noiseblend=options.initial_noiseblend,
content=content_image,
styles=style_images,
preserve_colors=options.preserve_colors,
iterations=options.iterations,
content_weight=options.content_weight,
content_weight_blend=options.content_weight_blend,
style_weight=options.style_weight,
style_layer_weight_exp=options.style_layer_weight_exp,
style_blend_weights=style_blend_weights,
tv_weight=options.tv_weight,
learning_rate=options.learning_rate,
beta1=options.beta1,
beta2=options.beta2,
epsilon=options.epsilon,
pooling=options.pooling,
print_iterations=options.print_iterations,
checkpoint_iterations=options.checkpoint_iterations
):
output_file = None
combined_rgb = image
if iteration is not None:
if options.checkpoint_output:
output_file = options.checkpoint_output % iteration
else:
output_file = options.output
if output_file:
imsave(output_file, combined_rgb)
def imread(path):
img = scipy.misc.imread(path).astype(np.float)
if len(img.shape) == 2:
# grayscale
img = np.dstack((img,img,img))
elif img.shape[2] == 4:
# PNG with alpha channel
img = img[:,:,:3]
return img
def imsave(path, img):
img = np.clip(img, 0, 255).astype(np.uint8)
Image.fromarray(img).save(path, quality=95)
if __name__ == '__main__':
main()