(1)用线性回归找到最佳拟合直线
线性回归的优点是结果易于理解,计算不复杂,缺点是对非线性的数据拟合不好,适用于数值型和标称型数据类型。
线性回归最重要的是找到回归系数,一旦找到回归系数,乘以输入值,再将结果全部累加在一起,就得到了预测值。(假定输入数据存放在矩阵X中,回归系数存放在向量W中,则预测结果Y = X.T*W)
找到合适的回归系数W一个最常见的方法是找出误差最小的W(误差值预测值和真实值的差值),我们一般采用平方误差:
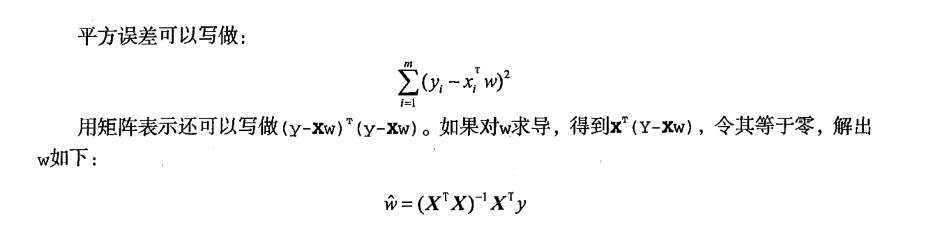
以下代码可用来找到数据的最佳拟合直线:
1)标准回归函数和数据导入函数:
from numpy import * def loadDataSet(fileName): #general function to parse tab -delimited floats numFeat = len(open(fileName).readline().split('\t')) - 1 #get number of fields dataMat = []; labelMat = [] fr = open(fileName) for line in fr.readlines(): lineArr =[] curLine = line.strip().split('\t') for i in range(numFeat): lineArr.append(float(curLine[i])) dataMat.append(lineArr) labelMat.append(float(curLine[-1])) return dataMat,labelMat def standRegres(xArr,yArr): # 计算最佳拟合直线 xMat = mat(xArr); yMat = mat(yArr).T xTx = xMat.T*xMat if linalg.det(xTx) == 0.0: # 如果行列式为0计算逆矩阵会出现错误 print("This matrix is singular, cannot do inverse") return ws = xTx.I * (xMat.T*yMat) # .I返回逆矩阵,.T返回矩阵的转置 return ws # ws存放的就是回归系数
导入数据集中的数据后所得到的最佳拟合直线如下图所示:
我们应该怎么判断模型的好坏呢?一种方法就是计算预测值yHat序列和真实值y序列的匹配程度(即相关系数),可以调用python中Numpy库的corrcoef()命令来计算
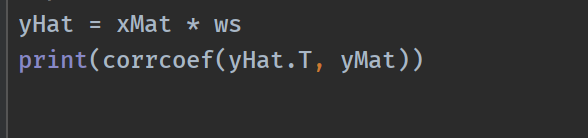
可以得到相关系数:

可以看到对角线上的数据是1.0,因为yMat,yHat和自己的匹配程度都是最完美的,而yHat和yMat的匹配程度大约为0.98,说明匹配程度相当不错。
(2)局部加权线性回归
线性回归有可能会出现欠拟合现象,所以引入局部加权线性回归(LWLR),该算法给待预测点附近的每一个点赋予一定的权重,LWLR算法解出回归系数W的公式为: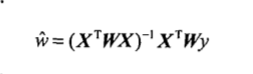
LWLR使用“核”来对附近的点赋予更高的权重,最常见的是高斯核,对应的权重如下:
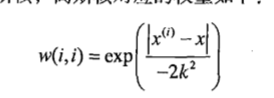
点X与X(i)越近,w(i,i)就越大,上面公式包含一个需要用户指定的参数K决定了对附近的点赋予多大的权重,也是LWLR唯一需要考虑的参数。
LWLR代码如下:
# 给定X空间中的任意一点,计算出对应的预测值yHat def lwlr(testPoint,xArr,yArr,k=1.0): # lwlr为局部加权线性回归 # 随样本点与待预测点距离的递增,权重值将以指数级衰减 # 输入参数K控制衰减的速度 xMat = mat(xArr); yMat = mat(yArr).T m = shape(xMat)[0] weights = mat(eye((m))) '''创建对角权重矩阵weights,为每个样本点初始化了一个权重''' '''遍历数据集,计算每个样本点对应的权重值''' for j in range(m): diffMat = testPoint - xMat[j,:] weights[j,j] = exp(diffMat*diffMat.T/(-2.0*k**2)) xTx = xMat.T * (weights * xMat) if linalg.det(xTx) == 0.0: print("This matrix is singular, cannot do inverse") return ws = xTx.I * (xMat.T * (weights * yMat)) return testPoint * ws def lwlrTest(testArr,xArr,yArr,k=1.0): #loops over all the data points and applies lwlr to each one m = shape(testArr)[0] yHat = zeros(m) for i in range(m): yHat[i] = lwlr(testArr[i],xArr,yArr,k) return yHat
改变参数K,所得到的结果如下图所示:

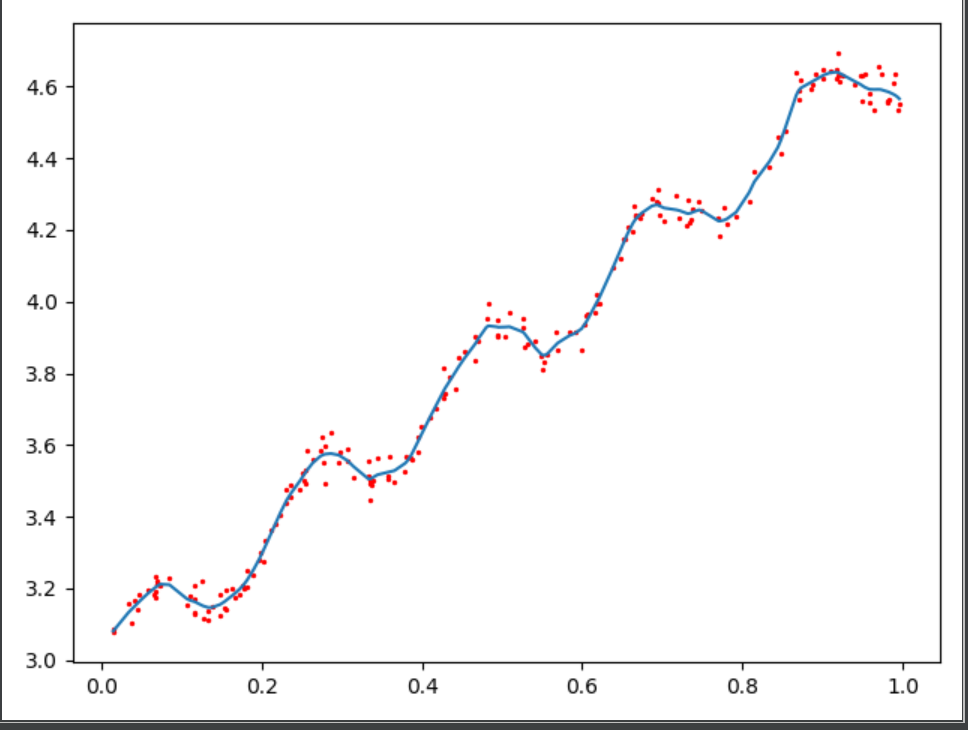
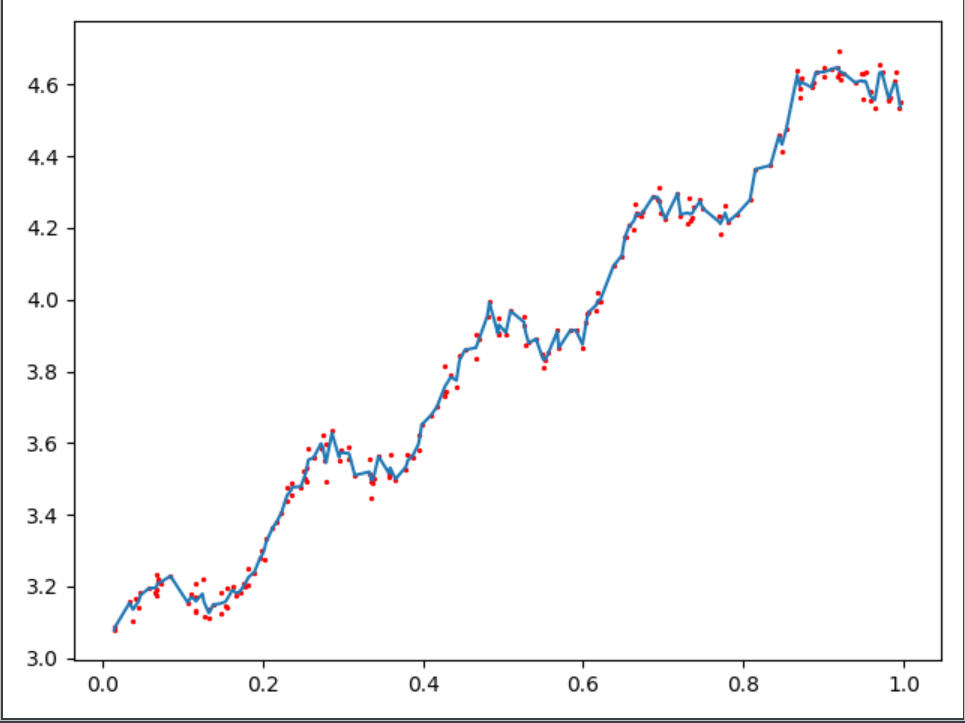
以上三张图分别为K=1.0/0.01/0.003时候的结果,可以看出K=0.01时可以挖掘出数据的潜在规律,但K=0.003时候就会出现overfitting的问题。
(3)岭回归
岭回归就是在矩阵(XT)X上加入一个λI从而使得矩阵非奇异,进而能对(XT)X+λI求逆。矩阵I是一个m维单位矩阵,λ是用户自定义的数值,此时回归系数的计算公式是:
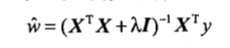
引入λ后能够减少不重要的参数,从而更好地理解数据,有更好的预测结果。
岭回归的实现代码如下:
def ridgeRegres(xMat,yMat,lam=0.2): # 计算回归系数 xTx = xMat.T*xMat denom = xTx + eye(shape(xMat)[1])*lam if linalg.det(denom) == 0.0: print("This matrix is singular, cannot do inverse") return ws = denom.I * (xMat.T*yMat) return ws def ridgeTest(xArr,yArr): # 用于在一组λ上计算结果 xMat = mat(xArr); yMat=mat(yArr).T yMean = mean(yMat,0) yMat = yMat - yMean #to eliminate X0 take mean off of Y # 数据标准化(减去均值再除以方差 xMeans = mean(xMat,0) #calc mean then subtract it off xVar = var(xMat,0) # 计算方差 xMat = (xMat - xMeans)/xVar numTestPts = 30 wMat = zeros((numTestPts,shape(xMat)[1])) for i in range(numTestPts): ws = ridgeRegres(xMat,yMat,exp(i-10)) wMat[i,:]=ws.T return wMat