一、卷积神经网络简介
卷积神经网络(Convolutional Neural Network, CNN)最初是为了解决图像识别等问题设计的,当然其现在的应用不仅限于图像和视频,也可以用于时间序列信号,比如音频信号,文本数据等。早期的图像识别研究中,最大的挑战是如何组织特征,因为图像数据不像其他类型的数据那样可以通过人工理解来提取特征。我们需要借助SIFT、HoG等算法提取具有良好区分行的特征。在集合SVM机器学习算法进行图像识别。但是,他们的性能不是很好。而卷积神经网络提取的特征则可以达到更好的效果,同时它不需要将特征提取和分类训练两个过程分开。CNN作为一个深度学习架构被提出的最初诉求,是降低对图像数据预处理的要求,以及避免复杂的特征工程。CNN可以直接使用图像的原始像素作为输入,而不必先试用SIFT等算法提取特征,减轻了使用传统算法如SVM时必须要做的大量重复,繁琐的数据预处理工作。CNN的最大特点在于卷积的权值共享结构,可以大幅度减少神经网络的参数量,防止过拟合的同时又降低了神经网络模型的复杂度。
卷积神经网络的概念最早出自19世纪60年代科学家提出的感受野,根据对猫的视觉皮层的研究发现,每一个视觉神经元只会处理一小块区域的视觉图像,即感受野。20世纪80年代,日本科学家提出神经认知机的概念,可以算是卷积神经网络最初的实现原型。CNN也是首个成功地进行多层训练的网络结构,即LeCun的LeNet5.在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一个卷积操作只处理一小块图像,进行卷积变化后在传递到后面的网络,每一层卷积都会提取数据中最有效的特征。可以提取到图像最基础的特征。而后在进行组合和抽象形成更高级的特征。理论上对图像缩放,平移和旋转的不变性。卷积层的操作如下:
- 图像通过多个不同的卷积核的滤波,并加偏置,提取出局部特征,每个卷积核映射出一个新的2D图像。
- 将滤波结果输出,进行非线性激活函数处理。现在最常用的是ReLU,以前sigmoid函数比较多。
- 在对激活函数进行池化操作,目前常用最大池化,保留最显著的特征,提升模型畸变容忍能力。
这几个操作构成了最基本的卷积层,还有一个局部响应归一化(LRN)层,非常流行的还有Batch Normatization。
一个卷积层中可以有多个不同的卷积核,而每一个卷积核都对应一个滤波后映射出的新图像,同一个新图像中每一个像素都来自完全相同的卷积核,这就是卷积核的权值共享。作用是降低了模型的复杂度,减轻过拟合并减低计算量。图像在空间上是由组织结构的,每一个像素点在空间上和周围的像素点实际上是有紧密联系的,但是和太遥远的像素点就不一定有关系了。因此每一个神经元不需要接受全部的信息,只需要接受局部的像素点作为输入,而后将所有这些神经元收到的局部信息综合起来就可以得到全部的信息。这样我们就将全部链接改为局部连接。通过局部连接和权值共享,我们降低了模型的参数量,减少了计算量和过拟合的可能。因此,卷积的好处是,不管图像的尺寸如何,我们需要训练的权值数量只跟卷积核大小、卷积核数量有关,我们可以使用非常少的参数处理任意大小的图片。每一个卷积层提取的特征,在后面的层中都会抽象组合成更高阶的特征。而且多层抽象的卷积网络表达更强,效率更高,相比只使用一个隐含层提取全部高阶特征,反而可以节省大量参数。注意,网络的隐含节点并没有变,隐含节点的数量只与步长有关。
卷积神经网络的要点就是局部连接、权值共享和池化层中的降采样。其中,局部连接和权重共享降低了参数量,是训练复杂度大大下降,并减轻了过拟合。同时权值共享还赋予了卷积对平移的容忍性,而池化层降采样则进一步降低了输出参数量,并赋予模型对轻度形变的容忍性,提高了模型的泛化能力。
二、LeNet5简介
LeNet5诞生于1994年,是最早的深层卷积神经网络之一,推动了深度学习的发展。LeCun认为,可训练参数的卷积层是一种用少量参数在图像的多个位置上提取相似特征的有效方式,这和直接把每个像素作为多层神经网络的输入不同,像素不应该被使用在输入层,因为图像具有很强的空间相关性,而使用图像中的独立的像素直接作为输入则利用不到这些相关性。LeNet5的特性:
- 每个卷积层包含三个部分:卷积、池化和非线性激活函数
- 使用卷积提取空间特征
- 降采样的平均池化层
- 双曲正切(tanh)或S型(sigmoid)的激活函数
- MLP作为最后的分类器
- 层与层之间的稀疏连接减少计算复杂度
LeNet5的结构示例图:
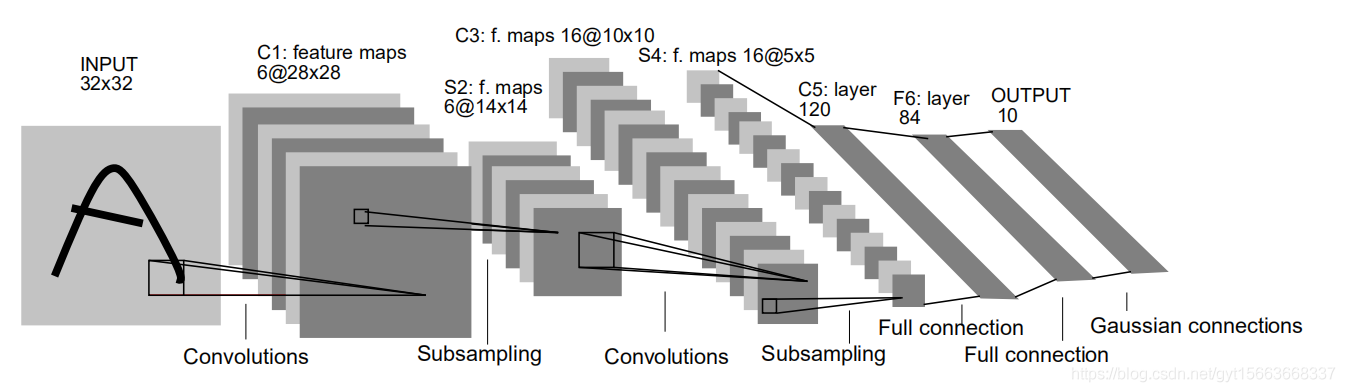
它的输入图像为的灰度值图像,后面有三个卷积层和一个全连接层和一个高斯连接层。第一个卷积层C1包含6个卷积核,卷积核尺寸为
,总共
个参数,后边是一个
的平均池化层S2来进行降采样。在之后是一个sigmoid激活函数用来非线性处理。而后是第二个卷积层C3,同样卷积核尺寸大小是
,使用了16个卷积核,对应16个特征图。注意这里的16个特征图不是全部连接到前面的6个特征图的输出的。有些只连接了其中几个特征图,这样增加了模型的多样性。下面的第二个池化层S4和第一个池化层S2一致。接下来的第三个卷积层C5有12个卷积核,卷积大小同样
,因为输入图像的大小刚好是
,因此构成了全连接,也可以算是全连接层。F6层是一个全连接层,拥有84个隐含节点,激活函数为sigmoid。最后一层有欧式径向基函数单元组成,它输出最后的分类结果。
三、TensorFlow实现简单的卷积网络
我们使用TensorFlow实现一个简单的卷积神经网络,使用的数据是MNIST。我们将构建两个卷积层加上一个全连接层的简单网络。网络构建的步骤为:
- 载入数据,使用的MNIST数据
- 定义权重和偏置初始化函数
- 定义卷积计算函数,池化计算函数
- 定义输入,输出,keep_prob占位符
- 第一层卷积
- 第二层卷积
- 全连接层,输出作为输入到softmax中得到结果
- 定义损失函数,开启优化器
- 开始训练,获取训练集的准确率
- 训练完之后,获取测试集的准确率。
# 载入数据集,创建默认的Session
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
# 载入输入
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# 创建默认session
sess = tf.InteractiveSession()
# 权重初始,打破完全对称
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
# 偏置初始,避免死亡节点
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# 卷积
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# 池化
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 定义输入和标签的占位符
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
x_image = tf.reshape(x, [-1, 28, 28, 1])
# 第一个卷积层
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# 第二个卷积层
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# 将h_poo2转化为1D,并连接全连接层。
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# 设置dropout
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 设置一个softmax层
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
# 定义损失函数
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv), reduction_indices=[1]))
# 定义优化器
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 定义评测标准的准确率
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 开始训练模型
tf.global_variables_initializer().run()
for i in range(20000):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, traing accuracy %g" % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
# 测试集上进行测试
print("test accuracy %g" % accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))结果:
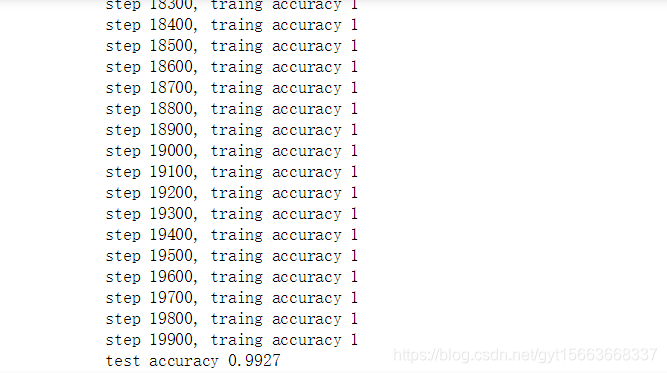
这个CNN模型可以得到的准确率为99.2%,基本上可以满足对手写数字识别准确率的要求。