AC自动机——1 Trie树(字典树)介绍
之前,我们介绍了Kmp算法,其实,他就是一种单模式匹配。当要检查一篇文章中是否有某些敏感词,这其实就是多模式匹配的问题。当然你也可以用KMP算法求出,那么它的时间复杂度为O(c*(m+n)),c:为模式串的个数。m:为模式串的长度,n:为正文的长度,那么这个复杂度就不再是线性了,我们学算法就是希望能把要解决的问题优化到极致,这不,AC自动机就派上用场了。
其实AC自动机就是Trie树的一个活用,活用点就是灌输了kmp的思想,只是在AC自动机中,对Trie增加了一个返回的指针,相当于kmp算法中的next值。从而再次把时间复杂度优化到线性的O(N)。
接下来,我们先介绍一下Trie树
保存6个字符串tea,ten,to,in,inn,int的Trie树
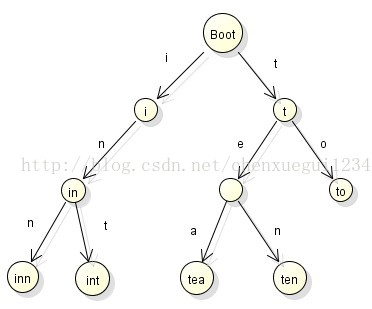
Trie树的基本性质可以归纳为:
(1) 根节点不包括字符,除根节点意外每个节点只包含一个字符
(2) 从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串
(3) 每个节点的所有子节点包含的字符串不相同
当然,Trie树也有一个缺点,如果系统中存在大量字符串且这些字符串基本没有公共前缀,则相应的trie树将非常消耗内存
一下,我们再看Trie树的基本实现
字母树的插入( Insert)、删除(Delete)和查找(Find)都非常简单,用一个一重循环即可,即第i次循环找到前i个字母所对应的子树,然后进行相应的操作。实现这棵字母树,我们用最常见的数组保存(静态开辟内存)即可,当然也可以开动态的指针类型(动态开辟内存)。至于结点对儿子的指向,一般有三种方法:1、列每个结点开一个字母集大小的数组,列应的下标是儿子所表示的字母,内容则是这个儿子列应在大数组上的位置,即标号(易实现,空间要求较大)2、对每个结点挂一个链表,按一定顺序记录每个儿子是谁(空间相对较小,比较费时)3、使用左儿子右兄弟表示法记录这棵树。(空间要求最小,相对费时且不容易写)
- //定义节点的子节点数目 26代表26个字母
- #define MAX_NUM 26
- //定义节点类型,completed意为到从根节点到此节点为一个字符串
- enum NODE_TYPE
- {
- COMPLETED,
- UNCOMPLETED
- };
- //节点数据类型
- struct Node
- {
- enum NODE_TYPE type;
- char ch;
- struct Node* child[MAX_NUM];
- }
- struct Node* ROOT;
- //创建新节点
- struct Node* createNewNode(char ch)
- {
- struct Node* new_node = (struct Node*) malloc(sizeof(struct Node));
- new_node->ch = ch;
- new_node->type = UNCOMPLETED;
- int i;
- for(i=0; i<MAX_NUM; i++)
- new_node->child[i] = NULL;
- return new_node;
- }
- //初始化Trie树
- void initialization()
- {
- ROOT = createNewNode('');
- }
- //
- int charToindex(char ch)
- {
- return ch - 'a';
- }
- // 查询字符串
- int find(const char chars[], int len)
- {
- struct Node* ptr = ROOT;
- int i = 0;
- while(i<len)
- {
- if(ptr->child[charToindex(chars[i])] == NULL)
- break;
- ptr = ptr->child[charToindex(chars[i])];
- i ++;
- }
- return (i == len) && (ptr->type == COMPLETED);
- }
- //插入将字符串插入Trie树
- void insert(const char chars[], int len)
- {
- struct Node* ptr = ROOT;
- int i;
- for(i = 0; i<len; i++)
- {
- if(ptr->child[charToindex(chars[i])] == NULL)
- {
- ptr->child[charToindex(chars[i])] == createNewNode(chars[i]);
- }
- ptr = ptr->child[charToindex[chars[i]]];
- }
- ptr->type = COMPLETED;
- }
Triel树应用
(l)字符串检索
事先将已知的些字符串(字典)的有关信自保存到trie树里,查找另外些未知字符串是否出现过或者出现频率。
举例:
1给出N个单词组成的熟词表,以及篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。
2给出个词典,其中的单词为不良单词。单词均为小写字母。再给出段文本,文本的每行也自小写字母构成。判断文本中是否含有任何不良单词。例如,若rob是不良单词,那么文本problem含有不良单词。
(2)字符串最长公共前缀
Trie树利用多个字符串的公共前缀来节省存储空间,反之,当我们把大量字符串存储到棵trie树上时,我们可以快速得到某些字符串的公共前缀。
举例:
1给出N个小写英文字母串,以及Q个询问,即询问某两个串的最长公共前缀的长度是多少
解决方案:首先对所有的串建互其对应的字母树。此时发现,对于两个串的最长公共前缀的长度即它们所在结点的公共祖先个数,于是,问题就转化为了离线(Offline)的最近公共祖先(L—t Comon An…tor,简称LCA)问题
而最近公共祖先问题同样是个经典问题.可以用下面几种方法:
1)利用并查集(Disioint Set),可以采用采用经典的Tarian算法,
2)求出字母树的殴拉序列(Eul er Sequence)后,就可以转为经典的最小值查询(RanZeMinimum Querr,简称ⅫO)问题了,
(关于并查集,T arjar薄法,Ⅻ。问题,网上有很多资料。)
(3)排序
Trie树是棵多叉树,只要先序遍历整棵树,输出相应的字符串便是按字典序排序的结果。
举例:
给你N个互不相同的仅由一个单词构成的英文名,让你将它们按字典序从小到大排序输出。
(4)作为其他数据结构和算法的辅助结构
如后缀树,AC自动机等
同时,由于Trie树的空间复杂度是26^n级别,非常庞大,可用双数组改善