Scrapy工作流程(重点)
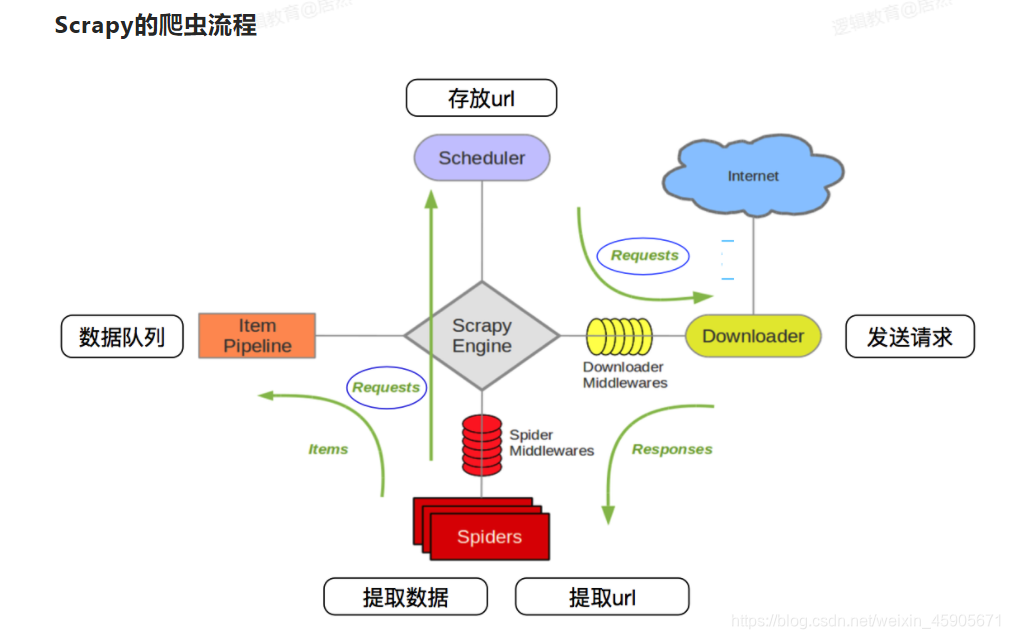
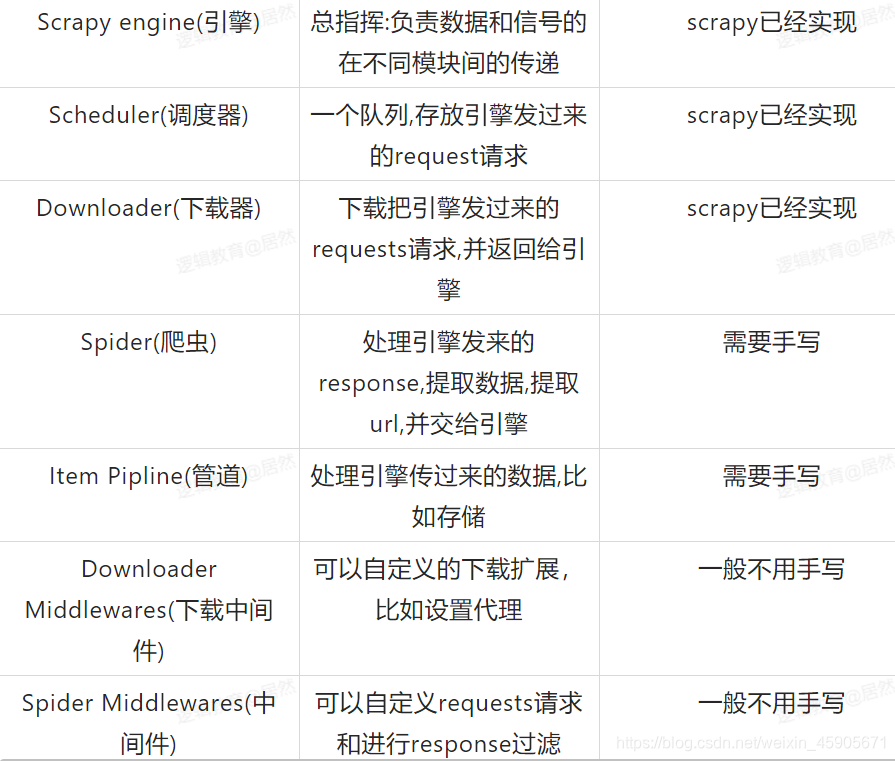
1.首先Spider(爬虫)将需要发送请求的url经过ScrapyEngins(引擎)交给调试器Scheduler(调度器)
2.Scheduler(调度器)排序 入列处理后,再经过ScrapyEngins(引擎)到DownloaderMiddleware(下载中间件)(user-agent cookie porxy)交给downloader(下载者)–>向internet发送请求,Downloader向互联网发起请求,并接收响应(response) 将响应在经过ScrapyEngins(引擎)给了SpiderMiddlewares(爬虫中间件)交给Spiders,Spiders处理response , 提取数据并将数据经过ScrapyEngine交给itemPipeline(管道)保存数据
Scrapy 命令
1.创建Scrapy项目
scrapy startproject xxx
cd xxx
2.生成一个爬虫文件
scrapy genspider xx ‘yyy.com’
3.运行项目(pycharm中)
from scrapy import cmdline
1 cmdline.excute(‘scrapy crawl xx’.split())
2 cmdline.excute([‘scrapy’, ‘crawl’,‘xx’])
Scrapy项目结构
pipelines
接收item返回的数据 并处理 爬虫文件中通过yield 返回数据
def process_item(self,item,spider):
return item
# item 数据来源 通常要保存数据的时候都要 借助 json模块来处理
# spider 可以用来判断数据的来源
别忘记开启管道
items
``
提前在items中定义好我要爬取的字段
name = scrapy.Field()
# 需要注意的爬虫文件中导入模块的时候 把Scrapy项目选为根目录来进行导入 setting--->MarkDiretoryas-->Source Root
`
```
spider
name = '爬虫的名字'
启动项目的时候 名字不要写错
allowed_domains = [允许爬取的范围(域名)]
start_urls = ['开始爬取的url']
注意:开始的地址 首先这个数据是否在这个地址中 如果在 可以xpath来定义下一页的方式翻页
如果不在 NetWork分析数据接口来确定开始的url地址 并且需要找下一页地址的规律
def pares(self, response):
xxxx = response.xpath('//xxxx')
item = {}
yield scrapy.Request(
url = url,
callback = self.zzz
meta = {'item': item}
)
yiedl item