个人觉得,本书中所讲的内容都是希望读者不求甚解,只需要了解一些用法就行。可惜博主刚好不是,总想把这些问题的原因搞清楚,比如Scrapy的工作流程,为什么我们一上手就要添加item,然后就直接解析数据了?在没搞清楚工作机制的情况下,满脑子都是浆糊。于是Read the f*cking document.(https://docs.scrapy.org/en/latest/topics/architecture.html)
Scrapy的组件
- Scrapy Engine(引擎):核心组件,用于控制所有组件的数据流,和触发事件。
- Scheduler(调度器):接收引擎过来的请求、压入队列,并在引擎再次请求的时候返回。
- Downloader(下载器):发送请求到url,接收服务器响应并返回到爬虫。
- Spiders(爬虫):解析响应数据,并提取所需要的数据为条目(items)。
- Item Pipeline(条目管道):处理爬虫从网页中抽取的条目,主要的功能是持久化条目、验证条目的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到条目管道,并经过几个特定的次序处理数据。
- Downloader middlewares(下载器中间件):是引擎与下载器之间的框架,主要是处理引擎与下载器之间的请求及响应。
- Spider middlewares(爬虫中间件):引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
Scrapy的框架和工作流
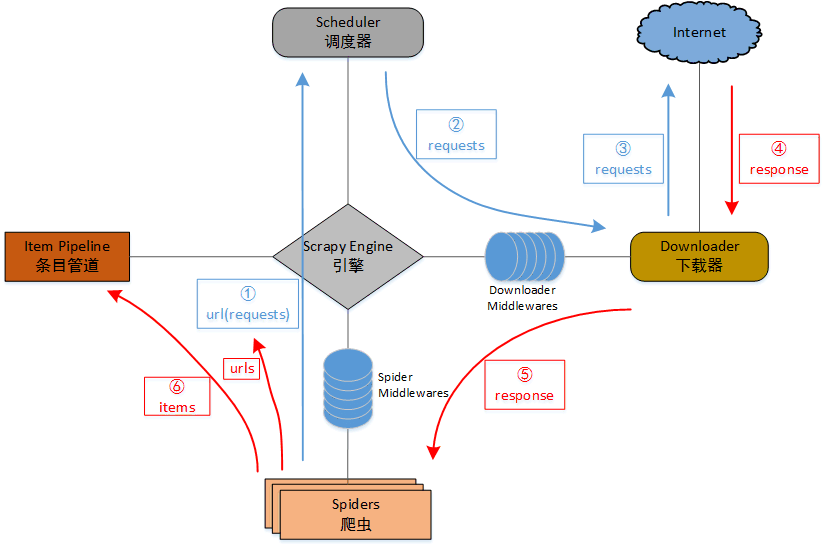
根据文档里的框架和数据流,结合网上流传比较多的框架,博主略微调整了一下。
数据控制流说明:
- 爬虫(Spiders)首先将初始网址和请求(URL、Requests)通过引擎(Engine)提交给调度器(Scheduler)。
- 调度器(Scheduler)将请求进行排序、入队,再经过引擎(Engine)、下载器中间件(Downloader Middlewares)提交给下载器(Downloader)。如果有必要的话,可以通过下载器中间件加入User-Agent、Proxy等信息。
- 下载器(Downloader)向目标URL发送请求。
- 下载器(Downloader)接收目标URL的响应。
- 下载器(Downloader)将响应通过引擎(Engine)、爬虫中间件(Spider middlewares)提交给爬虫(Spiders)。
- 爬虫(Spiders)处理响应、解析数据,将数据条目经引擎(Engine)提交到条目管道(Item Pipeline)保存,也可以从响应数据中提取URL再经引擎交给调度器进行下一次循环,直到无URL请求时结束。
在爬取数据的时候需要我做什么?
Scrapy的优势就在于:框架本身已经解决了很多通用的过程,比如提交请求、下载、底层数据传递等等。这些工作主要是由引擎(Engine)、调度器(Scheduler)和下载器(Downloader)自动完成,而我们需要做的主要是:
- 创建Spiders、定义需要的数据和URL;
- 通过item pipeline处理传递回的数据,比如存储;
- 如果有必要的话,自定义下载扩展,如浏览器头(User-Agent)、代理(Proxy)等;
- 如果有必要的话,自定义请求(requests)、响应(response)过滤。