目录
1.Win32的软硬件平台
(重点:实模式和保护模式的地址空间,内存寻址方式,应用程序的内存管理)
1.80X86系列处理器
自1978年6月Intel公司推出它的第一个16位微处理器8086以来,计算机技术就开始进入飞速发展时期。
8086芯片:采用了20条地址线,可以寻址的范围为2^20字节地址即2^10*2^10字节即1MB;
1985年,该公司推出32位的80386处理器。
80386:地址线扩展到32条,直接寻址能力达到4GB (2^32=4* 2^10 * 2^10 * 2^10);
2.80X86处理器的工作模式
80386处理器有三种工作模式:实模式、保护模式、虚拟86模式
1)实模式
实模式和虚拟86模式是为了和8086处理器兼容而设置的。实模式下,80386处理器就相当于一个快速的8086处理器。
80386处理器被复位或加电的时候以实模式启动。
80386处理器在实模式下的存储方式和8086是一样的,由段寄存器的内容*16当做基地址,加上段内的偏移地址形成最终的物理地址。(这个时候他的32位地址线只用了低20位)
补充:(加深理解)
https://www.cnblogs.com/chenwb89/p/operating_system_002.html

在实模式下,80386处理器不能对内存进行分页管理,所以指令寻址的地址就是内存中实际的物理地址。
在实模式下,所有的段都是可读、写和执行的。
实模式下,80386不支持优先级,所有的指令相当于工作在特权级(优先级0),所以它可以执行所有的特权指令,包括读写控制寄存器CR0等。
实际上,80386就是通过在实模式下初始化控制寄存器、GDTR、LSTR、TR等管理寄存器以及页表,然后通过加载CR0使其中的保护模式使能位置位(使能位:就是使功能开启关闭的开关。一般用一位0/1来表示。)而进入保护模式的。
实模式下的中断处理方式和8086处理器相同,也使用中断向量表来定位中断服务程序地址。中断向量表的结构也和8086处理器一样,每4字节组成一个中断向量表,其中包括两个字节的段地址和两个字节的偏移地址。
实模式的80386处理器比8086有什么进步呢?
答:可以使用80386的32位寄存器,用32位的寄存器进行编程,使计算机程序更加简捷,加快执行速度。
很多80386的新增指令使得原来不很方便的操作得以简化。如pushad 和popad指令可以一次把所有8个通用寄存器的值压入或从堆栈中弹出。
2)保护模式
保护模式是80386处理器的主要工作模式。 在此方式下,80386可以寻址4GB的地址空间。同时,保护模式提供了80386先进的 多任务、内存分页管理和优先级保护等机制。
保护模式出现的原因是:保护进程地址空间。
当80386工作在保护模式下的时候,它的所有功能都是可用的。这时80386所有的32根地址线都可供寻址,物理寻址空间高达4GB。
在保护模式下,支持内存分页机制,提供了对虚拟内存的良好支持。
虽然与8086可寻址的1MB地址空间相比,80386可寻址的物理地址空间可谓很大,但实际的微机系统极少安装如此大的物理内存。
所以为了运行大型程序和真正实现多任务,虚拟内存是一种必须的技术。
保护模式下80386支持多任务,可以依靠硬件仅在一条指令中实现任务切换。任务环境的保护工作是由处理器自动完成的。在保护模式下,80386处理器还支持优先级机制,不同程序可以运行在不同的优先级上。
优先级分为4个级别(0级到3级),操作系统运行在高的优先级0上,应用程序则运行在比较低的级别上:配合良好的检查机制后,既可以在任务间实现数据的安全共享也可以很好地隔离各个任务。
从实模式切换到保护模式是通过修改控制寄存器CR0的控制位PE(位0)来实现的。在这之前还需要建立保护模式必须的一些数据表,如全局描述符表GDT和中断描述符表IDT等。
DOS操作系统运行于实模式下,而Windows操作系统运行于保护模式下。
补充:(加深理解)
https://www.cnblogs.com/chenwb89/p/operating_system_002.html

3)虚拟86模式
为了在保护模式下继续提供和8086处理器的兼容,80386又设计了一种虚拟86模式,以便可以在保护模式的多任务条件下,有的任务运行32位程序,有的任务运行MS-DOS程序(16位微软磁盘操作系统)。
虚拟86模式以保护模式为基础,以任务形式在保护模式上执行的,在80386上可以同时支持由多个真正的80386任务和虚拟86模式构成的任务。在虚拟86模式下。80386支持任务切换和内存分页。
在虚拟86模式下,同样支持任务切换、内存分页管理和优先级,但内存的寻址方式和8086相同,也是可以寻址1MB空间。
虚拟86模式采用和8086一样的寻址方式,即用 段寄存器*16+偏移地址=线性地址,寻址空间为1MB。但显然多个虚拟86任务不能同时使用同一位置的1MB地址空间,否则会引起冲突。操作系统利用分页机制将不同的86任务的地址空间映射到不同的物理地址上去,这样每个虚拟86任务看起来都认为自己在使用0~1MB的地址空间。
4)三种模式的转换

5)三种模式的对比

2.Windows内存管理
1)实模式下的寻址方式
实模式下的地址:由段地址和偏移地址两部分组成。段地址放在16位段寄存器中,然后在指令中使用16位的偏移地址寻址。处理器换算时,先将段地址乘以10h,得到段在物理内存中的起始地址;然后再加上16位的偏移地址得到实际的物理地址。
如xxxx:yyyy格式的虚拟地址在内存中的实际位置是xxxx *10h+yyyy。
即:![]()
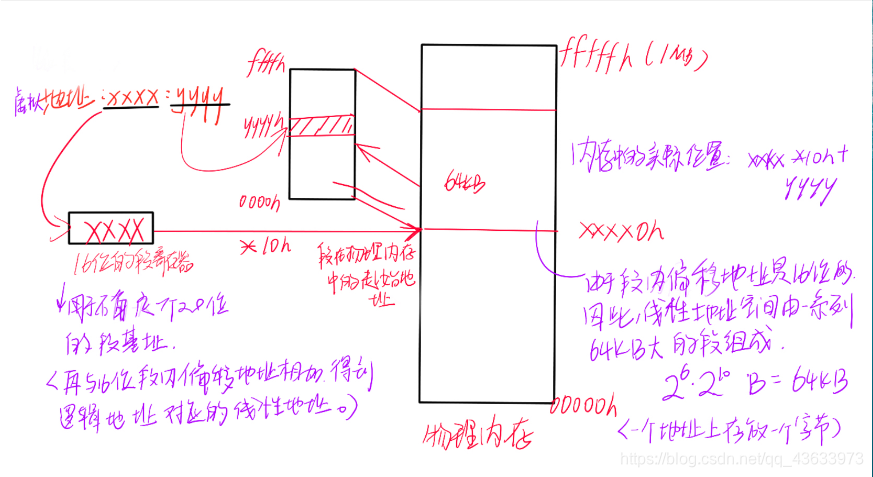
注意:实模式20根地址线,寻址空间是1M,不支持内存分页,线性地址即为物理地址。
由于段内偏移地址是16位的,因此,线性地址空间由一系列64KB大的段组成(一个地址上存放一个字节)。
产生一个疑问:关于为什么在上面实地址模式要分段?
https://blog.csdn.net/yafeixi/article/details/52189528
8086CPU有20根地址线,最大可寻址内存空间为1MB。而8086的寄存器只有16位,指令指针(IP)和变址寄存器(SI、DI)也是16位的。
用16位的地址寻址1MB空间是不可能的。所以就要把内存分段,也就是把1MB空间分为若干个段,每段不超过64KB,在8086中设置4个16位的段寄存器,用于管理4种段:CS是代码段,DS是数据段,SS是堆栈段,ES是附加段。
把内存分段后,每一个段就有一个段基址,段寄存器保存的就是这个段基址的高16位,
这个16位的地址左移四位(后面加上4个0)就可构成20位的段基址。
2)保护模式下的内存寻址
当80386处理器工作在保护模式和虚拟8086模式的时候,可以使用全部32根地址线访问4GB大的内存。段地址加偏移地址的计算方法显然无法覆盖这么大的范围。
因为80386所有的通用寄存器都是32位的,2^32相当于4G,所以用任何一个通用寄存器来间接寻址,不必分段就已经可以访问到所有的内存地址。
那是不是说,在保护模式下,段寄存器就不再有用了呢?答案不是的。
实际上段寄存器更有用了。
虽然在寻址上不再有分段的限制问题,但在保护模式下,一个地址空间是否可以被写入,可以被多少优先级的代码写入,是不是允许执行等涉及保护的问题就出来了。
要解决这些问题,必须对一个地址空间定义一些安全上的属性。段寄存器这时就派上了用途。
但是涉及属性和保护模式下段的其他参数,要表示的信息太多了,要用64位长的数据才能表示。
我们把这64位的属性数据叫做段描述符。
80386的段寄存器是16位的,无法放下保护模式下64位的段描述符。那么如何解决这个问题?
解决办法就是把所有的段描述符顺序放在内存中指定的位置,组成一个段描述符表(Descriptor Table)。
而段寄存器中的16位用来做索引信息,指定这个段的属性用段描述符表的第几个描述符来表示。
这个时候,段寄存器中的信息就不再是段地址了,而是段选择器(Segment Selector)。
可以通过它在描述符表中“选择”一个项目以得到段的全部信息。
既然这样,那么段描述符表放在哪里呢?
80386中引入了两个新的寄存器来管理段描述符表。
一个是 48位 全局描述符表寄存器 GDTR,一个是 16位 的局部描述符表寄存器LDTR。
那么,为什么要有两个描述符表呢?
GDTR 指向的描述符表为全局描述符表 GDT(Global Descriptor Table)。它包含系统中所有任务都可用的段描述符,通常包含描述操作系统所使用的代码段、数据段、堆栈段、堆栈段的描述符、各任务的LDT段等。
全局描述符表只有一个。
LDTR 则指向局部描述符表LDT(Local Descriptor Table)。80386处理器 设计成 每个任务都有一个独立的LDT。 它包含有每个任务的私有的代码段、数据段和堆栈段的描述符,也包含该任务所使用的一些门描述符,如任务门和调用门描述符等。
不同任务的局部描述符表组成不同的内存段,描述这些内存段的描述符当做系统描述符放在全局描述符表中。
和GDTR直接指向内存地址不同,LDTR和CS、DS等段选择器一样只存放索引值,指向局部描述符表中内存段对应的描述符在全局描述符表 中的位置。
随着任务的切换,只要改变LDTR的值,系统当前的局部描述符表LDT也随之切换,这样便于各任务之间数据的隔离。
但GDT并不随着任务的切换而切换。
那么,既然有两个表,段选择器中的索引值应该对应哪个表中的描述符呢?
实际上,16位的段选择器中只有高13位表示索引值,剩下的3个数据位中,第0,1位表示程序的当前优先级RPL;第2位TI位用来表示在段描述符表的位置;
TI=0,表示在GDT中
TI=1,表示在LDT中

LDT

ps:每个任务都有一个LDTR,所以LDTR的索引值对应不同的LDT描述符
···关于实模式和保护模式的分段?
一个是早期实模式下,寄存器16位,地址线20位。为了用16位的寄存器寻址20位的地址,引入了段(segment)的概念,所有的段都在一个地址空间。第二个是保护模式下,段(segmentation)强调的是分割,用来把内存分成不同的地址空间,每个段一个空间,而后通过CPU的MMU(MMU是Memory Management Unit的缩写,中文名是内存管理单元,有时称作分页内存管理单元)转换成实际物理地址。由于程序运行在不同的段里,根本上保护了CPU保护模式下的各个不相关的代码,所谓进程或者作业。
3)内存分页机制
在实模式下寻址的时候,“段寄存器+偏移地址”经过转换计算以后得到的地址是“物理地址”,也就是在物理内存中的实际地址。而保护模式下,“段选择器+偏移地址”转换后的地址被称为“线性地址”而不是“物理地址”。那么,线性地址就是物理地址吗?
答案可能是也可能不是,
这取决于80386的内存分页机制是否被使用。
在单任务的DOS系统中,一个应用程序可以使用所有的空闲内存。程序退出后,操作系统回收所有的碎片内存并且合并成一个大块内存继续供下一个程序使用。内存合并过程中的一个极端情况是当系统中有多个TSR程序时,早装入内存的TSR被卸载后,后装入的TSR会留在内存的中间部位,把空闲内存隔成两个区域。这时应用程序使用的最大内存块只能是这两块内存中较大的一块,无法将它们合并使用。
注:
TSR
终止并驻留 (terminate-and-stay-resident) 的缩写。tsr 程序采用“后台”方式运行。大多数 tsr 程序均有一个预定义的组合键(有时称作“热键”),使您可以在运行其它程序时启用 tsr 程序接口。运行 tsr 程序后,您可以返回其它应用程序,并将 tsr 程序保存在内存中以备后用。
功能:执行后,进入内存,但什么也不做。当你按下其事先设定的激活键后,TSR程序调出,并执行相关功能。
大多是dos下的,比如bios,显卡驱动,dos鼠标驱动,输入法,高端内存分配等等
对于一个多任务的操作系统,内存的碎片化是不能容忍的。否则,经过一段时间后,即使空闲内存的总和很大,也可能出现任何一片内存都小到无法装入执行程序的地步。所以多任务操作系统中碎片内存的合并是个很重要的问题。
80386处理器的分页机制可以很好的解决这个问题。
80386处理器把4KB大小的一块内存当做一“页”内存,每页内存可以根据“页目录”和“页表”,随意映射到不同的线性地址上。这样,就可以将物理地址不连续的内存映射连到一起,在线性地址上视为连续。
在80386处理器中,除了和CR3寄存器(指定当前页目录的地址)相关的指令使用的是物理地址外,其他所有指令都是用线性地址寻址的。
是否启用内存分页机制是由80386处理器新增的CR0寄存器中的位31(PG位)决定的。
如果PG=0,则分页机制不启用,这时所有指令寻址的地址(线性地址)就是系统中实际的物理地址。
当PG=1时,80386处理器进入内存分页管理模式,所有的线性地址要经过页表的映射才得到最后的物理地址。

内存分页管理只能在保护模式下才可以实现,实模式不支持分页机制。但不管在哪种模式下,所有的寻址指令使用的都是线性地址,程序不用关心数据最后究竟存放在物理内存的哪个地方。
页表规定的不仅是地址的映射,同时还规定了页的访问属性,如是否可写、可读、可执行等。比如把代码所在的内存页设置为可读与可执行,那么权限不够的代码向它写数据就会引发保护异常。利用这个机制可以在硬件层次上支持虚拟内存的实现。
回顾:
☆1.保护模式支持内存分段模型。保护模式与实模式的主要区别在于:段寄存器中存放的不再是段基址,而是描述符表的索引。保护模式下对内存的分段是强制的,分页是可选的。
☆2.保护模式下内存寻址时,16位的段寄存器存放的不是段基地址,而是描述符表的索引地址,段内偏移地址长度32位;段描述符是64位,因为需要包含地址空间定义的一些安全属性;
☆3.段选择器高13位表示索引,第0,1位表示段选择器的请求特权级,第2位TI表示段描述符的位置:TI=0表示在GDT中,TI=1表示在LDT中。
☆4.段描述符中的32位线性基地址与32位段内偏移地址相加,得到线性地址,如果不分页则线性地址与物理地址直接对应。
☆5.保护模式下,线性地址空间大小为4G,32位地址线。
☆☆☆6.一级页表的映射: 32位虚拟内存地址=20位页表索引+12位页内偏移
因为每一页的大小是4K=2^12,所以页内偏移的位数需要12位。那么前20位就是页索引部分。
那么页映射表中的条目数是2^32/2^12=2^20 = 1M,即表元素的个数为1M。我们用4个字节来存储每个元素,存储这个映射表就需要的是4M的内存(即每次创建一个进程,都需要先在物理内存中占用一个4M的映射表)。
————————————————
因为页表中每个条目是4字节,现在的32位操作系统虚拟地址空间是2^32,假设每页分为4k,也需(2^32/(4*2^10))*4=4M的空间,为每个进程建立一个4M的页表并不明智。☆☆☆二级页表的映射方式: 32位虚拟内存地址=10位页目录索引+10位页表索引+12位页内偏移
即在一级页表中,把20位的页表索引再次切分,为10位页目录索引和10位的页表索引。即一个虚拟空间先对应一个2^10 = 1024个元素的页目录,每个页目录再对应一个2^10=1024个元素的页表。每个页表的大小即为一个虚拟页大小为4K。即总共4GB的虚拟内存。
CPU把虚拟地址转换成物理地址:一个虚拟地址,大小4个字节(32bit),分为3个部分:
第22位到第31位这10位(最高10位)是页目录中的索引,
第12位到第21位这10位是页表中的索引,第0位到第11位这12位(低12位)是页内偏移。
一个一级页表有1024项,虚拟地址最高的10bit刚好可以索引1024项(2的10次方等于1024)。一个二级页表也有1024项,虚拟地址中间部分的10bit,刚好索引1024项。
虚拟地址最低的12bit(2的12次方等于4096),作为页内偏移,刚好可以索引4KB,也就是一个物理页中的每个字节。
☆7.使用内存分页的好处是什么?
答:可以将物理地址不连续的内存映射到一起,在线性地址上视为连续,解决内存的碎片化。利用分页机制可以实现虚拟内存。


4)Windows的内存安排
Windows系统一般在硬盘上建立大小为物理内存两倍左右的交换文件(文件名在Windows 9x下为Win386.swp.Windows NT下为PageFile.sys)用作虚拟内存。
资料扩展:
电脑硬盘是计算机最主要的存储设备。硬盘(港台称之为硬碟,英文名:Hard Disk Drive, 简称HDD 全名温彻斯特式硬盘)由一个或者多个铝制或者玻璃制的碟片组成。这些碟片外覆盖有铁磁性材料。
绝大多数硬盘都是固定硬盘,被永久性地密封固定在硬盘驱动器中。早期的硬盘存储媒介是可替换的,不过今日典型的硬盘是固定的存储媒介,被封在硬盘里 (除了一个过滤孔,用来平衡空气压力)。随着发展,可移动硬盘也出现了,而且越来越普及,种类也越来越多.大多数微机上安装的硬盘,由于都采用温切斯特(winchester)技术而被称之为“温切斯特硬盘”,或简称“温盘”。
虚拟内存就是虚拟的,在物理内存不够用的时候,暂时借用硬盘的空间,当做一部分内存使用,这部分空间就叫虚拟内存。
当然虚拟内存由于使用的是硬盘,所以速度只有物理内存的几百分之一到左右。
利用80386处理器的分页机制,交换文件可以很方便地作为物理内存使用。只需在真正访问到的时候将硬盘文件的内容读入物理内存,然后重新将线性地址映射到这块物理内存就可以了。
同样道理,被执行的可执行文件也不必真正装入内存,只要在页表中建立映射关系,以后真正运行到某处代码的时候再将它调入内存。
如果把虚拟内存管理暂时先视为物理内存的一部分,从物理内存的层次看,Windows操作系统和DOS系统一样,也是所有的内容共享内存,比如操作系统使用的代码和数据(GDT,LDT与页表等),当前执行中的所有程序的代码和数据以及这些程序调用的DLL代码和数据等。如图左上角所示。

但是从应用程序代码的层次看,也就是说从分页映射后的线性地址的层次看。
内存的安排却不是这个样子。
因为Windows是一个分时的多任务操作系统,CPU时间被分成一个个的时间片后分配给不同程序轮流使用,在一个程序的时间片中,和这个程序执行无关的东西(如其他程序的代码和数据)并不需要映射到线性地址中去。
如上图所示,Windows操作系统通过切换不同的页表内容,让线性地址在不同的时间片中映射不同的内容。图中右边是Windows 98操作系统在单个时间片中的线性地址安排。
在物理内存中,操作系统和系统DLL的代码需要供给每个应用程序调用,所以在所有的时间片中都必须被映射;用户程序只在自己所属的时间片内被映射;而用户DLL则有选择的被映射。
注:( )
)
假设程序A和程序C都要用到xxx.dll ,那么物理内存中xxx.dll 的代码在图中的时间片1和n中被映射,其他的时间片就不需要映射。
由此引出Win32编程中的几个重要的概念
(1)每个应用程序都有自己的4GB寻址空间,用于存放操作系统、系统DLL、用户的DLL代码,应用程序代码、数据等。
(2)不同应用程序的线性地址空间是隔离的。在某个程序所属的时间片中,其他程序的代码和数据没有被映射到可寻址的线性地址中,所以是不可访问的。
(3)DLL程序没有自己的私有空间,它们总被映射到其他应用程序的地址空间中,当做其他应用程序的一部分运行。原因很简单,如果它不和其他程序同属一个地址空间,应用程序该如何调用它呢?
3.Windows的特权保护
(重点掌握:实模式和保护模式的中断与异常处理)
1.80386的中断和异常
中断指当程序执行过程中有更重要的事情需要实时处理时(如串口中有数据到达,不及时处理 数据会丢失,串行控制器就提交一个中断信号给处理器要求处理),硬件通过中断控制器通知处理器。处理器暂时挂起当前运行的程序,转移到中断处理程序中;当中断处理程序处理完毕后,通过iret指令回到原先被打断的程序中继续执行。
异常 指 指令执行中发生不可忽略的错误时(如遇到无效的指令编码,除法指令除零等),处理器用和终端处理相同的操作方法挂起当前运行的程序转移到异常处理程序中。异常处理程序决定在修正错误后是否回到原来的地方继续执行。
更为DOS汇编程序猿熟悉的“中断”指的是用int n指令直接转移到中断向量n指定的中断处理程序中执行。严格的讲,int n指令应该算“自陷”而不是“中断”。因为这时并不是程序被急需解决的事情打断。而是自己要求停止执行并转移到中断处理程序中去。
不管中断、异常还是自陷,虽然它们产生的原因不同,但处理的过程是类似的,都通过中断向量表里存放的入口地址转移到服务程序,都由CPU自动在堆栈中保护断点地址,最后也都可以用iret指令返回指令被中断的地方。
(1)80386实模式下的中断和异常处理
实模式下的中断和异常服务程序地址存放在中断向量表中。中断向量表位于物理内存00000h开始的400h字节中,共支持100h个中断向量:每个中断向量是一个xxxx:yyyy格式的地址,占用4字节。
当发生n号异常或n号中断,或者执行到 int n指令 的时候,
CPU首先到 n*4 的地方取出服务程序的地址aaaa:bbbb ;
然后将标志寄存器、中断时的 CS和IP压入栈 ,接着转移到aaaa:bbbb处执行;
在服务程序最后遇到 iret 的时候,CPU从堆栈中恢复标志寄存器,然后取出CS和IP并返回。

(2)80386保护模式下的中断和异常处理
在保护模式下,中断或异常处理往往从用户代码切换到操作系统代码中执行。由于保护模式下的代码有优先级之分,因此出现了从优先级低的应用程序转移到优先级高的系统代码中的问题,如果优先级低的代码能够任意调用优先级高的代码,就相当于拥有了高优先级代码的权限。
为了使高优先级的代码能够安全地被低优先级的代码调用,保护模式下 增加了“门”的概念 。
“门”指向某个优先级高的程序所规定的入口点,所有优先级低的程序调用优先级高的程序只能通过门重定向,进入门所规定的入口点。
这样可以避免低级别的程序代码从任意位置进入优先级高的应用程序的问题。
保护模式下的中断和异常等服务程序也要从“门”进入。
80386的门分为 中断门、自陷门和任务门 几种。
在保护模式下要表示一个中断或异常服务程序的信息需要8个字节(64bit),包括门的种类以及xxxx:yyyyyyyy格式的入口地址等。这组信息叫做“中断描述符”。
这样,中断向量表就无法采用和实模式下同样的4字节一组的格式。
保护模式下把所有的中断描述符放在一起组成“中断描述符表”IDT(Interrupt Descriptor Table)。
IDT不再放在固定的地址00000h处,而是采用可编程设置的方式,支持的中断数量也可以设置。
为此80386处理器引入了一个新的48位寄存器IDTR。IDTR的高32位指定了IDT在内存中的基址(线性地址),低16位制定了IDT的长度,相当于制定了可以支持的中断数量。

如图所示,保护模式下发生异常或中断时,
处理器先根据 IDTR寄存器得到中断描述符的地址,
然后取出 n号中断/异常的门描述符,
再 从描述符中得到中断服务程序的地址 xxxx:yyyyyyyy,
经过地址转换后得到服务程序的32位线性地址并转移后执行。
由于保护模式下用 中断门 可以从低优先级的代码调用高优先级的代码,所以不能让用户程序写中断描述符表,否则会引发安全问题。
在Windows中,操作系统使用 动态链接库 来代替中断服务程序提供系统功能,所以Win32汇编中int指令也就失去了存在的意义。这就是在Win32汇编源代码中看不到int指令的原因。其实那些 调用API的指令 就相当于在DOS系统中使用int指令来完成系统功能。
中断描述符表在内存中的位置可变吗?支持的中断数量可设置吗?用户程序可以直接构造或者修改中断描述符表吗?
答:IDT不再放在固定的地址00000h处,而是采用可编程设置的方式,支持的中断数量也可以设置。
为此80386处理器引入了一个新的48位寄存器IDTR。IDTR的高32位指定了IDT在内存中的基址(线性地址),低16位制定了IDT的长度,相当于制定了可以支持的中断数量。
由于保护模式下用中断门可以从低优先级的代码调用高优先级的代码,所以不能让用户程序写中断描述符表,否则会引发安全问题。
2.80386的保护机制
80386采用保护机制主要为了检查和防止低级别代码的越权操作,如访问不该访问的数据、端口以及调用高优先级的代码等。保护机制主要由下列几方面:
段的类型检查: 段的类型由段描述符指定,主要属性有是否可执行,是否可读写。
CS/DS/SS等段选择器是否能装入某种类型的段描述符是有限制的。
例如,不可执行的段不能装入CS;不可写的段不能装入SS。
访问数据时的级别检查: 低优先级的代码不能访问高优先级的数据段。
80386 段描述符GDT中的DPL域(描述符优先级)指定了这个段可以被访问的最低优先级;
段选择器中的RPL域(请求优先级)指定了当前执行代码的优先级;
DPL≥RPL,该段才能访问,否则产生保护异常;
注:RPL(Require Privilege Level):请求特权级,与DPL、CPL的意义相同,用于特权级检查,一般情况下选择子的RPL<=DPL
(https://blog.csdn.net/wenwushq/article/details/79805779)
GDT就是一个数组,每一个元素就是一个描述符,多个组合一起就构成了全局描述符表。而每一个描述符共64位,包含了以下的这些信息:段基址、段长度、属性。原来的段寄存器,比如CS,DS等存的值则不是段偏移了,而是GDT的索引,通过该索引就可以找到对应的描述符。

对比段寄存器,段寄存器中保存的是索引,那么段寄存器中的数据又是什么样呢?

4.Windows 窗口程序编写。
(1)NASM
https://www.xuebuyuan.com/2167209.html
1)"EXTERN'': 从其他的模块中导入符中。
''EXTERN''跟MASM的操作符''EXTRN'',C的关键字''extern''极其相似:它被用来声明一个符号,这个符号在当前模块中没有被定义,但被认为是定义在其他的模块中,但需要在当前模块中对它引用。不是所有的目标文件格式都支持外部变量的:''bin''文件格式就不行。
''EXTERN''操作符可以带有任意多个参数,每一个都是一个符号名:
extern _printf
extern _sscanf,_fscanf
你可以把同一个变量作为''EXTERN''声明多次:NASM会忽略掉第二次和后来声明的,只采
用第一个。但你不能象声明其他变量一样声明一个''EXTERN''变量。2)"GLOBAL'': 把符号导出到其他模块中。
''GLOBAL''是''EXTERN''的对立面:如果一个模块声明一个''EXTERN''的符号,然后引用它,然后为了防止链接错误,另外某一个模块必须确实定义了该符号,然后把它声明为''GLOBAL'',有些汇编器使用名字''PUBLIC''。
''GLOBAL''操作符所作用的符号必须在''GLOBAL''之后进行定义。
''GLOBAL''使用跟''EXTERN''相同的语法,除了它所引用的符号必须在同一样模块中已经被
定义过了,比如:
global _main
_main:
; some code
就像''EXTERN''一样,''GLOBAL''允许目标格式文件通过冒号定义它们自己的扩展。比如
''elf''目标文件格式可以让你指定全局数据是函数或数据。
global hashlookup:function, hashtable:data
就象''EXTERN''一样,原始形式的''GLOBAL''跟用户级的形式不同,仅能一次带有一个参
数
(之前博客里写过具体的安装执行过程,这里简单复习下)
代码:
;---ASM 20121222 Win32 MessageBox
extern MessageBoxA
section .text
global main
main:
push dword 3 ; uType = MB_YESNOCANCEL
push dword title ; LPCSTR lpCaption
push dword text ; LPCSTR lpText
push dword 0 ; hWnd = HWND_DESKTOP
call MessageBoxA
ret
section .date
title: db '2019-12-22', 0
text: db 'hi,我是PlusCat!2019.12.22', 0使用NASM

命令如下:
nasm -fwin32 test.asm
alink -oPE test win32.lib -entry main
生成test.exe文件,运行效果如图:

用OllyDbg打开test.exe

左上方的反汇编窗口:显示刚刚我们编写的汇编指令。
左下方的内存窗口:显示section .data之后存放的数据 (不知道为啥刚载入不是显示的.data段的数据),下面我直接跳过去,这个地址(是书上看到的,我也不知道为啥在这,之后慢慢查漏补缺吧,网上没找到具体原因)

当逐一执行这些指令时,每执行一次push指令,右下方的栈窗口中就会显示出刚刚入栈的值,最后,当执行call MessageBoxA时,屏幕上就会显示出刚刚入栈的值,如图:

(2)MASM

看这个例子,分析代码:
1.段的概念
.386 语句 是汇编语言的伪指令,用于告诉编译器在本程序中使用指令集。Win32环境工作在80386及以上的处理器中,所以这一句.386是必不可少的。
.model语句 用来定义程序工作的模式。
flat:对Win32程序来说,只有一种内存模式,即flat(平坦)模式,意思是内存是很“平坦”地从0延伸到4GB,在没有64KB段大小的限制。即代码和数据段使用同一个4GB段。好处是:所有的4GB空间用32位的寄存器全部都能访问到了,不必在头脑中随时记着当前使用的是哪个数据段,这就是“平坦”内存模式带来的好处。
CS/DS/ES/SS段全部使用平坦模式
stdcall: 指定的语言模式,即子程序的调用方式,指出了调用子程序或Win32 API时参数的传递次序和堆栈平衡方法。Windows的API调用使用的是stdcall格式,所以在Wn32汇编中没有选择,必须在.model中加上stdcall参数。
potion 语句 这里定义的是程序中的变量和子程序名是否对大小写敏感,由于Win32的API名称区分大小写,所以这个选项必须指定,否则调用API的时候会有问题。
2.数据段
.data , .data? , 和 .const 定义的是数据段,分别对应不同方式的数据定义,在最后生成的可执行文件中也分别放在不同的节区(Section)中。程序中的数据定义一般可以归纳为3类。
第一类是
可读可写的已定义变量。这些数据在源程序中已经被定义了初始值,而且在程序的执行中有可能被更改,如一些标志等,这些数据必须定义在.data段中, .data段是已初始化数据段,其中定义的数据是可读可写的,在程序装入完成的时候,这些值就已经在内存中了,.data段一般存放在可执行文件的_DATA节区内。
第二类是
可读可写的未定义变量。这些变量一般是当做缓冲区或者在程序执行后才开始使用的,这些数据可以定义在.data段中,也可以定义在.data?段中,但一般把它放到.data?段中。
虽然定义在这两种段中都可以正常使用,但定义在.data?段中不会增大.exe文件的大小。举例说明,如果要用到一个100KB的缓冲区,可以用下面的语句定义:
szBuffer db 100*1024 dup(?) // 共占100*1024字节
(全局变量的定义:变量名 类型 重复数量 dup (初始值1,初始值2,······)
(?应该代表的是未初始化的意思)这个语句如果放在.data段中,编译器认为这些数据在程序装入时就必须有效,所以它在生成可执行文件的时候保留了所有的100KB的内容,即使他们全是0。假设程序其他部分的大小是50kb,那么最后的.exe文件就会是150KB的大小,如果缓冲区定义为1MB,那么.exe文件就会是1050KB。
.data?段则不同,其中的内容编译器会认为程序在开始执行后才会用到,所以在生成可执行文件的时候只保留了大小的信息,不会为它浪费磁盘空间。
在与上面同样的情况下,即使缓冲区定义为1MB,可执行文件同样只有50KB。总之,.data?段是未初始化数据段,其中的数据也是可读可写的,但在可执行文件中不占空间, .data?段在可执行文件中一般放在_BBS节区中。
第三类是
数据是一些常量。如一些要显示的字符串信息,它们在程序装入的时候也已经有效,但在整个执行过程中不需要修改,这些数据可以放在 .const段中, .const段是常量段,它是可读不可写的。
为了方便起见,在小程序中常常把常量一起定义到.data段中,而不另外定义一个.const段。
在程序中如果不小心用了对.const段中的数据做写操作的指令,会引起保护错误,Windows会显示一个提示框并结束程序。
不过不怕程序可读性不佳的话,把.const段中定义的东西混到 .code段中去也可以正常使用,因为.code段也是可读的。
3.代码段
.code段是代码段,所有的指令都必须写在代码段中,在可执行文件中,代码段一般是放在_TEXT节区中的。
Win32环境中的数据段是不可执行的,只有代码段有可执行的属性。对于工作在特权级3的应用程序来说, .code段是不可写的。
在Windows 95下,在特权级0下运行的程序对所有的段都有读写的权利,包括代码段。
另外在优先级3下运行的程序也不一定不能写代码,代码段的属性是由可执行文件PE头部中的属性位决定的,通过编辑磁盘上的.exe文件,把代码段的属性位改为可写,那么在程序中就允许修改自己的代码段。
一个典型的应用就是一些针对可执行文件的压缩软件和加壳软件,如UPX和PeCompact等,这些软件依靠把代码进行变换来达到解压缩或解密的目的,被处理过的可执行文件在执行时需要由解压代码来将代码段解压缩,这就需要写代码段,所以这些软件对可执行文件代码段的属性预先做了修改。
4.堆栈段
在程序中不必定义堆栈段,系统会自动分配堆栈空间。唯一值得一提的是,堆栈段的内存属性是可读写并且是可执行的,这样靠动态修改代码的反跟踪模块可以拷贝到堆栈中去边修改边执行。
一些病毒或者黑客工具用到的缓冲区溢出技术也用到了这个特征。
3.Windows API
(window32 API的用途及相关的DLL,汇编里API的调用方法,返回值放哪里)
1.API是什么
☆☆☆API(应用程序接口)是windows操作系统提供的一套编程函数库,提供应用程序运行所需的窗口管理,图形设备接口、内存管理等各项服务功能。这些函数采用DLL实现。
DLL是一种Window的可执行文件,采用的是和.exe文件同样的PE格式,在PE文件头的导出表中,以字符串的形式指出了这个DLL能提供的函数列表。应用程序使用字符串类型的函数名指定要调用的函数。
应用程序在使用的时候由Windows自动装入DLL程序并调用相应的函数。
实际上,Win32的基础就是由DLL组成的。Win32 API的核心由3个DLL组成。如下:
☆KERNEL 32.DLL——系统服务功能。任务管理,动态链接、内存管理等
☆GDI32.DLL——图形设备接口。利用显卡驱动程序显示文本、图像等
☆USER32.DLL——用户服务接口。建立窗口、传送消息等
2.调用API
Win32 API是用堆栈来传递参数的,
调用者把参数一个个压入堆栈,
DLL中的函数程序再从堆栈中取出参数处理,
并在返回之前将堆栈中已经无用的参数丢弃。

上述函数声明说明了MessageBox有4个参数,它们分别是:
HWND类型的窗口句柄(hWnd)
LPCTSTR类型的要显示的字符串地址(lpText)
标题字符串地址(lpCaption)
UINT类型的消息框类型(uType)
这些数据类型看起来很复杂,但对于Win32汇编语言来说,都是dword ,之所以定义为不同的模样,是为了说明其用途。
Win 32API调用中要把参数放入堆栈,顺序是最后一个参数最先进栈。

在源程序编译链接成可执行文件后,
call MessageBox语句中的MessageBox会被换成一个地址,指向可执行文件中的导入表,
导入表中指向MessageBox函数的实际地址会在程序装入内存的时候,根据User32.dll在内存中的位置由Windows系统动态填入。
3.API函数返回值
有的API函数有返回值,如MessageBox定义的返回值是int类型的数,返回值的类型对汇编程序来说也只有dword一种类型,它永远放在eax中。
如果要返回的内容不是一个eax所能容纳的,Win32 API采用的方法一般是eax中返回一个指向返回数据的指针,或者在调用参数中提供一个缓冲区地址,干脆把数据直接返回到缓冲区中去。
4.函数的声明
在Win32环境中,和字符串相关的API共有两类,分别对应两个字符集:
一类是处理ANSI字符集的,另一类是处理Unicode字符集的。
前一类函数名字尾部带一个“A”字符,处理Unicode的则带一个“W”字符。
我们比较熟悉的ANSI字符串是以NULL结尾的一串字符数组,每一个ANSI字符占一个字节宽。
对于欧洲语言体系,ANSI字符集已经足够了,但对于有成千上万个不同字符的几种东方语言体系来说,Unicode字符集更有用。每一个Unicode字符占两个字节的宽度,这样一来就可以同时定义65536个不同的字符了。
MessageBox有两个定义。
MessageBoxA
MessageBoxW
但User32.dll中只有MessageBoxA和MessageBoxW,why源程序中仍可以用MessageBox?
这是因为在程序的头文件user32.inc中有一句:
![]()
5.include语句
对于所有要用到的API函数,在程序的开始部分都必须预先声明,但这个步骤显然是比较麻烦的,为了简化操作,可以采用各种语言通用的解决办法。就是把所有的声明预先放在一个文件中,在用到的时候再用include语句包含进来。
如一个程序用到了两个API函数:MessageBox和ExitProcess,他们分别在User32.dll和Kernel32.dll中。
在MASM32工具包中已经包括了所有DLL的API函数声明列表,每个DLL对应<DLL 名.inc>文件,在源程序中只要使用include语句包含进来就可以了。
include <user32.inc>
include <kernel32.inc>
编译器对include语句的处理仅是简单地把这一行用指定的文件内容替换掉而已。
6.includelib语句
在Win32汇编中使用API函数,程序必须知道调用的API函数存在于哪个DLL中,否则,操作系统必须搜索系统中存在的所有DLL,并且无法处理不同DLL中的同名函数,所以必须有个文件包括DLL库的正确定位信息,这个任务是由导入库来实现的。
Win32环境中,程序链接的时候仍然要使用函数库来定位函数信息,只不过由于函数代码放在DLL文件中,库文件中只留有函数的定位信息和参数数目等简单信息,这种库文件叫做导入库。
一个DLL文件对应一个导入库,如User32.dll文件用于编程的导入库是User32.lib。
includelib user32.lib
includelib kernel32.lib利用include语句的处理不同,includelib不会把 .lib文件插入到源程序中,☆它只是告诉链接器在链接的时候到指定的库文件中去找API函数的位置信息而已。
4.80x86处理器的寄存器
(常用寄存器的种类和用途)

(https://blog.csdn.net/u014774781/article/details/47707385)
1.通用寄存器、 (EAX、EBX、ECX、EDX、ESP、EBP、ESI、EDI)
| 通用寄存器名称 |
基本功能 |
| EAX |
操作数和结果数据的累加寄存器,用于算术运算 |
| EBX |
(在DS段中数据的指针)基址寄存器,用于间接寻址内存 |
| ECX |
计数寄存器,用于循环计数 |
| EDX |
(I/O指针)数据寄存器 |
| EDI |
变址寄存器,字符串/内存操作的目的线性地址 |
| ESI |
变址寄存器,字符串/内存操作的源线性地址 |
| EBP |
(SS段中的)栈内数据指针,用于为函数调用创建栈帧,常用作堆栈基址指针; |
| ESP |
(SS段中的)栈指针,栈顶(top of stack)字节的线性地址偏移 |
2.指令寄存器、 (EIP )
3.段寄存器、 (CS、SS、DS、ES、FS、GS)

4.标志寄存器、 (EFLAGS)
学习逆向分析技术的初级阶段,只需要掌握3个与程序调试相关的标志即可,分别为ZF(Zero Flag,零标志)、OF(Overflow Flag ,溢出标志)、CF(Carry Flag,进位标志)
以上三个标志之所以重要,是因为在某些汇编指令,特别是Jcc(条件跳转)指令中要检查这3个标志的值,并根据他们的值决定是否执行某个动作。
- ZF
若运算结果为0,则其值为1(True),否则其值为0(False)。
- OF
有符号整数(sined integer)溢出时,OF值被置为1.此外,MSB(Most Significant Bit,最高有效位)改变时,其值也被设为1。
- CF
无符号整数(unsigned integer)溢出时,其值也被置为1。
刚开始会混淆OF和CF的发生条件,导致结果不尽人意。不断积累调试经验就能明确区分了。
5.系统地址寄存器(GDTR/LDTR)、 (GDTR、IDTR、LDTR、TR)
段选择子(segment selector,也有翻译为段选择符的),就是段寄存器(CS、DS、ES、SS、FS、GS)的值,实模式下段的基地址等于段寄存器的值得乘以16,保护模式下段的基地址在描述符表中给出,段选择子的高13位就是描述符表(2个,全局和局部)的索引号(0~8191)。
GDTR:48位,低16位是GDT的大小,高32位是GDT的基地址。

LDTR:由可见部分和不可见部分组成,可见部分为16位。对某一个任务而言,必须要到GDT中找到LDT的描述符的选择子,装入16位可见部分,处理器把LDT的基地址和大小值装入不可见的高速缓存寄存器中。如果切换任务,也必须到GDT中找到要切换任务的LDT描述符的选择子,装入16位可见部分,处理器完成相应的初始化工作。
(每个段寄存器都配备了段描述符高速缓冲寄存器。他的内容有段基地址和每个段的大小(界限)以及他的相应的属性。在保护方式下,选择子装入后,从相关描述符中取得段基地址等内容,装入高速缓冲寄存器中,以后的操作只要选择子不变,CPU就不会再从描述符表中去找段基地址,而是直接从段描述符高速缓冲寄存器中去取,这样就可以大大提高系统速度。)

IDTR:类似于GDTR,中断比较常见,所以也必须把IDT的基地址装入寄存器中。

TR:类似于LDTR,可见部分为16位。80386的任务状态段是一个大的数据结构,任务切换时更改的内容更多,为了保证任务的快速切换,利用TR可以快速的定位。
6.控制寄存器(CR0,CR2,CR3) (CR0、CR1、CR2、CR3、CR4)
CR0:保护模式允许位、任务切换位
CR1保留未用
CR2:页故障地址寄存器 。CR2存放引起页故障的线性地址,只有在PG=1时,CR2才有效,当页故障处理程序被激活时,压入页故障处理程序堆栈中的错误码提供页故障的状态信息。
CR3:页表目录寄存器,存放页表目录的物理基地址。CR3的bit12--bit31存放页目录的基地址,因为也目录总是页对齐的(一页为4K),所以页目录基地址从bit12开始就可以了。只有当CR0中的PG=1时,CR3的页目录基地址才有效。
(https://blog.csdn.net/u014774781/article/details/47707385)
指令指针寄存器
- EIP:Instruction Pointer ,指令指针寄存器。
指令指针寄存器保存着CPU要执行的指令地址,其大小为32位(4个字节),由原16位IP寄存器扩展而来。
程序运行时,CPU会读取EIP中一条指令的地址,传送指令到指令缓冲区后,EIP寄存器的值自动增加,增加的大小即是读取指令的字节大小。
这样,CPU每次执行完一条指令,就会通过EIP寄存器读取并执行下一条指令。
与通用寄存器不同,我们不能直接修改EIP的值,只能通过其他指令间接修改,这些特定指令包括JMP、Jcc、CALL、RET。此外,我们还可以通过中断或异常来修改EIP的值。
段寄存器
IA-32的保护模式中,段是一种内存保护技术,它把内存划分为多个区段,并为每个区段赋予起始地址、范围、访问权限等,以保护内存。
此外,它还同分页技术(Paging)一起用于将虚拟内存变更为实际物理内存。段内存记录在SDT(Segment Descriptor Table,段描述符表)中,而段寄存器就持有这些SDT的索引(index)。

如图保护模式下的分段模型。
寄存器总共由6中寄存器组成,分别为CS、SS、DS、ES、FS、GS,每个寄存器的大小为16位,即2个字节。另外,每个段寄存器指向的段描述符(Segment Descriptor)与虚拟内存结合,形成一个线性地址(Linear Address),借助分页技术,线性地址最终被转换为实际的物理地址(Physical Address)。
(不使用分页技术的操作系统中,线性地址直接变为物理地址。)
- 代码段寄存器CS:存放应用程序代码所在的段的段描述符索引(代码段线性基址),CS+EIP得到下一条指令的线性地址。
- 栈段寄存器SS:存放栈段的段描述符索引(栈段的线性基址)
- 数据段寄存器(DS,ES,FS,GS):
- DS数据段含有程序使用的大部分数据;
- ES数据段可以为某些串指令存放目的数据;
- FS段寄存器可用于计算结构化异常处理SEH, 线程环境块TEB,进程环境块PEB等地址。
5.IA-32指令系统
(参数传递与堆栈平衡的原理,例子看懂)
1. 指令名称 目标操作数 源操作数 (操作码)
操作数的三种类型:通用寄存器、立即数、存储器地址
许多指令有两个操作数:源操作数和目的操作数
源操作数是指被传送或参与运算的操作数
目的操作数是指保存传送结果或运算结果的操作数
- 什么是操作数?
处理器指令的操作数表示参与操作的对象,可以是一个具体的常量,也可以是保存在寄存器中的数据,还可以是保存在存储器中的变量。在双操作数的指令中,目的操作数写在逗号前,用来存放指令操作的结果;对应地,逗号后的操作数就称为源操作数。
- 数据的寻址方式:
- 1.立即数寻址
这种操作数用常量形式直接表达,从指令代码中立即得到,称之为立即数。立即数寻址方式只用于指令的源操作数,在传送指令中常用来给寄存器和存储单元赋值。
mov eax,33221100h ;将数据33221100h传送到EAX寄存器
指令的机器码是:
B8 00 11 22 33
B8是操作码,后面四个字节是立即数本身。(数据高字节存放于存储器高地址单元,数据低字节存放于存储器低字节单元。)
- 2.寄存器寻址方式
指令的操作数存放在处理器的寄存器中,就是寄存器寻址方式。通常直接使用寄存器名表示它保存的数据,即寄存器操作数。绝大多数指令采用通用寄存器寻址(IA-32处理器是EAX/EBX/ECX/EDX/ESI/EDI/ESP/EBP,还支持16位形式:AX/BX/CX/DX/SI/DI/BP/SP,以及8位形式:AL/AH/BL/BH/CL/CH/DL/DH),部分指令支持专用寄存器如:段寄存器,标志寄存器等。
凡是只用寄存器名(无其他符号如中括号,变量名等)的操作数都采用寄存器寻址方式。
mov al,ah
mov bx,ax
mov ebx,eax
mov dx,ds
mov es,dx
寄存器既可以做源操作数特可以做目的操作数。另一个操作数可以是变量也可以是常量(源操作数)。但要之一操作数类型的一致性(同样长度)。
- 3.存储器寻址方式
数据很多时候都保存在主存储器中。尽管可以事先将它们取到寄存器中再进行处理,但指令也需要能够直接寻址存储单元进行数据处理。寻址主存中存储的操作数就成为存储器寻址方法,也称主存寻址方式。编程时,存储器地址使用包含段选择器和偏移地址的逻辑地址。
1.直接寻址
mov ecx,count;= mov ecx,[count]
假设变量count的有效地址是 00405000h
则机器码是:
8B 0D 00 50 40 00
反汇编为:
mov ecx,ds:[405000h]

2.寄存器间接寻址
mov edx,[ebx] ;双字传送,ebx间接寻址主存数据段
mov [edi],al ;字节传送,edi间接寻址主存数据段
mov cx,[esi] ;单字传送 ,esi间接寻址主存数据段
mov [ebp],edx ;双字传送,EBP间接寻址主存堆栈段
有效地址放在寄存器中,就是采用 寄存器间接寻址 存储器操作数。
寄存器的内容是偏移地址,相当于一个地址指针。
3.寄存器相对寻址
mov esi,[ebx+4]
mov eax,count[sei]
mov edi,[ebp-08h]
4.变址寻址
mov eax,[ebx+esi]
mov eax,[ebx+edx+80h]2. 基本指令
传送指令 MOV, MOVS
算术指令 ADD,SUB,MUL,DIV,IMUL,IDIV,LEA,
操作数比较指令 CMP,配合ZF标志位
分支指令 Jxx,根据标志位判定是否执行分支
注:详细指令用法请参照《32位汇编语言程序设计》,(之前我有整理过XMID导图在我的下载中)
这里简单复习后下后面要用到的cmp和几个跳转指令:
- 比较指令cmp
比较指令cmp(Compare)使目的操作数减去源操作数,差值不回送到目的操作数,但按照减法结果影响状态标志位。
cmp reg,imm/reg/mem ;减法:reg-imm/reg/mem
cmp mem,imm/reg ;减法:mem-imm/reg根据标志状态可以获知两个操作数的大小关系。
它主要是为了给条件转移等指令使用其形成的状态标志。
如CF(进位标志):有进位为1,反之为0
ZF(零标志) :结果是0(相等)还是非0(不等)
3.堆栈操作指令
处理器通常使用硬件支持堆栈(Stack)数据结构,它是一个按照“先进后出”(FILO,First In Last Out)存取原则组织的存储区域。
IA-32处理器的堆栈建立在主存区域中,使用SS段寄存器指向段基地址。
堆栈段的范围由堆栈指针寄存器ESP的初值确定,这个位置(ESP初值)就是堆栈底部(不再变化)。
堆栈只有一个数据入口,即当前栈顶(不断变化),由堆栈指针寄存器ESP的当前值指定栈顶的偏移地址。
如下图,随着数据进入堆栈,ESP逐渐减小;
随着数据依次弹出堆栈,ESP逐渐增大,
随着ESP增大,弹出的数据不再属于当前堆栈区域,随后进入堆栈的数据也会占用这个存储空间。当然,如果进入堆栈的数据超出了设置的堆栈范围,或者已无数据可以弹出(即ESP增大到栈底),就会产生堆栈溢出错误。
堆栈溢出,轻者使程序出错,重者会导致系统崩溃。

1.push
进栈指令push先将ESP减小当做栈顶,然后可以将立即数、通用寄存器和段寄存器内容或存储器操作数传送到当前栈顶。由于目的位置就是栈顶,且由ESP确定,所以PUSH指令只表达源操作数。
push r16/m16/i16/seg
push r32/m32/i32
IA-32处理器的堆栈只能以字或双字为单位操作。字量数据(word)进栈时,ESP向低地址移动2个字节单元(即减2)指向当前栈顶。
双字量数据进栈时,ESP减4,即准备4个字节单元。
然后,数据以“低对低,高对高”的小端方式存放到堆栈顶部。
PUSH指令等同于一条对ESP的减法指令(SUB)和一条传送指令(MOV)。

2.pop
出栈指令pop执行与进栈指令相反的功能,它先将栈顶数据传送到通用寄存器、存储单元或段寄存器中,然后ESP增加作为当前栈顶。
由于源操作数在栈顶,且由ESP确定。所以POP指令只表达目的操作数。
pop r16/m16/seg
pop r32/m32字量数据出栈时,ESP向高地址移动2个字节单元(即加2)。双字量数据出栈时,ESP加4.然后,数据以“低对低,高对高”原则从栈顶传送到目的位置。
如图所示,POP指令等同于一条传送指令(MOV) 和一条对ESP的加法指令(ADD)

3.堆栈的应用
堆栈是程序中不可或缺的一个存储区域。除堆栈操作指令外,还有子程序调用CALL和子程序返回RET、中断调用INT和中断返回IRET等指令,以及内部异常、外部终端等情况都会使用堆栈、修改ESP值。
堆栈可用来临时存放数据,以便随时恢复他们。
使用POP指令时,应该明确当前栈顶的数据是什么,可以按程序执行顺序向前观察由哪个操作压入了该数据。
既然堆栈是利用主存实现的,我们当然就能以随机存取方式读写其中的数据。通用寄存器之一的堆栈基址指针EBP就是出于这个目的而设计的。例如:
mov ebp,esp ;ebp=esp
mov eax,[ebp+8] ;eax=ss:[ebp+8]
mov [ebp],eax ;ss:[ebp]=eax上述方法利用堆栈实现了主程序与子程序间的传递参数,这也是堆栈的主要作用之一。
堆栈还常用于子程序的寄存器保护和恢复。
为此,IA-32处理器特别设计了将全部32位通用寄存器进栈PUSHAD和出栈POPAD指令、将全部16位通用寄存器进栈PUSHA和出栈POPA指令。利用这些指令可以快读的进行现场保护和恢复。
4.子程序结构
子程序在高级语言中常被称为函数(Function)或过程(Procedure)。
子程序可以实现源程序的模块化,简化程序结构。
1.子程序指令
子程序通常是与主程序分开的、完成特定功能的一端程序、当主程序(调用程序Caller)需要执行这个功能时,就可以调用该子程序(被调用程序Callee),于是,程序转移到这个子程序的起始处开始执行。当运行完子程序后,再返回调用它的主程序。
子程序由主程序执行子程序调用指令CALL来调用,而子程序执行完成后用子程序返回指令RET返回主程序继续执行。
MASM使用过程定义伪指令PROC/ENDP 编写子程序。
2.子程序调用指令CALL
call指令用在主程序中,实现子程序的调用。子程序和主程序可以在同一个代码段内,也可以不在同段内。
因而,与无条件转移指令JMP类似,子程序调用指令CALL也可以分成段内调用(近调用)和段间调用(远调用),同时,CALL指令的目标地址可以采用相对寻址或间接寻址,CALL指令共4种类型。(简单了解下即可,详细请翻阅《32位汇编语言程序设计》p119)
但是子程序执行结束是要返回的,所以CALL指令不仅要同JMP指令一样改变EIP和CS以实现转移,而且还要保留下一条要执行指令的地址,以便返回时重新获取它。
保留EIP和CS的方法是压入堆栈,获取EIP和CS的方法是弹出堆栈。
CALL指令实际上是入栈指令PUSH 和 转移指令JMP的组合。
2.子程序返回指令RET
子程序执行完后,应返回主程序中继续执行,这一功能由RET指令完成。
要回到主程序,只需获得离开主程序时由CALL指令保存于堆栈的指令地址即可。
在编程应用中,RET指令有两种书写格式:
ret ;无参数返回:出栈返回地址
ret i16 ;有参数返回:出栈返回地址,ESP=ESP+i16 。i16是立即数,堆栈指针增加这个指令可以方便的废除若干执行CALL指令以前入栈的参数。
书上有个例子,乍一看理解了半天:
例如在32位平台中,段内调用“CALL LABEL”指令相当于如下两条指令:
push next ;(1)入栈返回地址:ESP=ESP-4,SS:[ESP]=EIP (PUSH EIP)
jmp label ;(2)转移至目标地址:EIP=EIP+偏移量
这里压入堆栈的EIP是指CALL指令后的下一条指令地址,即返回地址,假设是NEXT标号,如下图。
子程序最后的RET指令实现相反功能:
ret ;(1)出栈返回地址:EIP=SS:[ESP],ESP=ESP+4 (POP EIP)
;(2)转移至返回地址:数据进入EIP,就作为下一条要执行指令的地址。
然后下面这句我理解了半天:
不妨思考如下代码片段,执行后EAX的内容是什么?
call next next: pop eax ;EAX=?书上的解释:CALL指令压入堆栈的返回地址是POP指令的地址,即NEXT标号对的地址,然后转到NEXT执行,即执行POP指令,此时栈顶的内容是其本身的地址,被弹出到EAX。所以,两条指令执行后,寄存器EAX获得POP指令的存储器地址。其实,这就是程序运行过程中获得当前指令地址的一个简单有效的方法。
注意,对于这段话的理解,如果你看到了我的这个笔记和我有同样的疑问:
call指令执行完了不是pop EIP的吗?栈里面不是什么也没有了吗?哪里来的栈顶的内容是其本身的地址,哪个本身?什么玩意?EAX怎么就是POP指令的存储器地址了?存储器地址又是什么玩意?
额,答案是不要被上面的代码误导了,因为他定义的这个next标号的子程序就只有一句话: pop eax
没有写ret
所以不会有pop eip,
所以呢,他就call next(push eip jmp next),然后就执行next里面的语句 pop eax,把人家call里面用来返回过去的地址(下一条指令的地址给弹出去了,弹到eax里面去了)。
至于后来怎么再往下执行,那就不是我要操心的问题了。
反正eax里面就是他说的什么pop指令的地址了,其实就是CALL压进去的。

最后呢再来巩固下,看书上的这个示例代码:
mov eax,1
mov ebp,5
call subp
retp1: mov ecx,3
retp2: mov edx,4
call disprd
subp proc
push ebp
mov ebp,esp
mov esi,[ebp+4]
mov edi,offset retp2
mov ebx,2
pop ebp
ret
subp endp子程序的调用和返回都要利用堆栈,调用时,CALL先把下一条指令的偏移地址作为返回地址EIP保存到堆栈,然后跳转到子程序。上面的代码中,返回地址就是“mov ecx,3”指令的地址,即标号retp1的地址。
所以call指令相当于如下两条指令:
push offset retp1
jmp subp画个图简单了解下过程:

在这里一开始自己有点不清楚的地方这里再点一下:
就是一开始我搞不清楚call 和ret的关系,不知道是不是我太笨。
(一般情况下)call是在 主程序中出现的,ret是在子程序中出现的。也就是说ret是由被调用的子程序(函数)来写的,子程序写没写不知道,但是这个任务是他来做的。
而我这个call函数只负责 把下一条指令的地址压入栈 push eip,然后jmp到你的函数里面去执行。
到后面释放参数(函数里面的局部变量)还有维持堆栈平衡(pop ebp)和pop eip 跳回来这是子程序要做的。
然后,大概是这样。
不知道10几天后考试,我会不会又忘个精光,这里写的仔细下,以防自己以后来复习查看。
5.局部变量
局部变量这个概念出现后,两个以上子程序都要用到的数据才被定义为全局变量统一放在数据段中,仅在子程序内部使用的变量则放在堆栈中,这样子程序可以编成“黑匣子”。
局部变量的作用域是单个子程序,在进入子程序的时候,通过修改堆栈指针esp来预留出需要的空间,在用ret指令返回主程序之前,同样通过恢复esp丢弃这些空间,这些变量就随之无效了。
它的缺点就是因为空间是临时分配的,所以无法定义含有初始化值的变量,对局部变量的初始化一般在子程序中由指令完成。
1.局部变量的定义
使用local伪指令,必须紧接在子程序定义的伪指令proc后、其他指令开始前,
这是因为局部变量的数目必须在子程序开始的时候就确定下来,可以有多个local语句,如果要定义数据结构可以用数据结构名称当做类型。默认类型是dword。定义数组可以用[],不能定义全局变量的dup伪指令。局部变量不能和已定义的全局变量同名。作用域是当前的子程序。
local loc1[1024]:byte ;1024字节长的局部变量loc1
local loc2 ;dword类型的局部变量loc2
local loc3:WNDCLASS ;WNDCLASS数据结构 loc3局部变量使用的例子如下:
TestProc proc
local @loc1:dword,@loc2:word
local @loc3:byte
mov eax,@loc1
mov ax,@loc2
mov al,@loc3
ret
TestProc endp反汇编如下:

可以看到多了:
push ebp
mov ebp,esp
add esp,FFFFFFF8
```
leave上面这些就是使用局部变量所必须的指令,分别用于局部变量的准备工作和扫尾工作。
执行了call指令后,CPU把返回的地址压入堆栈,再转移到子程序执行,(push EIP)
esp在程序的执行过程中可能随时用到,不可能用esp做指针来存取局部变量。
ebp寄存器也是以堆栈段为默认数据段的,所以可以用ebp作指针,于是,在初始化前,先用一句push ebp指令把原来的ebp保存起来,然后把esp的值放到ebp中,供存取局部变量做指针用,再后面就是在堆栈中预留空间了。
由于堆栈是向下增长的,所以要在esp中加一个负值,FFFFFFF8就是-8.
☆☆☆关于为什么三个变量加起来是7,这里为什么预留的空间是8:
这是因为80386处理器中,以dword为界对齐时存取内存速度最快,所以MASM宁可浪费一个字节。

在程序退出的时候,必须把正确的esp设置回去,否则,ret指令会从堆栈中取出错误的地址返回,看程序可以发现,ebp就是正确的初始值esp值,因为子程序开始的时候已经有一句mov ebp,esp ,所以要返回的时候只要先mov esp,ebp,然后再pop ebp,堆栈就是正确的了。
在80386指令集中有一条指令可以在一句中实现
mov esp,ebp
pop ebp就是
leave所以在ret指令之前只使用了一句leave指令
明白了局部变量使用的原理,就很容易理解使用时的注意点:ebp寄存器是关键,它起到保存原始esp的作用,并随时用做存取局部变量的指针基址,所以在任何时刻,不要尝试把ebp用于别的用途,否则会带来意想不到的后果。
6.参数传递与堆栈平衡
参数传递通过堆栈进行,调用者按照特定顺序把参数压入堆栈;
可以看到在参数入栈顺序上,C类型和StdCall类型是先把右边的参数先压入堆栈。
而PASCAL类型是先把左边的参数压入堆栈。
在堆栈平衡上,
调用者或者被调用者必须有一方把堆栈指针即ESP修正到调用前的状态,即实现堆栈平衡。
例如:C类型是在调用者使用CALL指令完成后,由调用者自行用add esp,n 指令,把n个字节的参数空间清除;
而StdCall和PASCAL的堆栈平衡则是由被调用的子程序使用用ret n 来实现。
假定调用的子函数foo(arg1,arg2,arg3),按照C、PASCAL和stdcall的调用约定,汇编代码为

ret ;(1)出栈返回地址:EIP=SS:[ESP],ESP=ESP+4 (POP EIP)
;(2)转移至返回地址:数据进入EIP,就作为下一条要执行指令的地址。
===========
花了3-4天,真的是从早到晚,可能太笨了效率低。前面的什么CSDR?还是什么玩意段寄存器的作用寻址什么玩意又忘光了,感觉后面也用不到,但是怕考试再考,打算回来再做个精简版考点提纲的专门复习。
===========
后记:
2020.1.08:考完了。估计以后不一定再会看这方面的东西了,除非工作需要了吧?
博客只整理了三个PART,后面进度赶不上了,就直接在书上画画写写整理整理自己的理解背诵背诵了。
关于考试:自己一开始太大意了,觉得时间很充足,以前考试考完还有很长时间,前面就做的很细致很慢,导致最后30分钟两道还没有写。
2020.1.9:今天出成绩了,意料之中,毕竟很多题没有很准确也差些没写完。班里很多同学考的都很好,请教了一个考了90+的女同学,她说考前的那个晚上她只睡了1个小时,相比较我只熬到了晚上1.30来说,自己真的还差了很多。
突然增长的一些自信又压了下去,感觉我的学习方法还需要继续改进。
我之前有一种想法,通过这些考试,我可以锻炼自己的学习方法,争取考研可以事半功倍,不要做无用之功。
现在稍微总结回顾一下我的学习方法:我总是试图找到很多可供参考的东西,然后阅读了解很多相关的东西,最后才看那些“重点”,缺少深加工 和 反复理解思考 以及 及时复习温故。
那在以后的学习中,希望我可以做到至少下面这几点:
学习过程中时刻思考-多角度思考可能会出现的题目考点-思考是不是自己在“表面上努力自我感动”然后及时调整学习方法-最后,我真的佩服那个女生,自愧不如,相形见绌,(语言能力有限)总的来说就是革命尚未成功,同志仍需努力!加油!
