目录
@
一、字符集和字符编码
1.1、字符集
- 字符集:字符集就是字符的集合,例如GB2312是中国国家标准的简体中文字符集,GB2312收录简化汉字(6763个)及一般符号、序号、数字、拉丁字母、日文假名、希腊字母、俄文字母、汉语拼音符号、汉语注音字母,共 7445 个图形字符。
字符集查询sql:
# 方法一:直接show charset
SHOW CHARSET;
#方法二:查询information_schema实例的character_sets
SELECT * FROM information_schema.character_sets;我本地是5.7.22版本,支持的字符集就有如下:
| Charset | Description | Default collation | Maxlen |
|--|--|--|--|
|big5| Big5 Traditional Chinese| big5_chinese_ci | 2 |
|dec8 | DEC West European | dec8_swedish_ci | 1 |
|cp850 | DOS West European | cp850_general_ci | 1 |
|hp8 | HP West European | hp8_english_ci | 1 |
|koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 |
|latin1 | cp1252 West European | latin1_swedish_ci | 1 |
|latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 |
|swe7 | 7bit Swedish | swe7_swedish_ci | 1 |
|ascii | US ASCII | ascii_general_ci | 1 |
|ujis | EUC-JP Japanese | ujis_japanese_ci | 3 |
|sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 |
|hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 |
|tis620 | TIS620 Thai | tis620_thai_ci | 1 |
|euckr | EUC-KR Korean | euckr_korean_ci | 2 |
|koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 |
|gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 |
|greek | ISO 8859-7 Greek | greek_general_ci | 1 |
|cp1250 | Windows Central European | cp1250_general_ci | 1 |
|gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 |
|latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 |
|armscii8| ARMSCII-8 Armenian | armscii8_general_ci | 1 |
|utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
|ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
|cp866 | DOS Russian | cp866_general_ci | 1 |
|keybcs2| DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 |
|macce | Mac Central European | macce_general_ci | 1 |
|macroman| Mac West European | macroman_general_ci | 1 |
|cp852 | DOS Central European | cp852_general_ci | 1 |
|latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 |
|utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 |
|cp1251 | Windows Cyrillic | cp1251_general_ci | 1 |
|utf16 | UTF-16 Unicode | utf16_general_ci | 4 |
|utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 |
|cp1256 | Windows Arabic | cp1256_general_ci | 1 |
|cp1257 | Windows Baltic | cp1257_general_ci | 1 |
|utf32 | UTF-32 Unicode | utf32_general_ci | 4 |
|binary | Binary pseudo charset | binary | 1 |
|geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 |
|cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 |
|eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 |
|gb18030 | China National Standard GB18030 | gb18030_chinese_ci | 4 |
1.2、字符编码
- 字符编码:字符编码是将字符映射为特定的字节或者字节序列,不过一般是特定的字符集采用特定的编码方式
字符编码查询sql:
#方法一:直接show collation
SHOW COLLATION;
#方法二:查询information_schema的collations
SELECT * FROM information_schema.collations;查询一下字符编码,如下是5.7.22版本的,有222条记录:
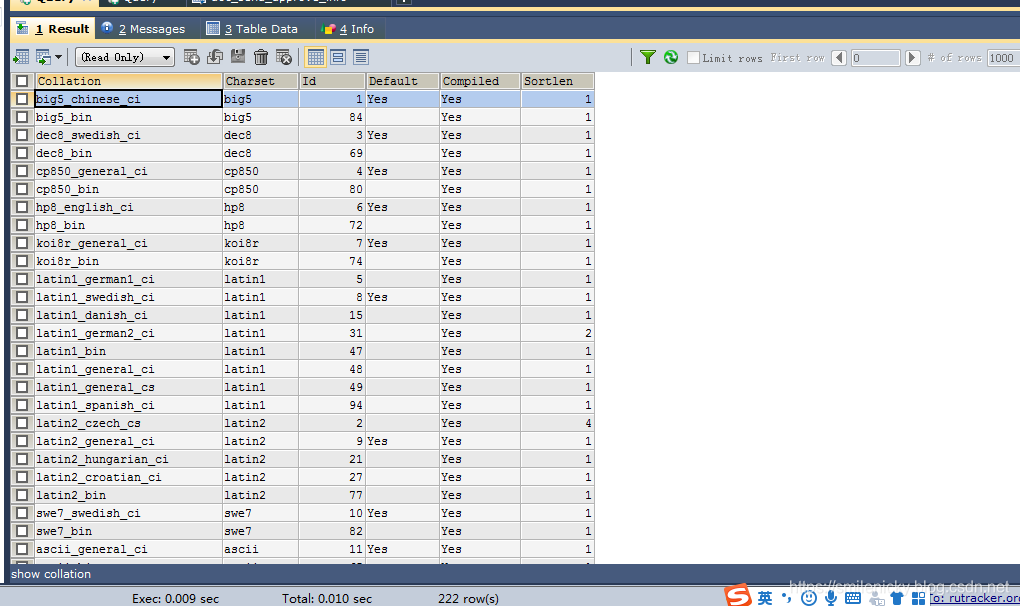
注意:MySQL的字符集设置不进可以设置整一张表,也可以细到具体的每个字段上,用法是在建表或者修改字段时候加上
charset [字符集名称]
二、字符集排序规则
2.1、排序规则定义
排序规则(Collation):排序规则是指对字符集下字符的比较规则。
2.2 、排序规则特征
排序规则特征:
- 每个字符集都有一个默认的排序规则
- 一个字符集对应一个排序规则,两个不同字符集不能有相同的排序规则
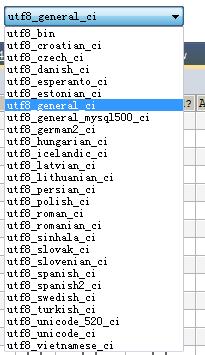
注意:排序规则常用的命名规范有:以_ci结尾的表示大小写不敏感(case insensitive),以_cs结尾的表示大小写敏感(case sensitive),以_bin结尾的表示二进制的比较(binary)
如图,选择一下collation,5.7.22版本的,大部分都是以ci结尾的,也就是大小写不敏感
例子:
# 建表,字符编码默认是utf8_general_ci
CREATE TABLE t (
a VARCHAR(10)
)CHARSET = utf8;
# 写入两条数据
INSERT INTO t SELECT 'a';
INSERT INTO t SELECT 'A';
# 查出两条数据,说明大小写不敏感
SELECT * FROM t WHERE a='a';
# 唯一索引也是不可以建的
ALTER TABLE t ADD UNIQUE KEY (a);# 修改一下字符编码
ALTER TABLE t MODIFY COLUMN a VARCHAR(10) COLLATE utf8_bin;
# 查出一条数据,说明大小写敏感
SELECT * FROM t WHERE a = 'a';
# 这种情况 唯一索引是可以建的
ALTER TABLE t ADD UNIQUE KEY (a);三、CHAR和VARCHAR
char和varchar是两种最常见的字符串类型,其语法分别是char(N)和varchar(N),注意其中N在MySQL4.1版本后都表示字符的长度,而非字节长度,在MySQL4.1之前版本才表示字节的长度
3.1、CHAR类型
对于CHAR(N),N的范围为0~255
CHAR(N)是来保存固定长度的字符串,也是根据设置的值N,假如N设置为10,不管你传什么范围内的字符串,都是固定长度为10的,因为数据库为存储列的右边进行填充(Right padded),而在读取时候数据库又会自动将填充的字符删除.除非设置SQL_MODE属性PAD_CHAR_TO_FULL_LENGTH,才可以正常显示
例子实践:
# 建表实践
CREATE TABLE t (a CHAR(10));
# 写入数据
INSERT INTO t SELECT 'abcd';
# 查询
SELECT a, HEX(a), LENGTH(a), CHAR_LENGTH(a) FROM t;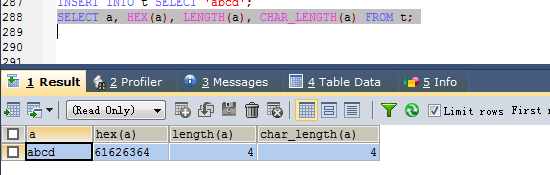
# 查询全局SQL_MODE
SELECT @@global.sql_mode;
# 查询会话SQL_MODE
SELECT @@session.sql_mode;
# 设置SQL_MODE属性
SET SQL_MODE = 'PAD_CHAR_TO_FULL_LENGTH';
# 再次查询
SELECT a, HEX(a), LENGTH(a), CHAR_LENGTH(a) FROM t;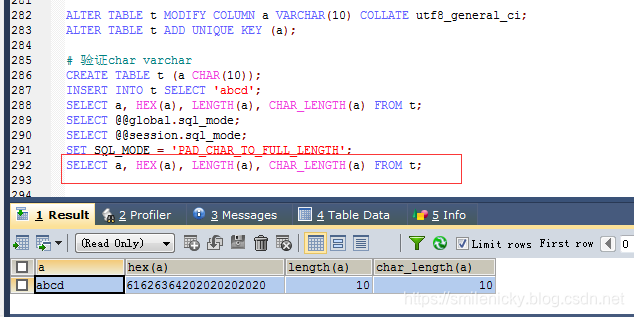
3.2、VARCHAR类型
对于varchar类型是存储可变长字符串的,意思就是varchar(10)的列,我写字符串“abcd“,该列存储的4个字符,而char(10)的列才会存储10个字符
四、BINARY和VARBINARY
4.1、特性对比
BINARY(N)和VARBINARY(N)与前面介绍的CHAR(N)和VARCHAR(N)类型有点类似,BINARY可类比CHAR,VARBINARY可以类比VARCHAR类型。
对比:
- 不同的是BINARY和VARBINARY存储的都是二进制类型的字符串,CHAR和VARCHAR存储的才是字符类型的字符串
- BINARY和VARBINARY没有字符集的概念,CHAR和VARCHAR这些才有字符集的概念
- BINARY(N)和VARBINARY(N)中的N表示的字节的长度,从前面我们知道CHAR(N)和VARCHAR(N)中的N自从MySQL4.1之后,就表示字符的长度
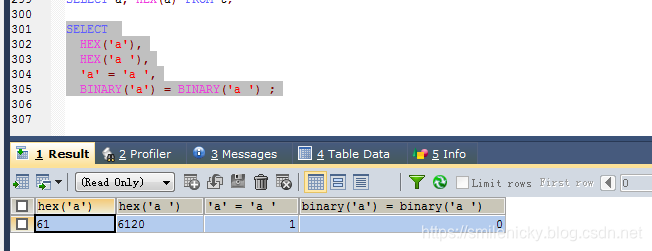
- CHAR和VARCHAR进行字符比较时,是比较本身存储的字符,忽略填充的字符的,而BINARY和VARBINARY是不忽略的,比较的是二进制值的
4.2、例子实践
SELECT
HEX('a'),
HEX('a '),
'a' = 'a ',
BINARY('a') = BINARY('a ') ;
五、BLOB和TEXT
可以将blob类型的列视为足够大的varbinary类型的列,也可以将text类型的列视为足够大的varchar类型的列
5.1、text类型
TEXT 是用来存储字符大数据类型的,TEXT类型和blob类型一样,可以细分为:
- tinytext(2^8)
- text(2^16)
- mediumtext(2^24)
longtext(2^32)
5.2、blob类型
BLOB(Binary Large Object)是用来存储二进制大数据类型的。根据存储长度的不同,blob类型可以细分为:- tinyblob(2^8)
- blob(2^16)
- mediumblob(2^24)
longblob(2^32)
5.3、排序问题
blob和text排序问题:
注意: BLOB和TEXT排序时只使用列的前max_sort_length个字节
SET GLOBAL max_sort_length =1024;
SELECT @@global.max_sort_length;5.4、索引问题
blob和text加索引问题:
blob和text类型的列加索引时候,需要注意一些细节
- 1、对于列不能有默认值
- 2、加索引时需要指定索引前缀长度
CREATE INDEX indexName ON tablename(columnTest(1000)); 六、ENUM和SET类型
6.1、集合类型简介
enum和set类型都是集合类型,不同是enum最多枚举65536个元素,而set类型最多枚举64个元素
6.2、集合类型例子
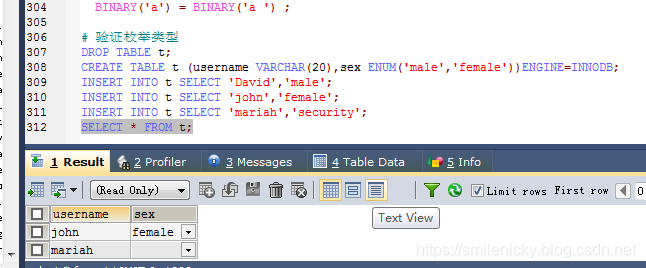
# 创建表验证问题
CREATE TABLE t (username VARCHAR(20),sex ENUM('male','female'))ENGINE=INNODB;
# 正常写数据
INSERT INTO t SELECT 'David','male';
INSERT INTO t SELECT 'john','female';
# 写数据,因为没有对应枚举类型,不过还是可以写入,不是警告而已
INSERT INTO t SELECT 'mariah','security';
# 查询出来,发现sex字段没值
select * from t ;
# 设置严格模式的
SET SQL_MODE = 'strict_trans_tables';
# 再次写数据,发现不可以写
INSERT INTO t SELECT 'mariah','security';
# 再次查询没有写成功
SELECT * FROM t;