文中提出了一种深度网络来解决单通道语音增强问题。
链接:https://arxiv.org/abs/1911.01902
简介
因为背景噪声和混响的存在,录音通常会被扭曲,会对后端的语音识别等技术产生负面影响。单通道的语音增强算法一般有以下几种:Spectral estimation methods(OMLSA,etc),Source separation methods,Mapping methods。DNNs方法属于最后一种。DNN在训练过程中能够处理大量不同种类的噪声信号,这使其可以同时用于语音去混响和降噪方面。
在电话通信和助听器等实际应用中,都需要满足低延迟特性。
本文针对加性背景噪声(additive background noise)情况下的语音增强,采用一个FCN(fully convolutional network)代替全连接前馈网络。首先采用了主流的FCNs中的U-Net,基于此提出了一个新的结构即VGG19-UNet,在U-Net的编码解码结构中的编码部分嵌入一个VGG19的深度全卷积网络。
学习过程中,输入/输出特征分别为含噪/干净语音的频谱图,尺寸256*256。为了近似人耳听觉效应,文中建议采用Mel频率和幂律非线性频谱表示。
算法
U-Net的学习能力很强,由encoder, decoder和skip connections三部分组成。VGG的贡献在于揭示了卷积网络的深度对于大规模的图像定位和分类性能的影响。
图1(a)展示了VGG19的结构,图1(b)展示了一种新的语音增强网络,我们采用了VGG19的5个卷积块构成了一个强大的特征提取器,提取特征被喂到解码器部分。解码器中,采用2*2的上采样和2个具有ReLU的3*3 CNN层,该sequence重复5次。每个sequence的通道数减半最终到32,并且转换为频谱图通过一个具有线性激活函数的CNN。
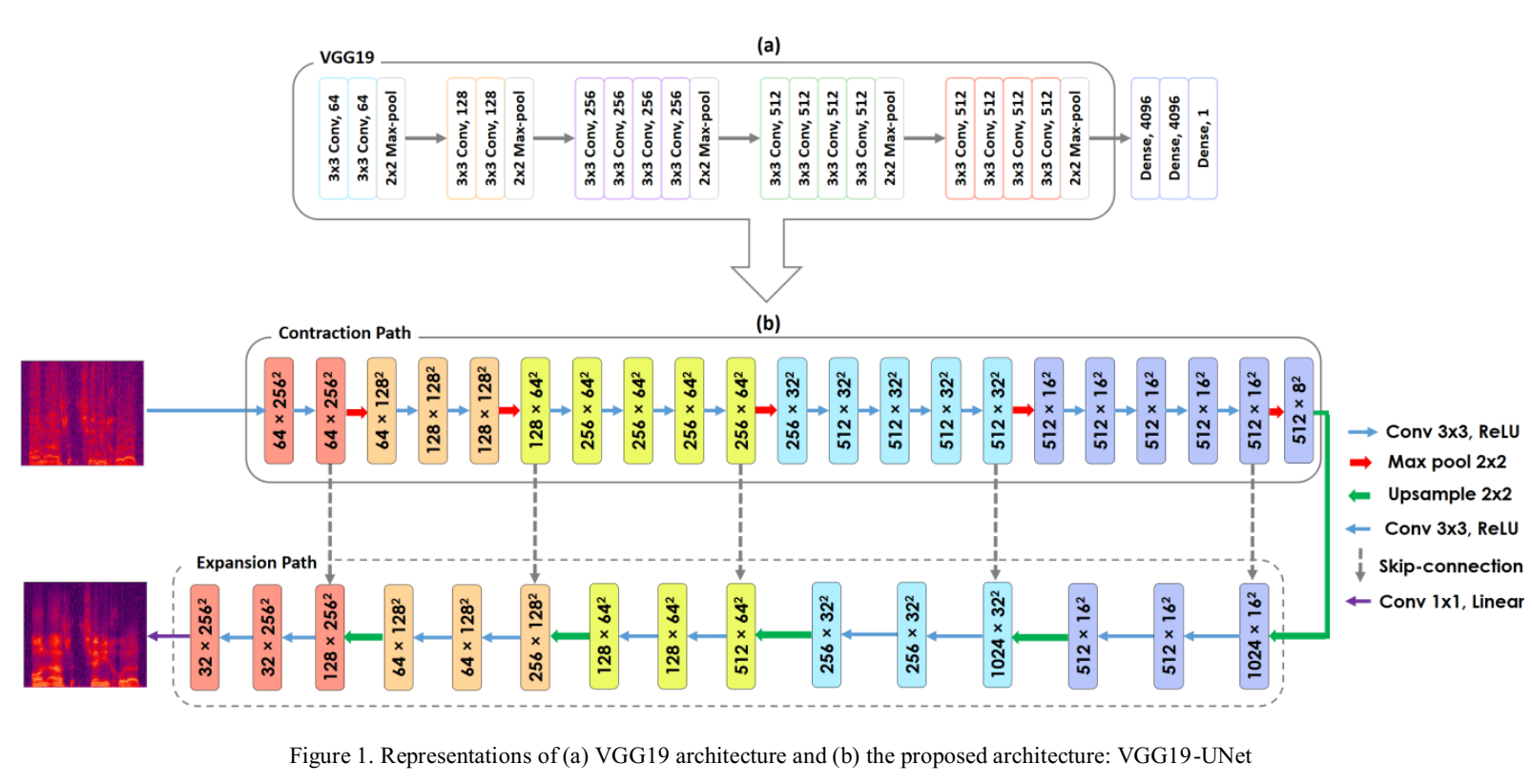
详细来说,文中提出的算法被称为VGG19-UNet-MelPow语音增强器。主要由以下三个步骤组成:
1、提取perceptually-modified频谱图。
对时域信号进行STFT得到幅度谱。帧长32ms,帧移8ms,FT点数为512。最终得到幅度谱向量维度为257。
文中将对幅度谱采用mel尺度和幂律非线性得到的向量称为MelPow幅度谱向量。将256个连续的MelPow幅度谱向量拼接起来就得到了perceptually-modified幅度谱(注意,为了保证图像的对称性,忽略了最高频率带的图像),即得到256*256个时频单元。
另,得到修正幅度谱图像之前,仅对含噪语音的MelPow幅度谱向量进行基于语句的均值方差归一化。
2、学习VGG19-UNet结构。
用步骤1得到的图像集训练VGG19-UNet网络。利用Tensorflow和Keras库,the proposed network采用Adam优化方法,学习率为0.0002,50个epochs。批大小为10,训练集随机选取。采用线性激活函数生成增强后的谱图。训练时使得代价函数MSE最小。
3、生成增强语音。
首先通过步骤1得到修正谱图像,并将其送到训练好的VGG19-Unet模型中,得到Mel频率和幂律的增强幅度谱图。结合含噪语音的相位信息和ISTFT,生成增强后的时域语音信号。
实验分析
实验中主要采用FARSDAT和NOISEX-92数据集,按照0.75,0.1,0.15的比例随机分为train,dev和test集。
采用两个主观评价准则,从语音质量(PESQ)和可懂度(ESTOI)两个方面,两个测度都是越高越好。
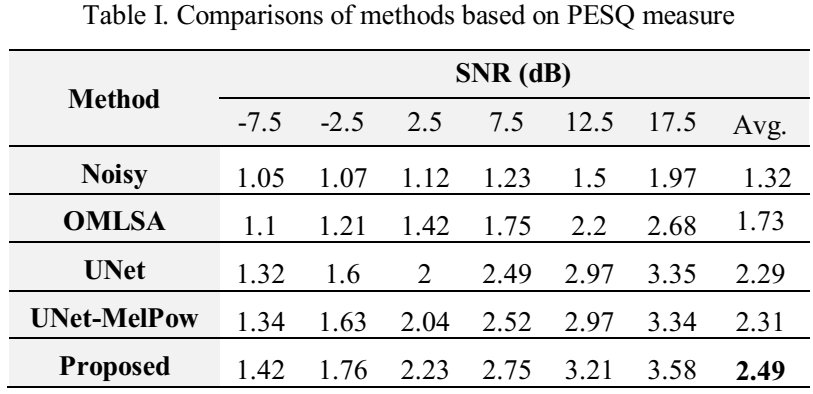
在不同的信噪比下面进行实验,结果表1和表2所示,均证明了文中方法的优越。

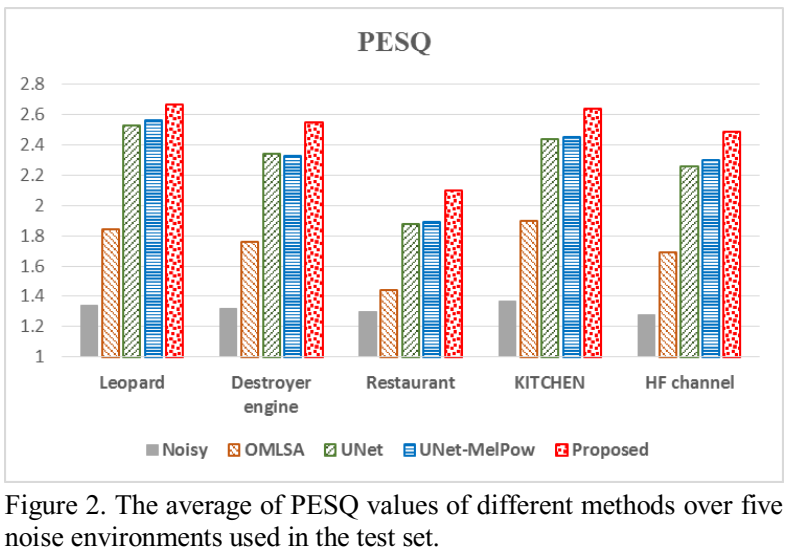
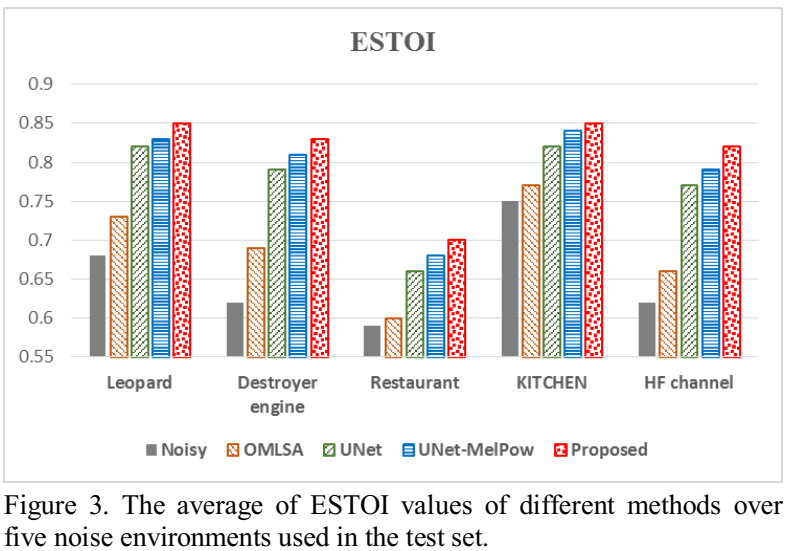
在不同种类的背景噪声环境下进行实验,结果见图2和图3。可以看出,不同方法在Restaurant和HF channel噪声下的结果都是最差的。和之前的结果类似,基于UNet-MelPow方法的结果优于Unet的。
文中还分析了不同方法的频谱图和共振峰的差异。
此外,为了验证在UNet-MelPow语音增强方法中,增加U-Net结构的参数的影响,作者们将U-Net的所有卷积层中的滤波器数目加倍,即1024个,得到了31M的参数。将采用1024 filters的U-Net的UNet-MelPow方法称为UNet-MelPow-1024,将其和提出算法对比。实验证明,两种算法即使参数数量相同,但是proposed method增强后的语音仍有更好的PESQ和ESTOI。作者猜测,这是因为文中提出的VGG19-UNet结构中编码器采用了更深的结构。因为VGG19-UNet的编码器有16个卷积层,而传统的U-Net只有10个卷积层。