1.linear evaluation 是把模型骨干冻住,去训练最后的那个全连接层
2.端到端的学习其实就是不做其他额外处理,从原始数据输入到任务结果输出,整个训练和预测过程,都是在模型里完成的。
其实业界对于端到端的定义比较模糊,以下几种都可以自称为端到端:
①输入的是原始数据(不需要对原始数据进行预处理),就叫端到端;
②输入的是原始数据,输出为最终需要的结果,就叫端到端;
③进行的是全局优化,强调一个神经网络模型囊括模型中所有步骤:可以实现各个子步骤的综合的、全局的优化的模型 也可以叫作端到端。
摘自
3.Kmeans聚类算法Kmeans聚类算法详解
作为无监督聚类算法中的代表——K均值聚类(Kmeans)算法,该算法的主要作用是将相似的样本自动归到一个类别中。所谓的监督算法,就是输入样本没有对应的输出或标签。聚类(clustering)试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇(cluster)”。
Kmeans算法是最常用的聚类算法,主要思想是:在给定K值和K个初始类簇中心点的情况下,把每个点(亦即数据记录)分到离其最近的类簇中心点所代表的类簇中,所有点分配完毕之后,根据一个类簇内的所有点重新计算该类簇的中心点(取平均值),然后再迭代的进行分配点和更新类簇中心点的步骤,直至类簇中心点的变化很小,或者达到指定的迭代次数
4.EM算法是一种迭代优化策略,由于它的计算方法中每一次迭代都分两步,其中一个为期望步(E步),另一个为极大步(M步),所以算法被称为EM算法(Expectation-Maximization Algorithm),最初是为了解决数据缺失情况下(包含隐变量)的参数估计问题。
摘自EM算法详解
5.Logit变换 详解见Logit究竟是个啥?——离散选择模型之三
线性回归是因变量取值是负无穷到正无穷,而二分类变量的研究指标通常是率,他的取值是0-1,没办法使用线性回归进行分析。而通过logit函数变换,可以使得0-1,变成负无穷到正无穷,就可以使用线性回归的一切方法。这就是logistic回归产生的根源。
Logit的一个很重要的特性就是没有上下限——这就给建模带来极大方便。
(也就是说经过logit变换,将[0,1]的概率p转变为负无穷到正无穷)


6.KL 散度,是一个用来衡量两个概率分布的相似性的一个度量指标。详见机器学习:KL散度详解
现实世界里的任何观察都可以看成表示成信息和数据,一般来说,我们无法获取数据的总体,我们只能拿到数据的部分样本,根据数据的部分样本,我们会对数据的整体做一个近似的估计,而数据整体本身有一个真实的分布(我们可能永远无法知道)。
那么近似估计的概率分布和数据整体真实的概率分布的相似度,或者说差异程度,可以用 KL 散度来表示。
xi所带信息量
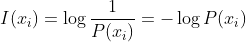
信息熵:平均信息量
用基于P的编码去编码来自P的样本,其最优编码平均所需要的比特个数。
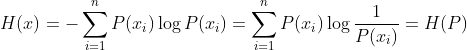
连续信息的平均信息量
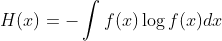
交叉熵:
用基于P的编码去编码来自Q的样本,所需要的比特个数。
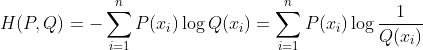
相对熵【KL散度】:
知道P至少需要多少比特将Q表示出来
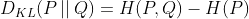
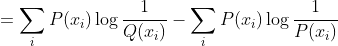
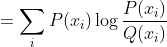
7.马尔科夫链

马尔科夫链认为过去所有的信息都被保存在了现在的状态下了 。比如这样一串数列 1 - 2 - 3 - 4 - 5 - 6,在马尔科夫链看来,6 的状态只与 5 有关,与前面的其它过程无关。马尔科夫链认为 过去所有的信息都被保存在了现在的状态下了。
非马尔科夫链过程的例子:
只有满足马尔科夫链的特性,才属于马尔科夫链过程。例如对于不放回的袋中取球问题:
显然当前取球的概率,不仅和我最后一次取的球的颜色有关,也和我之前每一次取球的颜色有关,所以这个过程不是一个马尔科夫链过程。
如果是放回的袋中取球问题,这就建立了一个马尔科夫随机过程。